Welcome to the workshop in which will delve into basics of Convolutional Neural Networks via a case-study of a Sign Lanaguage Alphabet Recognition in Keras. We will first introduce a state-of-art Convolutional Neural Network architecture - VGG-16 - and break it down to its smallest building blocks. After this workshop you will be familiar with the basic Neural Network terminology and you will build an understanding how they can be utilized. For those interested in pursuing further their adventure with Convolutional Neural Nets there is a suggested reading list provided at the end as well.
It's a deep learning algorithm, that takes an image as an input, extracts features from it, assignes weights and biases to various aspects of the image to be able at the end to classify the image and assign a label to the input. The following problems can be solved using CNNs:
Image classification:

Semantic Segmentation:

Object Localization:

There are different ways of reach the same goal. Various CNN Architectures came to exsistence as alternative approaches to similar problem types. Each architecture aims at improving the previous design with respect to factors such as minimization of false positive rate, improving the accuracy of the model, decreasing the computational power required to train the model ect. A CNN has basic building blocks such as Convolutional Layers, Activation Functions, Pooling Layers, Fully Connected Layers and many more which can be re-arranged in multiple ways. The ways in which those blocks are re-arranged are so called the CNN architectures.
There are many CNN Architectures that researchers came up with such as AlexNet, ResNet or VGG-16. The VGG-16 is an architecture that is easy to understand and illustrates well the main building blocks of a CNN network. The Convolutional Neural Networks VGG-16 architecture consists of two main building blocks. The task of the first block colored in yellow is to extract the high level features from the images and the second block colored in blue aims at classifying which of the given labels can be attributed to a specific image.

The first step is to feed input image into the Convolutional Network, which is an RGB email 224 pixels by 224 pixels

Next, there are two Convolutional layers, which perform a convolution operation on the input image. The convolution operation is a dot product between the input image and The kernel and produces the Feature space as a result. The kernel is a 3 x 3 matrix, which by "sliding" through the input image detects features of the input such as horizontal or vertical edges. The kernel is said to have a 0-padding, which is a padding added to the input to ensure that the output after convolution operation has the same dimentions as the input. The convolution has a depth of 64 (meaning that there are 64 different kernels applied, each detecting a different feature). After each Convolution a ReLU activation function is applied, which is placed in order to introduce non-linearity to the model. Non-linearity is important, as if we are solving a non-linear problem, the convolution operation is linear and rectification with ReLU is a way to break that linearity further. Without ReLU no matter how many hidden layers we would have added the model would behave like a single layer perceptron.

Animated convolution operation:
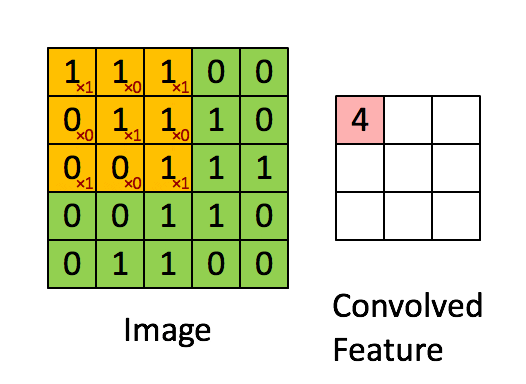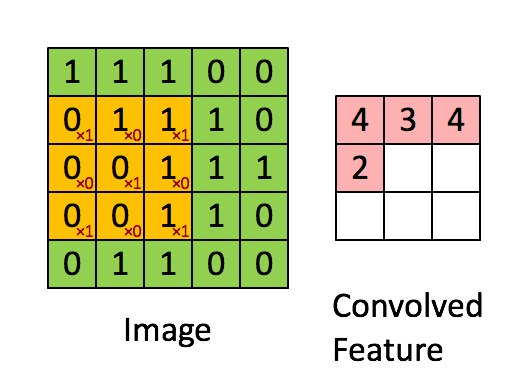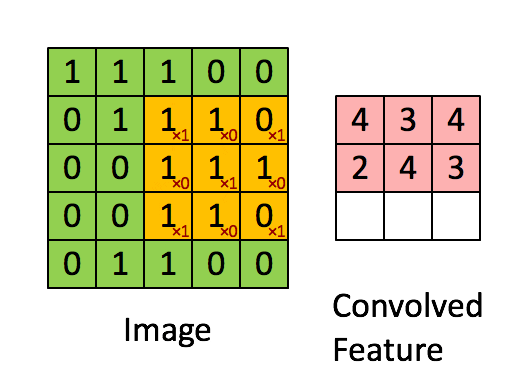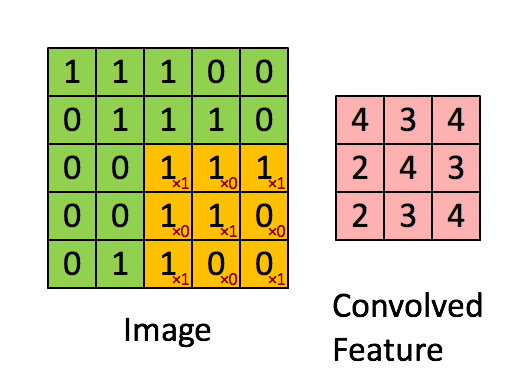
Here is an illustration of how the input image changes after the ReLU function is applied (all black pixels are turned gray)


The next step is max pooling, with a window size 2 x 2, which means that from 2 x 2 region we chose the highest value and we re-write it to produce new layer of smaller dimentions 112 x 112.

Once again we perform convolution twice with 0-padding added and with the kernel depth 128.

We perform Max Pooling and reduce the dimentions to 56 x 56

Next, three convolutions are performed with the kernel depth of 256

We perform Max Pooling and reduce the dimentions to 28 x 28

Next, three convolutions are performed with the kernel depth of 512

We perform Max Pooling and reduce the dimentions to 14 x 14

Next, three convolutions are performed with the kernel depth of 512

Next, we perform Max pooling again and reduce the size to 7 x 7 and afterwards flatten the data in order to be able to feedit to the Fully Connected Layers. From this step on we entered the classification part of the VGG-16 model and we are no longer extracting the features from the input image.

After flattening we optain three Layers, that are known as Fully Connected Layers, as each element in the network is connected to each element in the next layer. Using Backpropagation the model adjusts the weights. In order to adjust the weights and biases of our model the predicted value is compared to the actual output value (the loss function is used to calculate the error value). The derrivative of the error value with respect to every weight in a layer and then layer by layer adjust the weights using derrivatives. They are optimization methods that adjust the weights and biases of the model in a way that enables us to produce output that comes out in the form of logits. Logits are unnormalized predictions of the model.

In the last step the logits values are normalized and with help of the Softmax function they are adjusted and turned into probabilities. The output of the model are the probabilities for each label.

Model constructed and trained is ready for assesment. Some of the common terminology used for model assesment are the following:
top-5 error is a way to say that among the top 5 label percentages we have the correct value
Confusion matrix which showes how many times did the model output true values and how many false positives did it output
Accuracy ratio of correctly predicted observation to the total observations
precision ratio of correctly predicted positive observations to the total predicted positive observations
recall ratio of correctly predicted positive observations to the all observations in actual class
F1 score F1 Score = 2*(Recall * Precision) / (Recall + Precision)
- Get the training data
DATASET: https://www.kaggle.com/kuzivakwashe/significant-asl-sign-language-alphabet-dataset
-
Organize the data in the folder
-
Resize the data
-
One hot encode the categories of the dat a
-
Save images as numpy arrays
-
Normalizing the data
-
Train-Test split the data
-
Reshaping the numpy arrays
The VGG16 architecture consists of twelve convolutional layers, some of which are followed by maximum pooling layers and then four fully-connected layers and finally a 1000-way softmax classifier.
- Setting up the Keras implementation
#_______ VGG ________
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.convolutional import Conv2D
from keras.layers import Convolution2D as Conv2D
from keras.layers import Conv2D
from keras.layers.convolutional import Deconv2D as Conv2DTranspose
from tensorflow.keras import backend as k
from tensorflow.keras.models import load_model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.python.keras.layers import Flatten, Dense
model = Sequential()
# Conv Block 1
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=X_train.shape[1:], name='block1_conv1', data_format='channels_last'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Conv Block 2
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Conv Block 3
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Conv Block 4
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Conv Block 5
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# FC layers
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dense(4096, activation='relu'))
model.add(Dense(1000, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3)
#______ TIME TO CAPTURE DATA _____
import cv2
cam = cv2.VideoCapture(0)
cv2.namedWindow("test")
img_counter = 0
while True:
ret, frame = cam.read()
cv2.imshow("test", frame)
if not ret:
break
k = cv2.waitKey(1)
if k%256 == 27:
# ESC pressed
print("Escape hit, closing...")
break
elif k%256 == 32:
# SPACE pressed
img_name = "Desktop/Code/ImageRecognition/datacapture/opencv_frame_{}.png".format(img_counter)
cv2.imwrite(img_name, frame)
print("{} written!".format(img_name))
img_counter += 1
cam.release()
cv2.destroyAllWindows()
images=glob.glob("Desktop/Code/ImageRecognition/datacapture/*.png")
images_for_recognition = []
for image in images:
img = Image.open(image)
images_for_recognition.append(img)
display(img)
#___MAKING THE PREDICTION ON THE CAPTURED DATA _____
model_json_file = "/Users/ewa_anna_szyszka/Desktop/model.json"
model_weights_file = "/Users/ewa_anna_szyszka/Desktop/my_model.h5"
'''Setting up the '''
for i in images_for_recognition:
new_array = cv2.resize(np.array(i), (50, 50))
new_array = new_array.reshape(1,50,50,3)
a = SignLanguageModel(model_json_file, model_weights_file)
print(a.predict_letter(new_array))

http://colah.github.io/posts/2014-07-Conv-Nets-Modular/ http://cs231n.github.io/ https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ https://hackernoon.com/learning-keras-by-implementing-vgg16-from-scratch-d036733f2d5
I am a Computer Science student at Minerva Schools at KGI and Electronics Engineering student at AGH. This workshop is based on my Bachelor's Thesis Proposal. If you are interested delving further into the topic and exploring it further feel free to reach out ([email protected]).