My bachelor's thesis -- Visual Storytelling -- an encoder-decoder model consisting of both convolutional and attentional recurrent networks that transform a sequence of 5 images into a context-generative story in natural language (english).

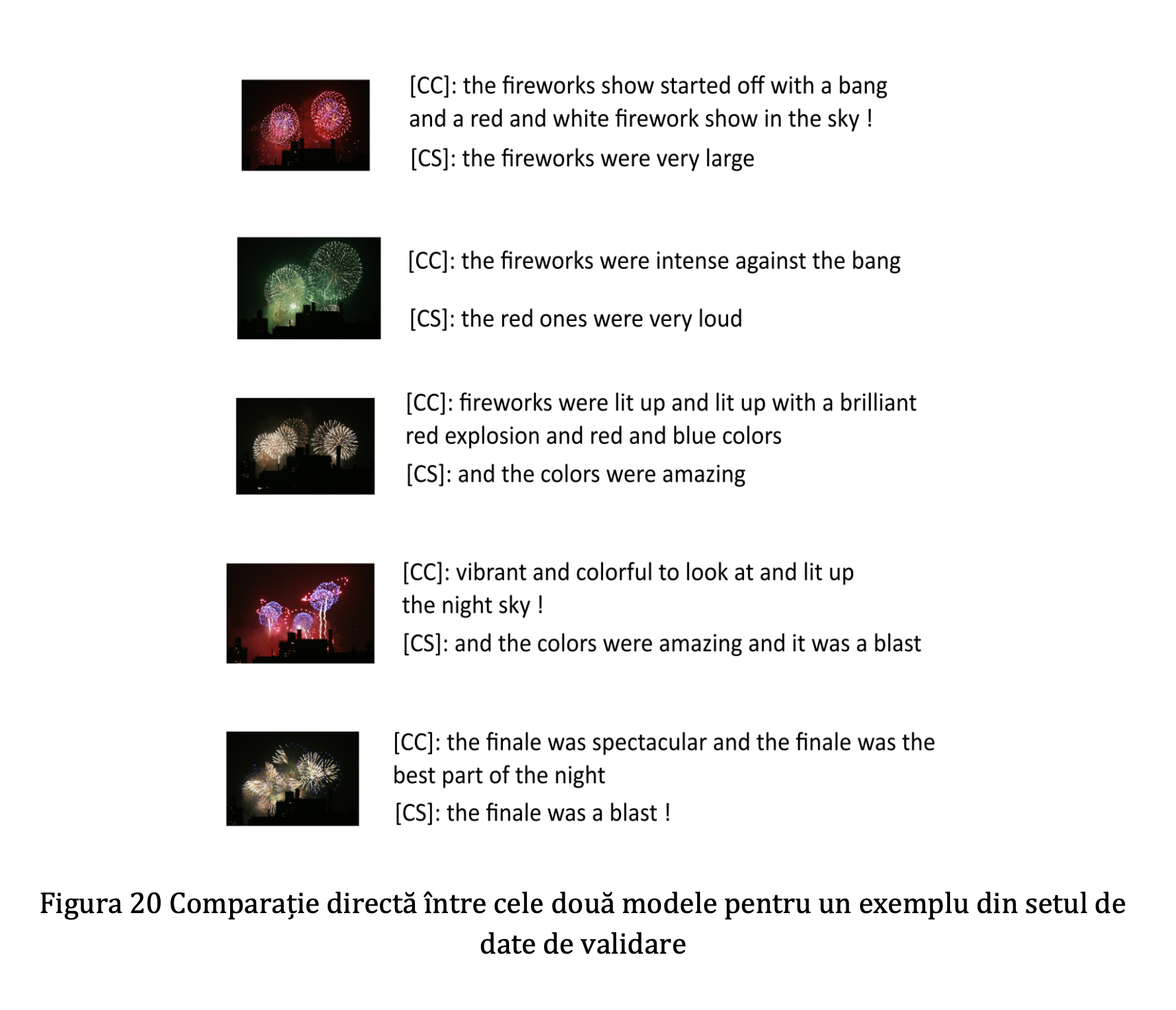
From the above-illustrated architecture, two models were trained and compared:
- Encoding the whole album's into one embedding vector (CS)
- Encoding each photo separately to its own embedding vector and transmitting them to the decoder sequentially (CC)