Author: https://github.com/meituan-search
Last updated: 07/17/2025.
The current reinforcement learning training process implemented by verl is synchronous, adhering to the algorithmic workflows of established methods like PPO, GRPO, and DAPO. In each step, training samples are generated by the latest model, and the model is updated after training completes. While this approach aligns with off-policy reinforcement learning and stabilizes RL training, but it suffers from severe efficiency issues. Model updates must wait for the longest output in the generation phase to complete. During the generation of long-tail samples, GPUs remain idle, resulting in significant underutilization. The more severe the long-tail problem in sample generation, the lower the overall training efficiency. For example, in DAPO 32B training, the Rollout phase accounts for approximately 70% of the total time, and increasing resources does not reduce the Rollout duration.
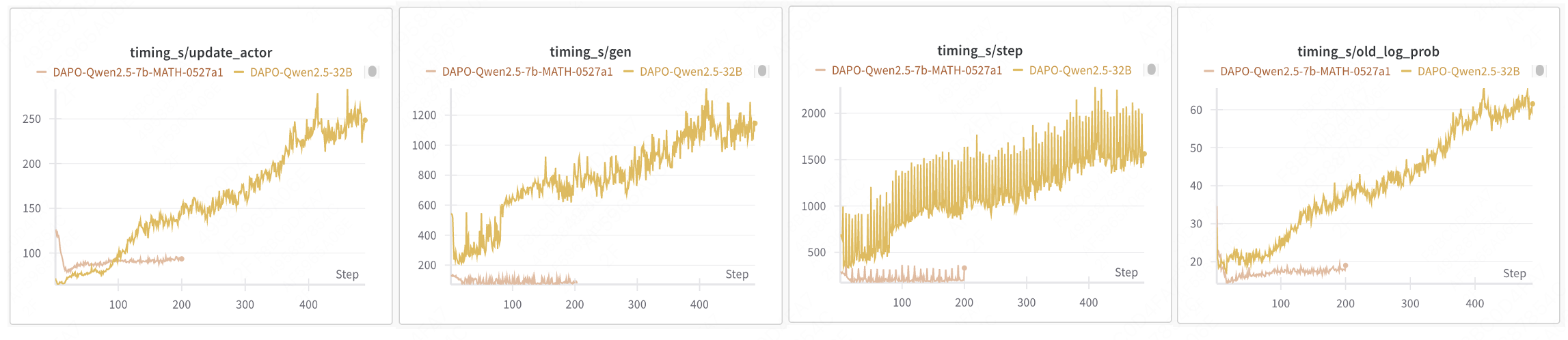
source data: https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=nwusertongyuxuan361
We have implemented the One Step Off Async Trainer to help alleviate this issue. This approach parallelizes the generation and training processes, utilizing samples generated in the previous step for current training. It also involves appropriately partitioning resources, allocating dedicated resources for generation while automatically assigning the remainder to training. By reducing resources allocated to the generation phase, we mitigate GPU idle time during long-tail sample generation. Throughout this process, generation and training parameters maintain a one-step off policy.

reference: AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning original work: Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models
Our core contributions include:
-
Parallel Generation and Training: Samples for the next batch are asynchronously generated while the current batch is being trained.
-
Resource Isolation: Unlike
hybrid_engine, this method requires explicit resource allocation for rollout, with remaining resources automatically assigned to training. -
NCCL Parameter Synchronization: Employs NCCL communication primitives for seamless parameter transfer between generation and training modules.
- Machine Configuration: 2 nodes with 16 H20 GPUs each
- Generation: 4 GPUs
- Training: 12 GPUs
- Model: Qwen2.5-Math-7B
- Rollout Configuration:
- Max Response Length: FSDP2: 20,480 tokens; Megatron: 8,192 tokens
- Algorithm: DAPO
- Rollout Engine: vLLM
| training mode | engine | step | gen | wait_prev_gen | generate_sequences | old_log_prob | update_actor | total time | acc/best@32/mean | acc/maj@32/mean |
|---|---|---|---|---|---|---|---|---|---|---|
| colocate sync | VLLM+FSDP2 | 749 | 321 | - | 247 | 88 | 286 | 19h18m | 0.5948 | 0.417 |
| one-step-overlap async | VLLM+FSDP2 | 520 | - | 45 | 458 | 108 | 337 | 15h34m(+23%) | 0.6165 | 0.494 |
| colocate sync | VLLM+Megatron | 699 | 207 | - | 162 | 119 | 344 | 18h21m | 0.605 | 0.4217 |
| one-step-overlap async | VLLM+Megatron | 566 | - | 59 | 501 | 120 | 347 | 13h06m (+40%) | 0.6569 | 0.4038 |
- colocate sync: step ≈ gen + old_log_prob + update_actor
- one-step-overlap async: step ≈ wait_prev_gen + old_log_prob + update_actor
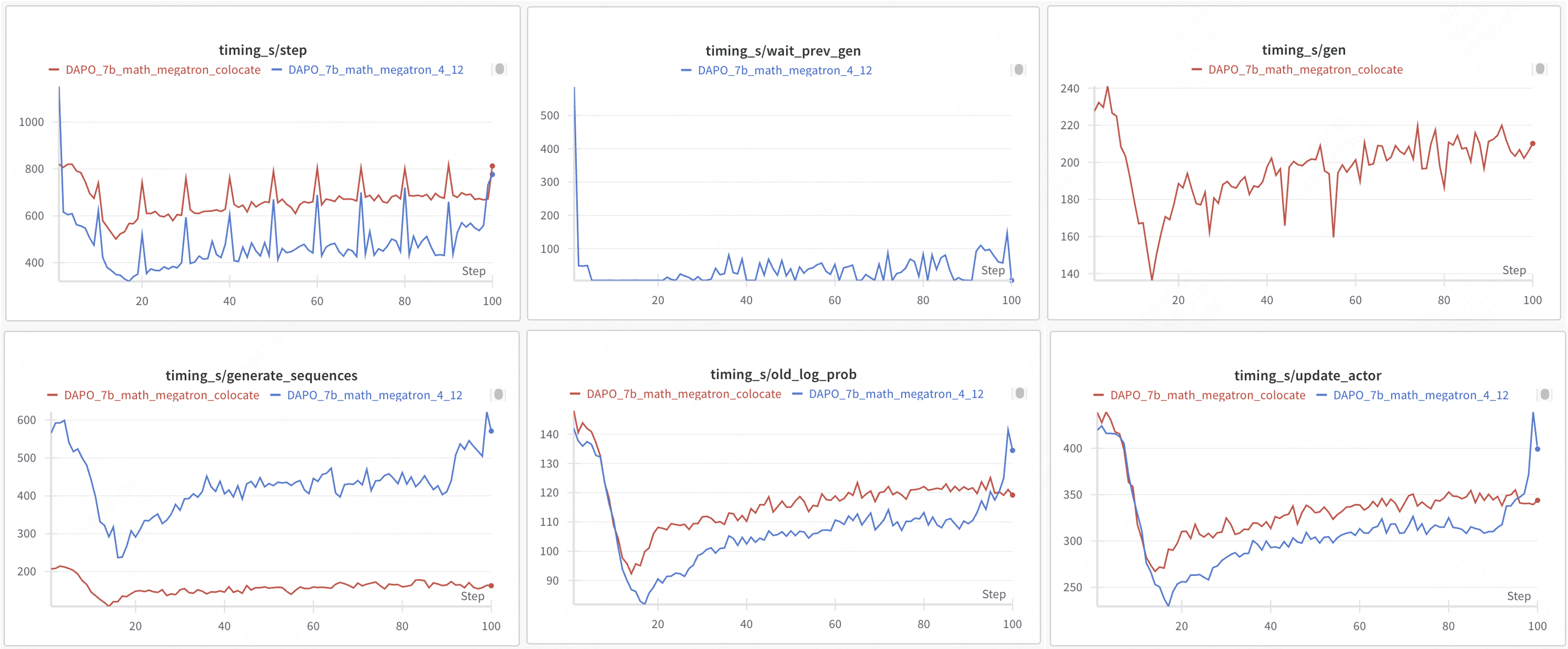
source data: https://wandb.ai/hou-zg-meituan/one-step-off-policy?nw=nwuserhouzg
Our implemented One Step Off Policy Async Pipeline integrates seamlessly into existing training logic at minimal
cost,
eliminating the need for additional sample storage management. The core mechanism uses async_gen_next_batch
for asynchronous rollout generation while maintaining continuous operation during epoch transitions
via create_continuous_iterator.
# iterator generator, simplify one-step integration of the training process
def _create_continuous_iterator(self):
for epoch in range(self.config.trainer.total_epochs):
iterator = iter(self.train_dataloader)
for batch_dict in iterator:
yield epoch, batch_dict
# read next batch samples, parameters sync and launch asyn gen_seq
def _async_gen_next_batch(self, continuous_iterator):
# read train_data
try:
epoch, batch_dict = next(continuous_iterator)
except StopIteration:
return None
batch = DataProto.from_single_dict(batch_dict)
gen_batch = batch_pocess(batch)
# sync weights from actor to rollout
self.sync_rollout_weights()
# async generation
gen_batch_output = self.rollout_wg.async_generate_sequences(gen_batch)
# future encapsulated
return GenerationBatchFuture(epoch, batch, gen_batch_output)
continuous_iterator = self._create_continuous_iterator()
# run rollout first to achieve one-step-off
batch_data_future = self._async_gen_next_batch(continuous_iterator)
while batch_data_future is not None:
# wait for the gen_seq result from the previous step
batch = batch_data_future.get()
# launch the next async call to generate sequences
batch_data_future = self._async_gen_next_batch(continuous_iterator)
# compute advantages
batch = critic.compute_values(batch)
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch)
batch = compute_advantages(batch)
# model update
critic_metrics = critic.update_critic(batch)
actor_metrics = actor.update_actor(batch)The exciting point is that our nccl based weights updating for rollout model has great performance. At most of time, the latency is under 300ms, which is negligible for RLHF.
sync_rollout_weights:The time for synchronizing parameters from actor to rollout is extremely fast and can almost be ignored because it is implemented with nccl.
class ActorRolloutRefWorker:
# actor acquires the meta-info of model parameters for parameter sync
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def get_actor_weights_info(self):
params = self._get_actor_params()
ret = []
for key, tensor in params.items():
ret.append((key, tensor.size(), tensor.dtype))
self._weights_info = ret
return ret
# rollout sets the meta-info of model parameters for parameter sync
@register(dispatch_mode=Dispatch.ONE_TO_ALL)
def set_actor_weights_info(self, weights_info):
self._weights_info = weights_info
class AsyncRayPPOTrainer(RayPPOTrainer):
def init_workers(self):
...
# rollout obtains the meta-info of model parameters from the actor for parameter sync
weights_info = self.actor_wg.get_actor_weights_info()[0]
self.rollout_wg.set_actor_weights_info(weights_info)
# Create an actor-rollout communication group for parameter sync
actor_rollout_workers = self.actor_wg.workers + self.rollout_wg.workers
collective.create_collective_group(
actor_rollout_workers,
len(actor_rollout_workers),
list(range(0, len(actor_rollout_workers))),
backend="nccl",
group_name="actor_rollout"
)# drive process call the actor and rollout respectively to sync parameters by nccl
def sync_rollout_weights(self):
self.actor_wg.sync_rollout_weights()
ray.get(self.rollout_wg.sync_rollout_weights())
# fsdp model parameter sync
@register(dispatch_mode=Dispatch.ONE_TO_ALL, blocking=False)
def sync_rollout_weights(self):
params = self._get_actor_params() if self._is_actor else None
if self._is_rollout:
inference_model = (
self.rollout.inference_engine.llm_engine.model_executor.driver_worker.worker.model_runner.model
)
from verl.utils.vllm.patch import patch_vllm_moe_model_weight_loader
patch_vllm_moe_model_weight_loader(inference_model)
# Model parameters are broadcast tensor-by-tensor from actor to rollout
for key, shape, dtype in self._weights_info:
tensor = torch.empty(shape, dtype=dtype, device=get_torch_device().current_device())
if self._is_actor:
assert key in params
origin_data = params[key]
if hasattr(origin_data, "full_tensor"):
origin_data = origin_data.full_tensor()
if torch.distributed.get_rank() == 0:
tensor.copy_(origin_data)
from ray.util.collective import collective
collective.broadcast(tensor, src_rank=0, group_name="actor_rollout")
if self._is_rollout:
inference_model.load_weights([(key, tensor)])To ensure the correctness of the PPO algorithm, we use rollout log_probs for PPO importance sampling.
For the related algorithm details, please refer to: https://verl.readthedocs.io/en/latest/algo/rollout_corr_math.html
The default mode is bypass_ppo_clip, but other modification strategies can also be explored.
In the current implementation, we no longer provide SPMD model rollout mode. Instead, we have switched to AgentLoop mode, which also supports multi-turn tool calling.
python3 -m verl.experimental.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_trainer.yaml' \
actor_rollout_ref.actor.strategy=fsdp2 \
# actor and rollout are placed separately
actor_rollout_ref.hybrid_engine=False \
# actor and rollout resource
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2python3 -m verl.experimental.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_megatron_trainer.yaml' \
actor_rollout_ref.actor.strategy=megatron \
# actor and rollout are placed separately
actor_rollout_ref.hybrid_engine=False \
# actor and rollout resource
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2-
Card Number Relationships Maintain either of these relationships for optimal batch distribution:
actor_rollout_ref.rollout.nshould be an integer divisor of:trainer.n_gpus_per_node * trainer.nnodesactor_rollout_ref.rollout.n * data.train_batch_sizeshould be evenly divisible by:trainer.n_gpus_per_node * trainer.nnodes
Rationale: Ensures training samples can be evenly distributed across training GPUs when using partial resources for generation.
-
Dynamic Resource Tuning Adjust
trainer.nnodestrainer.n_gpus_per_noderollout.nnodesrollout.n_gpus_per_nodebased on phase durations:- Ideal state: Rollout and training phases have comparable durations
- Diagnostic metrics:
- Monitor
wait_prev_genduration - Analyze
sequence_lengthdistribution
- Monitor
- Adjustment strategy: - High
wait_prev_gen+ uniform sequence lengths → Increase rollout resources - Highwait_prev_gen+ long-tail sequences → Optimize stopping criteria (resource increase won't help)wait_prev_gen:The time consumed waiting for the previous rollout to end (the part that is not fully overlapped). Resource Configuration Strategies:
- Resource-constrained scenario: Optimize resource utilization by adjusting GPU allocation ratios,
keeping the number of nodes equal to allow training and rollout to share nodes;
- Configure
trainer.nnodes = rollout.nnodeswithtrainer.n_gpus_per_node + rollout.n_gpus_per_node = physical_gpus_per_node. Control rollout resource allocation by adjustingn_gpus_per_node.
- Configure
- Resource-abundant scenario: Optimize performance by adjusting the number of nodes,
keeping the number of GPUs per node equal to enable independent scaling of training and rollout
parallelism. - Configure
trainer.n_gpus_per_node = rollout.n_gpus_per_nodeand control rollout resource allocation by adjustingtrainer.nnodesandrollout.nnodesto achieve optimal performance.Note: The total number of nodes required by the system is not simply
trainer.nnodes + rollout.nnodes. The actual calculation depends on GPU capacity:- When
trainer.n_gpus_per_node + rollout.n_gpus_per_node <= physical_gpus_per_node, the required node count ismax(trainer.nnodes, rollout.nnodes) - When
trainer.n_gpus_per_node + rollout.n_gpus_per_node > physical_gpus_per_node, the required node count istrainer.nnodes + rollout.nnodes
- When
| Category | Support Situation |
|---|---|
| train engine | FSDP2 Megatron |
| rollout engine | vLLM SGLang |
| AdvantageEstimator | GRPO GRPO_PASSK REINFORCE_PLUS_PLUS RLOO OPO REINFORCE_PLUS_PLUS_BASELINE GPG |
| Reward | all |