Architecture
Kafka Connect has three major models in its design:
-
Connector model: A connector is defined by specifying a
Connectorclass and configuration options to control what data is copied and how to format it. EachConnectorinstance is responsible for defining and updating a set ofTasksthat actually copy the data. Kafka Connect manages theTasks; theConnectoris only responsible for generating the set ofTasksand indicating to the framework when they need to be updated. -
Worker model: A Kafka Connect cluster consists of a set of
Workerprocesses that are containers that executeConnectorsandTasks.Workersautomatically coordinate with each other to distribute work and provide scalability and fault tolerance. TheWorkerswill distribute work among any available processes, but are not responsible for management of the processes; any process management strategy can be used forWorkers(e.g. cluster management tools like YARN). -
Data model: Connectors copy streams of messages from a partitioned input stream to a partitioned output stream, where at least one of the input or output is always Kafka. Each of these streams is an ordered set messages where each message has an associated offset. The format and semantics of these offsets are defined by the Connector to support integration with a wide variety of systems; however, to achieve certain delivery semantics in the face of faults requires that offsets are unique within a tream and strams can seek to arbitrary offsets. The message contents are represented by
Connectorsin a serialization-agnostic format, and Kafka Connect supports pluggableConvertersfor storing this data in a variety of serialization formats. Schemas are build-in, allowing important metadata about the format of messages to be propagated through complex data pipelines. However, schema-free data can also be used when a schema is simply unavailable.
The connector models addresses three key user requirements. First, Kafka Connect performs broad copying by default by having users define jobs at the level of Connectors which then break the job into smaller Tasks. This two level scheme strongly encourages connectors to use configurations that encourage copying broad swaths of data since they should have enough inputs to break the job into smaller tasks. It also provides one point of parallelism by requiring Connectors to immediately consider how their job bcan be broken down into subtasks, and select an appropriate granularity to do so. Finally, by specializing source and sink interfaces, Kafka Connect provides an accessible connector API that makes it very easy to implement connectors for a variety of systems.
The worker model allows Kafka Connect to scale to the application. It can run scaled down to a single worker process that also acts as its own coordinator, or in clustered mode where connectors and tasks are dynamically scheduled on workers. However, it assumes very little about the process management of the workers, so it can easily run on a variety of cluster managers or using traditional service supervision. This architecture allows scaling up and down, but Kafka Connect’s implementation also adds utilities to support both modes well. The REST interface for managing and monitoring jobs makes it easy to run Kafka Connect as an organization-wide service that runs jobs for many users. Command line utilities specialized for ad hoc jobs make it easy to get up and running in a development environment, for testing, or in production environments where an agent-based approach is required.
The data model addresses the remaining requirements. Many of the benefits come from coupling tightly with Kafka. Kafka serves as a natural buffer for both streaming and batch systems, removing much of the burden of managing data and ensuring delivery from connector developers. Additionally, by always requiring Kafka as one of the endpoints, the larger data pipeline can leverage the many tools that integrate well with Kafka. This allows Kafka Connect to focus only on copying data because a variety of stream processing tools are available to further process the data, which keeps Kafka Connect simple, both conceptually and in its implementation. This differs greatly from other systems where ETL must occur before hitting a sink. In contrast, Kafka Connect can bookend an ETL process, leaving any transformation to tools specifically designed for that purpose. Finally, Kafka includes partitions in its core abstraction, providing another point of parallelism.
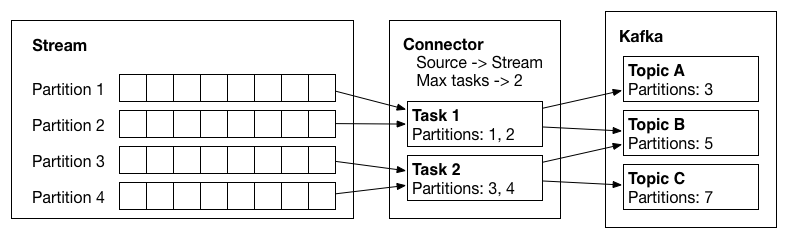
Logical view of an input stream, a source connector, the tasks it creates, and the data flow from the source system into Kafka.
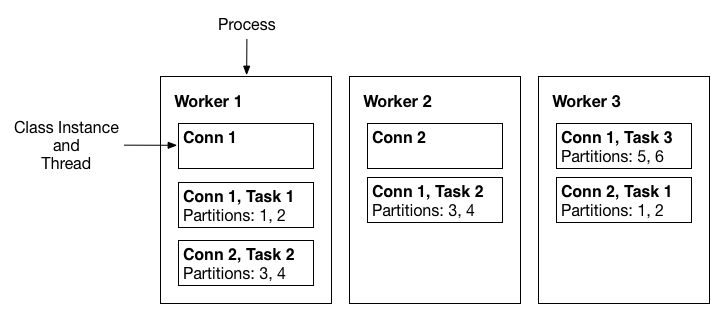
A three-node Kafka Connect distributed mode cluster. Connectors (monitoring the source or sink system for changes that require reconfiguring tasks) and tasks (copying a subset of a connector’s data) are automatically balanced across the active workers. The division of work between tasks is shown by the partitions that each task is assigned.