1. Introdução
2. Introdução ao C# e .Net
3. Github
4. Lógica de programação
5. Tipos de dados
6. Funções
7. Orientação a objetos (OOP)
8. Listas
9. Programação assíncrona
10. Programação Web
11. Testes
12. SQL
13. Criando APIs com banco de dados relacional
14. Padrões e boas práticas de desenvolvimento de software
15. Tópicos avançados
16. Plano de aula
Para podermos entender como funciona um computador, temos que ter em mente que ele não é uma super máquina que tem consciencia própria e faz coisas sem precisar da intervenção humana, na verdade, um computador faz tarefas simples.
Um computador vê o mundo através de cálculos, tudo que ele executa segue um caminho específico, como numa linha de produção de uma fábrica. Se pedirmos para um computador fazer um cálculo simples, como (3+6)/2, ele executará vários passos para resolver essa equação, primeiro alguma parte fará a multiplicação, e o resultado será passado para uma outra parte para fazer a divisão, e assim por diante.
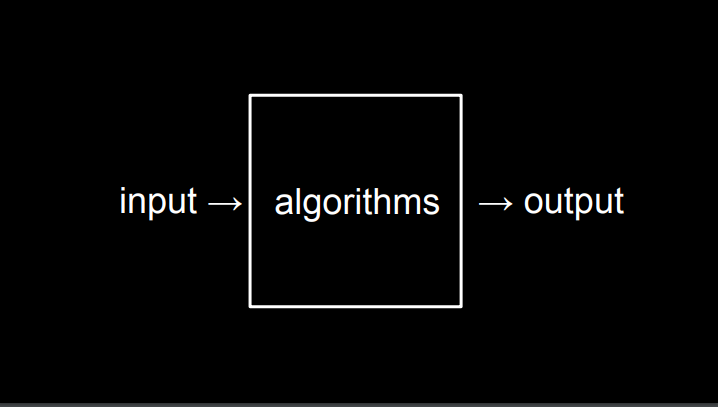
De fato, tudo o que um computador faz é computar, como uma calculadora, sempre há um input (entrada) e um output (saída). O nosso trabalho como desenvolvedores é desenvolver os algorítimos que usam essa entrada, e trabalham com ela de alguma maneira até que tenhamos o resultado desejado como saída.

Para que nós possamos nos entender melhor com as máquinas que vamos programar, precisamos entender o que é ciência da computação, é claro que não vamos cobrir tudo o que envolve ciência da computação no decorrer dos 3 meses deste curso, mas iremos ter uma noção básica de como as coisas funcionam.
Como este é o primeiro capítulo do curso, a primeira coisa que podemos fazer é contar quantos alunos temos na sala, e se contarmos nos dedos podemos representar cada aluno com um dedo levantado na minha mão, claro, que não conseguimos contar uma grande quantidade de pessoas dessa maneira, mesmo que eu usasse minha duas mãos, ainda só terei dez dedos. Esse tipo de operação tem um nome específico, ela é chamada de notação unária, por que para cada dedo levantado nas minhas mãos, eu atribuo uma única unidade de valor na contagem que estou fazendo.
Esse é um sistema bem universal, que todo mundo usa no dia a dia. Mas e quando eu preciso contar valores mais altos?
Claro que todo mundo sabe que podemos usar um sistema mais útil, que todo mundo aprendeu na escola, o sistema decimal.
Agora não atribuímos um valor a cada dedo levantado, mas sim, aprendemos que temos 10 digitos que podemos usar para representar qualquer número que quisermos, além do 0-9, também conseguimos representar
o 11, 12 e assim por diante, e é por trabalhar sempre com 10 possíveis dígitos [0-9] que ele é chamado de base 10.
Mas os computadores não aprenderam matemática com a gente na pré-escola. Eles não usam o sistema decimal para contar alguma coisa, de fato, eles usam um sistema muito mais simples, que para a gente pode parecer mais complexo e complicado, mas no final do dia, os computadores foram desenvolvidos por humanos, e são relativamente simples.
Então, qual a linguagem que os computadores usam?
Eles usam a linguagem binária, enquanto nós usamos de 0 à 9 na base 10 um computador usa de 0 à 1 na base 2.
Mas por que não usar também o sistema decimal como nós usamos normalmente? Por que as pessoas que inventaram os primeiros computadores tiveram que criar todo esse novo sistema binário que só usa dois dígitos?
Bom, o que os computadores precisam para funcionar? O que um computador aguarda antes de iniciar algum processo? Eletricidade! A única coisa que um computador, smartphone ou qualquer pedaço de tecnologia pra funcionar é de eletricidade, a única interação física de um computador com a gente é a eletricidade.
Por exemplo, todos temos uma lâmpada no quarto, que pode estar acessa. Mas ela pode ser apagada também, só precisamos apretar um botão, um switch.
E qual a relação dessa lâmpada, dessa ideia de que o fluxo de eletricidade pode acender ou apagar tem a ver com os computadores?
Nós, a partir de um impulso elétrico, podemos representar uma informação.
Zeros e Uns.
É por isso que no final das contas, tudo que um computador usa são impulsos elétricos como input. Quando queremos representar o dígito 1 precisamos de energia, quando não fornecemos energia, temos um 0.
Agora sabemos que quando a lâmpada está acessa, temos um 1 e quando ela está desligada, temos um 0, mas e quando precisamos contar além de um dígito?
Eu poderia, claro, usar mais de uma lâmpada! Se tivessemos mais de três lampadas, quantos dígitos poderíamos representar usando o sistema binário, ou seja, somente zeros e uns?
000 = 0
001 = 1
010 = 2
011 = 3
100 = 4
101 = 5
110 = 6
111 = 7
A resposta é 7!
Percebam que seguimos um padrão, que não foi por acaso, mas que é muito fácil de entender.
Se te mostrassem o número 123, como você o leria?
Claro, cento e vinte e três. Nós sabemos disso por que aprendemos no sistema decimal que em cada posição, temos um peso diferente para cara dígito, então os dígitos continuam indo somente de 0 à 9, porém assumem valores diferentes com base na posição em que se encontram.
No exemplo do 123 temos o seguinte:

A cada casa mais a esquerda multiplicamos em 10 vezes o valor da casa da direita e o resultado da multiplicação desse número pelo dígito decimal logo a baixo representa o valor que esse dígito está assumindo.
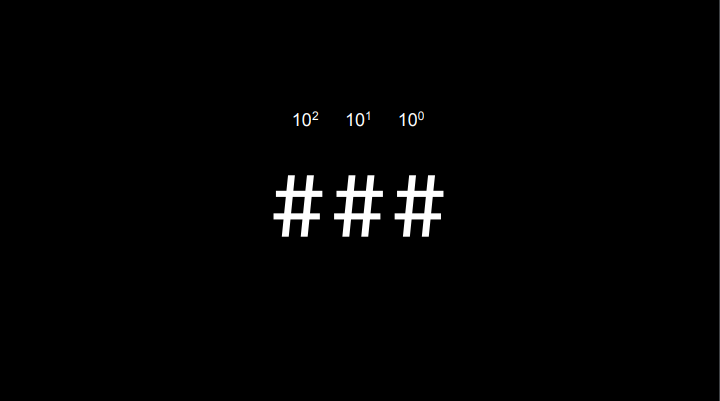
E no sistema binário temos a mesma situação, so que ao invés de usarmos a base 10, usamos a base 2.
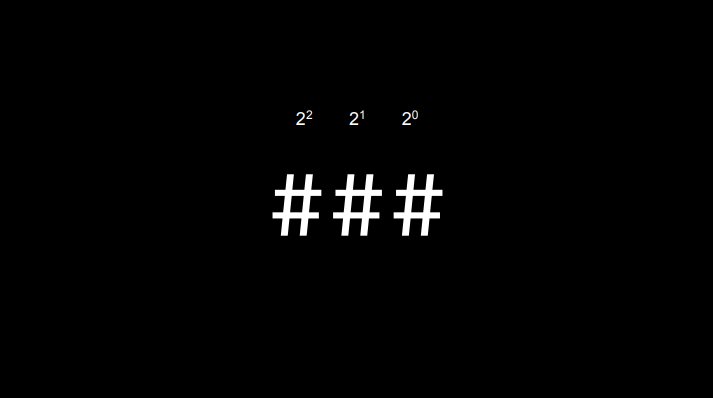
Tudo o que a gente viu até agora tem a ver com lâmpadas, mas de onde vem esses zeros e uns que um computador realmente usa?
É o que está dentro do computador, não são lâmpadas, mas sim minusculos interruptores, bilhões deles, que podem estar ligados ou desligados.
Agora que já sabemos sobre como o computador se comunica com os nossos comandos e como ele conta, podemos pensar em não só dígitos numéricos, mas como transformar esses inputs (zeros e uns), em dados mais complexos, como um caracter, para formar uma palavra.
As pessoas que inventaram os primeiros computadores tiveram uma ideia muito simples, para cada letra do alfabeto foi atribuído um valor numérico, assim nasceu a tabela ASCII.
[imagem tabela ASCII]
Então para cada número, temos um caracter mapeado, não só letras, mas todos os ascentos, caracteres especiais, pontos, virgulas e etc...
Exemplos:
1000001 = 65 = A
1000010 = 66 = B
Mas essa tabela, que foi inventada a muito tempo atrás e só compreendia os caracteres do idioma inglês, e não todos os caracteres, de todas as línguas do mundo, sendo assim, teve que ser criada mais uma tabela para unificar o jeito que os computadores interpretam os caracteres essa é o sistema UNICODE, esta reserva um valor muito maior de espaço para acomodar todos os caracteres possíveis, bem como novos que ainda possam surgir.
Um exemplo de caractere que não existia na primeira tabela ASCII e foi criado posteriormente e suportado pelo sistema de UNICODE: 😂
Já sabemos como representar dígitos e textos usando o sistema binário como base, mas como podemos representar uma imagem?
Do mesmo jeito que é feito com os caracteres, novamente, cada número representa uma core com base em uma tabela que foi acordada entre um grupo de pessoas. Você já deve ter ouvido falar de RGB,
que significa red, green and blue (vermelho, verde e azul). Como é sabido que todas as cores do arcoíris conseguem ser representadas quando misturadas essas tres cores, este sistema sistema foi criado, e cada uma das
letras, representa a quantidade de cada cor a sua tela precisa misturar para criar a cor que é representada por um bite, ou seja um número binário composto por oito dígitos. que pode ir de 0 à 255.
Exemplo de cores representadas pela tabela
RGB:
rgb(0,0,0) = rgb(0000000,0000000,0000000) = Preto
rgb(255, 255, 255) = rgb(11111111, 11111111, 11111111) = Branco
E se você se pergunta por que existem tantas extenções de arquivos, como .PNG, .GIF, .JPEG, isso é somente um exemplo de mais um momento em que várias pessoas acordaram em como guardar e interpretar esses zeros e uns de maneiras um pouco diferentes, mas no fim, continuam ainda sendo somente zeros e uns.
E deste jeito, todos os tipos de dados, letras, emojis, imagens, vídeos, músicas são representados por um computador usando apenas os zeros e uns, fornecidos pelos impulsos elétricos que são passados pelos transistores.
Agora que já entendemos como é feita a representação de dados através de um sistema binário, como o computador transforma zeros e uns em letras, dígitos, emojis, imagens, videos e etc... Conseguimos entender melhor os algoritimos que são usados para fazer isso.
Percebemos que tudo que um computador faz, é usar uma entrada (input) e transformar em uma saída (output), porém, para que tenhamos a saída desejada, temos que desenvolver um algorítimo que usa a entrada e executa instruções a modo que, a saída do algoritimo esteja de acordo com o resultado que desejamos.
Pense numa receita culinária, por exemplo. Ela tem os ingredientes necessários (dados de entrada), passo a passo para realizar a receita (processamento ou instruções lógicas) e atinge um resultado (o prato finalizado). Conforme nossa receita fica mais complexa, com mais ingredientes, uma cobertura diferenciada, mais complexo ficará o nosso algoritimo, que deve levar em conta agora todos os ingredientes e passos a mais no momento do preparo.
Entrada:
3 xícaras (chá) de Farinha de Trigo;
1 xícara (200 g) de manteiga em temperatura ambiente;
2 xícaras (chá) de açúcar;
4 ovos;
1 xícara (chá) de leite;
2 colheres (chá) de fermento em pó;
1 pitada de sal;
Manteiga e farinha de trigo para untar e polvilhar a forma;
Açúcar de confeiteiro para polvilhar;
Algoritimo:
- Na batedeira, bata a manteiga até que ficar esbranquiçada. Adicione aos poucos o açúcar. Bata por cerca de 5 minutos.
- Junte os ovos, um a um, batendo sempre. Acrescente o sal e, em seguida, a Farinha de Trigo alternando com o leite.
- Desligue a batedeira e, por último, misture o fermento delicadamente com uma espátula. Transfira para a forma untada e enfarinhada.
- Leve ao forno preaquecido a 180°C e deixe assar por aproximadamente 40 minutos ou até que faça o teste de espetar o palito no centro do bolo e ele saia limpo.
- Desenforme e sirva.
Saída:
🎂🎂🎂
Note que nosso algorítimo segue uma sequência lógica, bem definida, e nos instrui a executar um passo de cada vez no momento certo, para que o resultado final seja o esperado.

O C# é uma linguagem de programação moderna, orientada a objeto e type-safe. O C# permite que os desenvolvedores criem muitos tipos de aplicativos seguros, robustos e multiplataforma que são executados na plataforma .NET.
Vários recursos do C# ajudam a criar aplicativos robustos e duráveis. A coleta de lixo recupera automaticamente a memória ocupada por objetos não utilizados. Os tipos nullables protegem contra variáveis que não se referem a objetos alocados. A manipulação de exceção fornece uma abordagem estruturada e extensível para detecção e recuperação de erros. As expressões lambda dão suporte a técnicas de programação funcional.
A sintaxe de linguagem deconsulta integrada (LINQ) cria um padrão comum para trabalhar com dados de qualquer fonte. A linguagem oferece suporte para operações assíncronas e fornece a sintaxe para a criação de sistemas distribuídos.
O C# tem um sistema de tipos unificado. Onde todos os tipos do C#, incluindo tipos primitivos, como int e double, herdam de um único tipo de object raiz. Todos os tipos compartilham um conjunto de operações comuns.
Os valores de qualquer tipo podem ser armazenados, transportados e operados de maneira consistente. Além disso, o C# dá suporte a tipos de referência definidos pelo usuário e tipos de valor e permite a alocação dinâmica de objetos e o armazenamento em linha de estruturas leves. O C# oferece suporte a tipos e métodos genéricos, que fornecem aumento na segurança e no desempenho.
Os programas em C# são executados na plataforma .NET, um sistema de execução virtual chamado Common Language Runtime (CLR) e um conjunto de bibliotecas de classes. O CLR é a implementação da Microsoft da CLI (Common Language Infrastructure), um padrão internacional.
A CLI é a base para a criação de ambientes de execução e desenvolvimento nos quais as linguagens e bibliotecas funcionam em conjunto diretamente.
O código-fonte escrito em C# é compilado em uma IL (linguagem intermediária) que está de acordo com a especificação da CLI. O código de IL e os recursos, como bitmaps e cadeias de caracteres, são armazenados em um assembly, normalmente com uma extensão ".dll". Um assembly contém um manifesto que fornece informações sobre os tipos, a versão e a cultura do assembly.
Quando o programa C# é executado, o assembly é carregado no CLR. O CLR executa a compilação JIT (just-intime) para converter o código IL em instruções de máquina nativa. O CLR fornece outros serviços relacionados à coleta de lixo, manipulação de exceções e gerenciamento de recursos automáticos.
A interoperabilidade da linguagem é um recurso fundamental do .NET.
O código de IL produzido pelo compilador está de acordo com a CTS (especificação de tipo comum). O código IL gerado do C# pode interagir com o código gerado nas versões do .NET do F#, Visual Basic, C++.
Há mais de 20 outros idiomas em conformidade com CTS. Um único assembly pode conter vários módulos escritos em diferentes linguagens .NET.
Os tipos podem referenciar um ao outro como se fossem escritos no mesmo idioma. Além dos serviços de tempo de execução, o .NET também inclui bibliotecas extensivas. Essas bibliotecas dão suporte a várias cargas de trabalho diferentes. Eles são organizados em namespaces que fornecem uma ampla variedade de funcionalidades úteis. As bibliotecas incluem tudo, desde entrada e saída de arquivo até a manipulação de cadeia de caracteres à análise de XML, aplicativos web e applicativos nativos do Windows.
- Windows
- macOS
- Linux
- Android
- iOS
- tvOS
- watchOS
- x64
- x86
- ARM32
- ARM64
As linguagens .NET de nível mais alto , como C#, são compiladas em um conjunto de instruções independente de hardware, que é chamado de IL (linguagem intermediária).
Quando um aplicativo é executado, o compilador JIT (just-in-time) converte a IL em código de computador que o processador entende. A compilação JIT ocorre no mesmo computador em que o código será executado.
Como a compilação JIT ocorre durante a execução do aplicativo, o tempo de compilação faz parte do tempo de execução. Portanto, os compiladores JIT têm que equilibrar o tempo gasto otimizando o código em
relação à economia que o código resultante pode produzir. Mas um compilador JIT conhece o hardware real e pode liberar os desenvolvedores de ter que enviar implementações diferentes para diferentes plataformas.
O compilador JIT do .NET pode fazer a compilação em camadas, o que significa que ele pode recompilar métodos individuais em tempo de execução. Esse recurso permite que ele seja compilado rapidamente e
ainda seja capaz de produzir uma versão altamente ajustada do código para métodos usados com frequência.
O GC (coletor de lixo) gerencia a alocação e a liberação de memória para aplicativos. Sempre que o código cria um novo objeto, o CLR aloca memória para o objeto do heap gerenciado. Desde que exista espaço de endereço
disponível no heap gerenciado, o runtime continua alocando espaço para novos objetos. Quando não há espaço de endereço livre suficiente, o GC verifica se há objetos no heap gerenciado que não estão mais sendo
usados pelo aplicativo. Em seguida, ele recupera essa memória.
O GC é um dos serviços CLR que ajudam a garantir a segurança da memória. Um programa é considerado de memória segura se ele acessa somente a memória alocada. Por exemplo, o runtime garante que um aplicativo não
acesse memória não alocada além dos limites de uma matriz.

O .NET Framework surgiu em meados de 2002, ele era um framework único para desenvolvimento na plataforma Windows. Com o passar do tempo ganhou suporte para WEB, WCF, WPF, Windows Forms, etc, ele é composto por dois componentes principais: O CLR (Common Language Runtime), o mecanismo de execução que manipula os aplicativos em execução, e a biblioteca de classes .NET Framework, que oferece uma biblioteca imensa de códigos testados e reutilizáveis.
Atualmente o .NET Framework está na versão 4.8 e não receberá mais atualizações com features adicionais, apenas será atendido com correções de bugs de segurança e confiabilidade.
O .NET Core surgiu em meados de 2016, sua característica mais marcante é ele ser cross-plataform, isto é, ele é suportado em múltiplas plataformas, sendo possível o desenvolvimento em Windows, Linux e MacOS.
A Microsoft percebeu que não poderia ficar presa ao ambiente Windows, mas seria quase impossível reutilizar o até então .NET Framework. De uma maneira inteligente, foi iniciado um novo projeto, que iria andar em paralelo com a versão atual, mas com uma nova arquitetura, open-source e modular, surgiu então o dotnet core.
O .NET Standard, atualmente na versão 2.1, surge para ser um meio termo entre as duas versões, ele é uma interface que define a lista de APIs que uma determinada função do .NET deve suportar. Sendo assim, uma biblioteca escrita utilizando o .NET Standard pode ser suportado tanto por aplicações utilizando o .NET Core quanto o .NET Framework. Ele foi criado para que esse compartilhamento seja muito mais fácil e uniforme no ecossistema do .NET. No entanto, vale lembrar, que com o advento do .NET 5, que será universal, a utilização dele se torna desnecessária em muitos cenários.
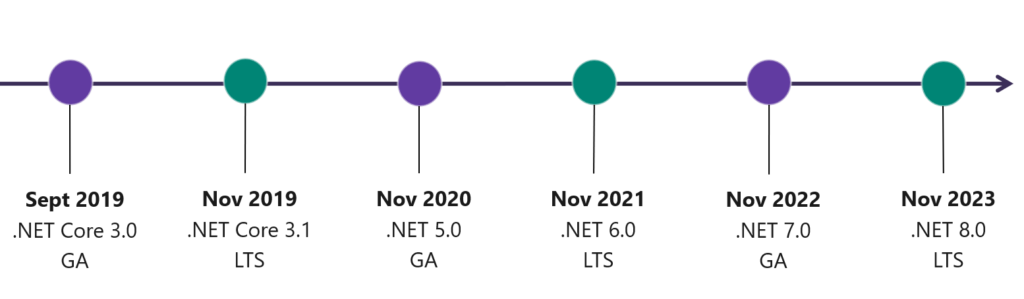
Em 2020 tivemos o lançamento do .NET 5, que não é mais o futuro, e sim o presente da plataforma .NET. Ambas as versões eram mantidas em paralelo, mas agora temos um ponto de encontro entre as duas versões, o .NET Framework 4.8, e .NET Core 3.1, são agora o .NET 5, e não teremos mais duas versões. O próximo lançamento está planejado para novembro de 2021, com o .NET 6.
Se você está planejando construir uma nova aplicação utilizando o .NET, ela deve iniciar com o .NET 5, e para sistemas legados, que utilizam o .NET Framework, deve ser iniciado um planejamento para a migração, visto que a Microsoft irá deprecear o .NET Framework.
O .Net oferece uma CLI (interface de linha de comando) para a gestão e controles de aplicativos desevolvidos na plataforma.
A CLI do .NET é uma ferramenta multiplataforma para desenvolvimento, criação, execução e publicação de aplicativos .NET multiplataforma e é instalada por padrão na máquina onde está instalada o SDK do .Net Core.
- new
- restore
- build
- publish
- run
- test
- vstest
- pack
- migrate
- clean
- sln
- help
- store
O comando executa uma ação. Por exemplo, dotnet build compila código, dotnet publish publica o código.
Os comandos são implementados como um aplicativo de console usando uma convenção "dotnet {command}".
Os argumentos que você passa na linha de comando são aqueles do comando invocado.
Por exemplo, quando você executa dotnet publish my_app.csproj, o my_app.csproj é o argumento que indica o projeto a ser publicado e é passado para o comando publish como parâmetro.
As opções que você passa na linha de comando são aquelas do comando invocado.
Por exemplo, quando você executa dotnet publish --output /build_output, a opção --output e seu valor são passados para o comando dotnet publish.
O .NET é de código aberto, usando licenças MIT e Apache 2. O .NET é um projeto do .NET Foundation. Para obter mais informações, consulte a lista de repositórios de projeto no github.
A Microsoft desenvolve e fornece uma das IDEs mais completas e ultilizadas para o desenvolvimento na plataforma .Net, o Visual Studio, que pode ser baixada e utilizada de graça por desenvolvedores por período inderterminado.
A Microsoft também desenvolveu uma IDE mais leve e de código aberto, totalmente gratuíta que ficou muito famosa ultimamente por seus variados plugins que dão suporte a basicamente qualquer linguagem de programação em um pacote mais leve e personalizável.
O GitHub é uma plataforma de hospedagem de código-fonte e arquivos com controle de versão usando o Git. Ele permite que programadores, utilitários ou qualquer usuário cadastrado na plataforma contribuam em projetos privados e/ou Open Source de qualquer lugar do mundo. GitHub é amplamente utilizado por programadores para divulgação de seus trabalhos ou para que outros programadores contribuam com o projeto, além de promover fácil comunicação através de recursos que relatam problemas ou mesclam repositórios remotos (issues, pull request).
| Comando | Descrição |
|---|---|
| git config | Comando genérico para alterar as configurações globais do git no sistema |
| git init [nome-do-projeto] | Cria um novo repositório local com nome específico |
| git clone | Faz o download de um projeto e todo seu histórico |
| git status | Lista todos os arquivos novos ou modificados para serem commitados |
| git diff | Mostra diferenças no arquivo que não foram realizadas |
| git add [arquivo] | Faz o snapshot de um arquivo na preparação para versionamento |
| git commit -m "[mensagem]" | Grava o snapshot permanentemente do arquivo no histórico de versão |
| git branch | Lista todos os branches locais no repositório atual |
| git branch [nome-do-branch | git branch [nome-do-branch] |
| git checkout [nome-do-branch] | Muda para o branch específico e atualiza o diretório de trabalho |
| git merge [branch] | Combina o histórico do branch específico com o branch atual |
| git stash | Armazena temporariamente todos os arquivos rastreados modificados |
| git stash pop | Restaura os arquivos recentes em stash |
| git fetch [marcador] | Baixe todo o histórico de um marcador de repositório |
| git push [alias] [branch] | Envia todos os commits do branch local para o GitHub |
| git pull | Baixa o histórico e incorpora as mudanças |
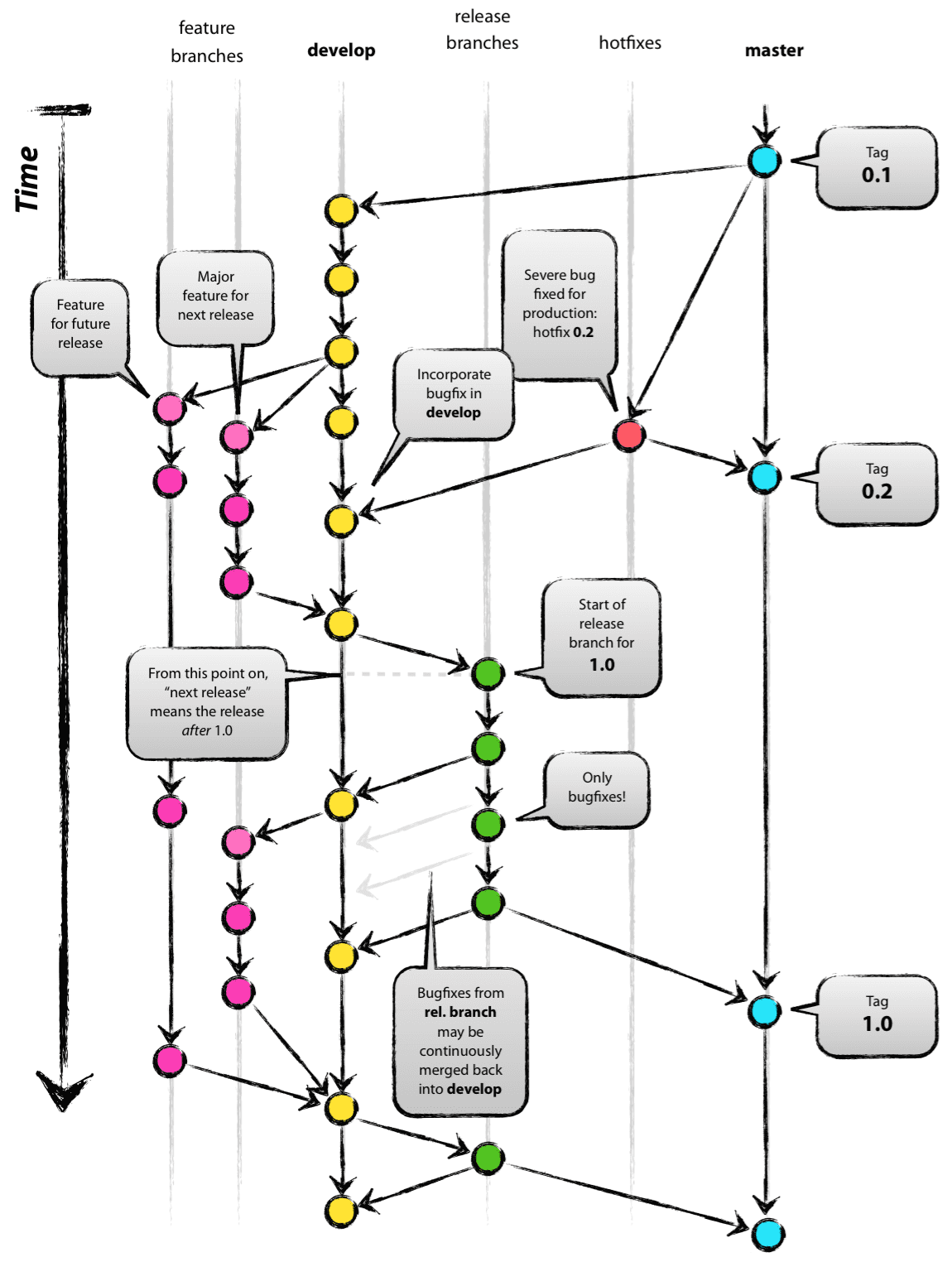
O Gitflow é um modelo alternativo de ramificação do Git que consiste no uso de ramificações de recursos e várias ramificações primárias. Ele foi publicado pela primeira vez e popularizado por Vincent Driessen no nvie. Comparado ao desenvolvimento baseado em troncos, o Gitflow tem mais ramificações de vida longa e commits maiores. Sob este modelo, os desenvolvedores criam uma ramificação de recurso e retardam o merge com a ramificação de tronco principal até que o recurso esteja completo.
Essas ramificações de recursos de longa duração exigem mais colaboração para fazer o merge e têm um risco maior de se desviarem da ramificação do tronco. Elas também podem introduzir atualizações conflitantes.
As variáveis representam locais de armazenamento. Cada variável tem um tipo que determina quais valores podem ser armazenados na variável. O C# é uma linguagem de tipo seguro, e o compilador garante que os valores armazenados em variáveis sejam sempre do tipo apropriado. O valor de uma variável pode ser alterado por atribuição ou pelo uso de operadores.
Uma variável deve ser definitivamente atribuída (atribuição definitiva) antes que seu valor possa ser obtido.
O C# define sete categorias de variáveis: variáveis estáticas, variáveis de instância, elementos de matriz, parâmetros de valor, parâmetros de referência, parâmetros de saída e variáveis locais.
Um campo declarado com o modificador static é chamado de uma variável estática. Uma variável estática entra em existência no momento da criação do aplicativo, e deixa de existir quando o domínio do aplicativo associado deixar de existir.
Um campo declarado sem o modificador static é chamado de variável de instância.
Uma variável de instância de uma classe entra em existência quando uma nova instância dessa classe é criada, e deixa de existir quando não há nenhuma referência a essa instância.
Uma variável de instância de uma struct tem exatamente o mesmo tempo de vida que a variável de struct à qual ela pertence. Em outras palavras, quando uma variável de um tipo struct entra em existência ou deixa de existir, também as variáveis de instância do struct.
Os elementos de uma matriz entram em existência quando uma instância de matriz é criada e deixam de existir quando não há mais nenhuma referência a essa instância de matriz.
Um parâmetro declarado sem um modificador ref ou out é um parâmetro de valor.
Um parâmetro de valor entra em existência na invocação do membro da função (método, construtor), e é inicializado com o valor do argumento fornecido na invocação. Um parâmetro de valor normalmente deixa de existir no retorno do membro da função ou da função anônima.
Um parâmetro declarado com um modificador ref é um parâmetro de referência.
Um parâmetro de referência não cria um novo local de armazenamento (registro na memória). Em vez disso, um parâmetro de referência representa o mesmo local de armazenamento que a variável fornecida como o argumento no membro da função. Assim, o valor de um parâmetro de referência é sempre o mesmo que a variável subjacente.
Um parâmetro declarado com um modificador out é um parâmetro de saída.
Parecido com um parametro de referência, um parâmetro de saída não cria um novo local de armazenamento. Em vez disso, um parâmetro de saída representa o mesmo local de armazenamento que a variável fornecida como o argumento no membro da função. Assim, o valor de um parâmetro de saída é sempre o mesmo que a variável subjacente.
Uma variável local é declarada por uma declaração simples, que pode ocorrer em um bloco, como dentro de um for, switch, using, foreach, try/catch...
O tempo de vida de uma variável local é a parte da execução do programa durante o qual o armazenamento tem a garantia de ser reservado para ele. Esse tempo de vida se estende pelo menos da entrada do bloco, o qual está associado, até a execução desse bloco. Se o bloco pai, for inserido recursivamente, uma nova instância da variável local será criada a cada vez.
Uma variável local não é inicializada automaticamente e, portanto, não tem valor padrão.
Para declarar uma varíavel local, podemos usar a palavra-chave var, ou explicitamente definir o tipo da variável antes de atribuir um valor a ela. Como no exemplo a seguir:
var a = 1;
int b = 2;
Também pode se declarar várias variáveis do mesmo tipo em uma só linha:
int a = 1, b = 2, c = 3;
Se você quer ter certeza que o valor da sua variável não seja modificado em nenhuma parte do código após a declaração do seu valor, deve se usar a palavra-chave const, que proíbe que o valor da variável seja alterado pelo programa após sua inicialização:
const int a = 1;
Toda linguagem de programação possui operadores lógicos para realizar operações booleanas, que resultam em verdadeiro ou falso, esses operadores se diferem somente no jeito que são definidos pela sintaxe de cada linguagem de programação, mas servem o mesmo propósito e são muito utilizadas por qualquer programa.
O operador ! calcula a negação lógica de seu operando. Ou seja, ele produz verdadeiro, se o operando for avaliado como falso, e falso, se o operando for avaliado como verdadeiro:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(!false); // Saída: True
Console.WriteLine(!true); // Saída: False
}
}
O operador & computa o AND lógico de seus operandos. O resultado de x & y será verdadeiro se ambos x e y forem avaliados como verdadeiros. Caso contrário, o resultado será falso:
O operador AND lógico condicional && também computa o AND lógico e seus operandos, mas não avalia o operando à direita se o operando à esquerda for avaliado como falso:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(false & false); // Saída: False
Console.WriteLine(true & false); // Saída: False
Console.WriteLine(false && true); // Saída: False
Console.WriteLine(true & true); // Saída: True
}
}
O operador ^ computa o OR exclusivo lógico, também conhecido como o XOR lógico, de seus operandos. O resultado de x ^ y é verdadeiro se x é avaliado como verdadeiro e y avaliado como falso, ou x avaliado como falso e y avaliado como verdadeiro. Caso contrário, o resultado será falso. Ou seja, o operador ^ calcula o mesmo resultado que o operador de desigualdade !=:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(true ^ true); // Saída: False
Console.WriteLine(true ^ false); // Saída: True
Console.WriteLine(false ^ true); // Saída: True
Console.WriteLine(false ^ false); // Saída: False
}
}
O operador | computa o OR lógico de seus operandos. O resultado de x | y será true se x ou y for avaliado como verdadeiro. Caso contrário, o resultado será falso:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(true | true); // Saída: True
Console.WriteLine(true | false); // Saída: True
}
}
O operador || também computa o OR lógico e seus operandos, mas não avalia o operando à direita se o operando à esquerda for avaliado como verdadeiro:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(true || true); // Saída: True
Console.WriteLine(true || false); // Saída: True
}
}
A lista a seguir ordena os operadores lógicos, começando da mais alta precedência até a mais baixa:
- Operador de negação lógica
! - Operador AND lógico
& - Operador OR exclusivo lógico
^ - Operador OR lógico
| - Operador AND lógico condicional
&& - Operador OR lógico condicional
||
Use parênteses para alterar a ordem de avaliação imposta pela precedência do operador.
O operador de incremento unário ++ incrementa seu operando em 1. O operando precisa ser uma variável, um acesso de propriedade ou um acesso de indexador:
using System;
public class Program
{
public static void Main()
{
int i = 3;
Console.WriteLine(i); // Saída: 3
i++;
Console.WriteLine(i); // Saída: 4
}
}
O operador de decremento unário -- decrementa o operando em 1. O operando precisa ser uma variável, um acesso de propriedade ou um acesso de indexador:
using System;
public class Program
{
public static void Main()
{
int i = 3;
Console.WriteLine(i); // Saída: 3
i--;
Console.WriteLine(i); // Saída: 2
}
}
O operador de multiplicação * calcula o produto dos operandos:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(5 * 2); // Saída: 10
Console.WriteLine(0.5 * 2.5); // Saída: 1.25
Console.WriteLine(0.1m * 23.4m); // Saída: 2.34
}
}
O operador de divisão / divide o operando à esquerda pelo operando à direita:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(13 / 5); // Saída: 2
Console.WriteLine(-13 / 5); // Saída: -2
Console.WriteLine(13 / -5); // Saída: -2
Console.WriteLine(-13 / -5); // Saída: 2
}
}
O operador de resto % calcula o resto após dividir o operando à esquerda pelo à direita:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(5 % 4); // Saída: 1
Console.WriteLine(5 % -4); // Saída: 1
Console.WriteLine(-5 % 4); // Saída: -1
Console.WriteLine(-5 % -4); // Saída: -1
}
}
O operador de adição + calcula a soma dos operandos:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(5 + 4); // Saída: 9
Console.WriteLine(5 + 4.3); // Saída: 9.3
Console.WriteLine(5.1m + 4.2m); // Saída: 9.3
}
}
O operador de subtração - subtrai o operando à direita do operando à esquerda:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(47 - 3); // Saída: 44
Console.WriteLine(5 - 4.3); // Saída: 0.7
Console.WriteLine(7.5m - 2.3m); // Saída: 5.2
}
}
A seguinte lista ordena os operadores aritméticos da precedência mais alta para a mais baixa:
- Operadores de multiplicação, divisão e resto:
*,/e% - Operadores de adição e subtração:
+e-
Operadores aritméticos binários são associativos à esquerda. Ou seja, os operadores com o mesmo nível de precedência são avaliados da esquerda para a direita.
Use parênteses para alterar a ordem de avaliação imposta pela precedência e pela capacidade de associação do operador.
O operador de igualdade == retornará verdadeiro se seus operandos forem iguais, caso contrário, falso:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(1 == 1); // Saída: True
Console.WriteLine(1 == 10); // Saída: False
Console.WriteLine("x" == "x"); // Saída: True
}
}
O operador de desigualdade != retornará verdadeiro se seus operandos não forem iguais, caso contrário, falso:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(1 != 1); // Saída: False
Console.WriteLine(1 != 10); // Saída: True
Console.WriteLine("x" != "x"); // Saída: False
}
}
O operador < retornará verdadeiro se o operando à esquerda for menor do que o operando à direita, caso contrário, falso:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(7.0 < 5.1); // Saída: False
Console.WriteLine(5.1 < 5.1); // Saída: False
Console.WriteLine(0.0 < 5.1); // Saída: True
}
}
O operador > retornará verdadeiro se o operando à esquerda for maior do que o operando à direita, caso contrário, falso:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(7.0 > 5.1); // Saída: True
Console.WriteLine(5.1 > 5.1); // Saída: False
Console.WriteLine(0.0 > 5.1); // Saída: False
}
}
O operador <= retornará true se o operando à esquerda for menor ou igual ao operando à direita, caso contrário, false:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(7.0 <= 5.1); // Saída: False
Console.WriteLine(5.1 <= 5.1); // Saída: True
Console.WriteLine(0.0 <= 5.1); // Saída: True
}
}
O operador >= retornará true se o operando à esquerda for maior ou igual ao operando à direita, caso contrário, false:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(7.0 >= 5.1); // Saída: True
Console.WriteLine(5.1 >= 5.1); // Saída: True
Console.WriteLine(0.0 >= 5.1); // Saída: False
}
}
O operador condicional, também conhecido como operador condicional ternário, avalia uma expressão booleana e retorna o resultado de uma das duas expressões, dependendo se a expressão booleana é avaliada, como mostra o exemplo:
using System;
public class Program
{
public static void Main()
{
Console.WriteLine(BuscaDescricaoTemperatura(15)); // output: Frio
Console.WriteLine(BuscaDescricaoTemperatura(27)); // output: Perfeito
string BuscaDescricaoTemperatura(double temperatura) => temperatura < 20.0 ? "Frio" : "Perfeito";
}
}
Como mostra o exemplo anterior, a sintaxe do operador condicional é a seguinte:
condicao ? consequência : alternativa
As ações que um programa executa são expressas em instruções. Ações comuns incluem declarar variáveis, atribuir valores, chamar métodos, fazer loops pelas coleções e ramificar para um ou para outro bloco de código, dependendo de uma determinada condição. A ordem na qual as instruções são executadas em um programa é chamada de fluxo de controle ou fluxo de execução. O fluxo de controle pode variar sempre que um programa é executado, dependendo de como o programa reage às entradas que recebe em tempo de execução.
Uma instrução pode consistir em uma única linha de código que termina em um ponto e vírgula, ou uma série de instruções de uma linha em um bloco.
É uma instrução que define se determinado bloco de código deve ser executado com base no resultado de uma expressão booleana, como mostra o exemplo a seguir:
using System;
public class Program
{
public static void Main()
{
double temperatura = 20.0;
if (temperatura < 20.0)
{
Console.WriteLine("Frio");
}
else
{
Console.WriteLine("Perfeito");
}
}
}
Uma instrução if pode não vir acompanhada de uma instrução else:
using System;
public class Program
{
public static void Main()
{
int valor = 250;
if (valor < 0 || valor > 100)
{
Console.Write("Valor muito baixo ou muito alto");
}
Console.WriteLine($"O valor é {valor}");
}
}
Você pode aninhar instruções if para verificar várias condições:
using System;
public class Program
{
public static void Main()
{
char ch = 'a';
if (char.IsUpper(ch))
{
Console.WriteLine($"É uma letra maíuscula: {ch}");
}
else if (char.IsLower(ch))
{
Console.WriteLine($"É uma letra minúscula: {ch}");
}
else if (char.IsDigit(ch))
{
Console.WriteLine($"É um dígito: {ch}");
}
else
{
Console.WriteLine($"Não é um caracter alfanumérico: {ch}");
}
}
}
A instrução switch seleciona uma lista de instruções a ser executada com base em uma combinação de padrões com uma expressão de match:
using System;
public class Program
{
public static void Main()
{
double medida = 2;
switch (medida)
{
case < 0.0:
Console.WriteLine($"Valor medido é: {medida}; muito baixo.");
break;
case > 15.0:
Console.WriteLine($"Valor medido é: {medida}; muito alto.");
break;
case double.NaN:
Console.WriteLine("Inválido");
break;
default:
Console.WriteLine($"Valor medido é: {medida}.");
break;
}
}
}
Você pode especificar vários padrões de case para uma seção de valores:
using System;
public class Program
{
public static void Main()
{
double medida = 2;
switch (medida)
{
case <0:
case>100:
Console.WriteLine($"Valor medido é: {medida}; fora do intervalo aceito.");
break;
default:
Console.WriteLine($"Valor medido é: {medida}.");
break;
}
}
}
Uma expressão simples de case pode não ser o suficiente para especificar a condição para a execução do bloco de código. Nesse caso, você pode usar um case guard. Essa é uma condição adicional que deve ser atendida junto com um padrão de combinação. Um case guard deve ser uma expressão booleana. Especifique um case guard após a palavra-chave when, como mostra o exemplo a seguir:
using System;
public class Program
{
public static void Main()
{
int a = 4, b = 3;
switch ((a, b))
{
case (>0, >0) when a == b:
Console.WriteLine($"Os doi valores são validos e iguais a: {a}.");
break;
case (>0, >0):
Console.WriteLine($"Primeiro valor é: {a}, segundo valor é: {b}.");
break;
default:
Console.WriteLine("Um ou todos os valores são inválidos");
break;
}
}
}
A instrução do while executa uma instrução ou um bloco de instruções enquanto uma expressão booleana é avaliada como verdadeira. Como essa expressão é avaliada após cada execução do loop, um loop do while
é executado uma ou mais vezes. Isso é diferente de um loop while, que executa zero ou mais vezes:
using System;
public class Program
{
public static void Main()
{
int n = 0;
do
{
Console.Write(n);
n++;
}
while (n < 5);
}
}
A instrução while executa uma instrução ou um bloco de instruções enquanto uma expressão booleana especificada é avaliada como verdadeira. Como essa expressão é avaliada antes de cada execução do loop, um loop while é executado zero ou mais vezes:
using System;
public class Program
{
public static void Main()
{
int n = 0;
while (n < 5)
{
Console.Write(n);
n++;
}
}
}
A instrução for executa uma instrução ou um bloco de instruções enquanto uma expressão booleana especificada é avaliada como verdadeira. O exemplo a seguir mostra a instrução for que executa seu corpo
enquanto um contador inteiro é menor que três:
using System;
public class Program
{
public static void Main()
{
for (int i = 0; i < 3; i++)
{
Console.Write(i);
}
}
}
A instrução foreach executa uma instrução ou um bloco de instruções para cada elemento em uma instância do tipo que implementa a interface ou, como mostra o foreach exemplo a System.Collections.IEnumerable<T>:
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var sequenciaFibonacci = new List<int>{0, 1, 1, 2, 3, 5, 8, 13};
foreach (int numero in sequenciaFibonacci)
{
Console.Write($"{numero} ");
}
}
}
A instrução return finaliza a execução do método em que aparece e retorna o controle para o método de chamada. Ela também pode retornar um valor opcional. Se o método for um tipo void, a instrução return
poderá ser omitida.
Se a instrução return estiver dentro de um bloco try, o bloco finally, se houver, será executado antes que o controle retorne para o método de chamada.
No exemplo a seguir, o método CalculateArea() retorna a variável local area como um valor double:
using System;
public class Program
{
public static void Main()
{
int radius = 5;
double result = CalculateArea(radius);
Console.WriteLine("The area is {0:0.00}", result);
Console.ReadKey();
}
static double CalculateArea(int r)
{
double area = r * r * Math.PI;
return area;
}
}
A instrução continue passa o controle para a próxima iteração da instrução de iteração delimitadora na qual ele aparece.
Neste exemplo, um contador é inicializado para a contagem de 1 a 10. Usando a instrução continue em conjunto com a expressão (i< 9), as instruções entre continue e o final do bloco for são ignoradas nas
iterações em que i é menor que 9. Nas duas últimas iterações do loop for (onde i == 9 e i == 10), a instrução continue não é executada e o valor de i é impresso no console.
using System;
public class Program
{
public static void Main()
{
for (int i = 1; i <= 10; i++)
{
if (i < 9)
{
continue;
}
Console.WriteLine(i);
}
Console.ReadKey();
}
}
A instrução break encerra o loop delimitado mais próximo, ou switch na qual ela aparece. O controle é passado para a instrução que segue a instrução encerrada, se houver.
Neste exemplo, a instrução condicional tem um contador que deveria contar de 1 a 100. No entanto, a instrução break encerra o loop após 4 contagens.
using System;
public class Program
{
public static void Main()
{
for (int i = 1; i <= 100; i++)
{
if (i == 5)
{
break;
}
Console.WriteLine(i);
}
Console.ReadKey();
}
}
A sintaxe de throw é:
throw [e];
Em que e é uma instância de uma classe derivada de System.Exception. O exemplo a seguir usará a instrução throw para gerar um IndexOutOfRangeException se o argumento passado para o método chamado
GetNumber não corresponder a um índice válido de uma matriz interna.
public class NumberGenerator
{
int[] numbers = { 2, 4, 6, 8, 10, 12, 14, 16, 18, 20 };
public int GetNumber(int index)
{
if (index < 0 || index >= numbers.Length)
{
throw new IndexOutOfRangeException();
}
return numbers[index];
}
}
Os chamadores do método, então, usam um bloco try-catch ou try-catch-finally para tratar a exceção gerada.
O exemplo a seguir trata a exceção gerada pelo método GetNumber:
public static void Main()
{
var gen = new NumberGenerator();
int index = 10;
try
{
int valor = gen.GetNumber(index);
Console.WriteLine($"Recuperado: {valor}");
}
catch (IndexOutOfRangeException e)
{
Console.WriteLine($"{e.GetType().Name}: {index} está fora dos limites do array");
}
}
A instrução try-catch consiste em um bloco try seguido por uma ou mais cláusulas catch, que especificam os manipuladores para diferentes exceções. Quando uma exceção é lançada, o CLR (Common Language Runtime) procura a instrução catch que trata essa exceção. Se o método em execução no momento não contiver um bloco catch, o CLR procurará no método que chamou o método atual e assim por diante para cima na pilha de chamadas. Se nenhum bloco catch for encontrado, o CLR exibirá uma mensagem de exceção sem tratamento para o usuário e interromperá a execução do programa.
O bloco try contém o código protegido que pode causar a exceção. O bloco é executado até que uma exceção seja lançada ou ele seja concluído com êxito. Por exemplo, a tentativa a seguir de converter um objeto null
gera a exceção NullReferenceException:
using System;
public class Program
{
public static void Main()
{
object o2 = "obj";
try
{
int i2 = (int)o2; // Error
}
catch (InvalidCastException e)
{
}
}
}
Embora a cláusula catch possa ser usada sem argumentos para capturar qualquer tipo de exceção, esse uso não é recomendado. Em geral, você deve capturar apenas as exceções das quais você sabe se recuperar.
É possível usar mais de uma cláusula catch específica na mesma instrução try-catch. Nesse caso, a ordem das cláusulas catch é importante porque as cláusulas catch são examinadas em ordem. Capture as exceções mais específicas antes das menos específicas:
catch (ArgumentException e) when (e.ParamName == "…")
{
}
Você pode capturar uma exceção e lançar uma exceção diferente. Quando fizer isso, especifique a exceção capturada como a exceção interna, como mostrado no exemplo a seguir:
catch (InvalidCastException e)
{
throw new YourCustomException("Mensagem de erro.", e);
}
Usando um bloco finally, você pode limpar todos os recursos alocados em um bloco try e pode executar código mesmo se uma exceção ocorrer no bloco try. Normalmente, as instruções de um bloco finally são
executadas quando o controle deixa uma instrução try. A transferência decontrole pode ocorrer como resultado da execução normal, da execução de uma instrução break, continue, goto ou return, ou da
propagação de uma exceção para fora da instrução try.
Dentro de uma exceção tratada, é garantido que o bloco finally será executado. No entanto, se a exceção não for tratada, a execução do bloco finally depende de como a operação de desenrolamento da exceção é disparada. Isso, por sua vez, depende da configuração do seu computador. Os únicos casos em que as finally cláusulas não são executadas envolvem um programa que está sendo imediatamente interrompido.
using System;
public class Program
{
public static void Main()
{
object obj = "obj";
try
{
// Conversão inválida
var i = (int)obj;
// Esse código nunca é executado
Console.WriteLine("Código que não é executado");
}
finally
{
Console.WriteLine("Código executado dentro do bloco finally");
}
}
}
Um uso comum de catch e finally juntos é obter e usar recursos em um bloco try, lidar com circunstâncias excepcionais em um bloco catch e liberar os recursos no bloco finally.
void ReadFile(int index)
{
// To run this code, substitute a valid path from your local machine
string path = @"c:\temp\test.txt";
System.IO.StreamReader file = new System.IO.StreamReader(path);
char[] buffer = new char[10];
try
{
file.ReadBlock(buffer, index, buffer.Length);
}
catch (System.IO.IOException e)
{
Console.WriteLine("Erro ao ler de {0}. Mensagem = {1}", path, e.Message);
}
finally
{
if (file != null)
{
file.Close();
}
}
}
O .NET usa o Char para representar caracteres Unicode usando a codificação UTF-16. O valor de um Char é seu valor numérico de 16 bits (ordinal).
Definindo uma variável do tipo char:
char chr = 'a';
var chr = 'a';
var chr = "\u0061";
char chr = (char)65;
O .Net oferece várias extensões para lidarmos com strings, contar os caracteres, separar, alterar, juntar, substituir e etc:
Quando necessitamos verificar se um char é um digito ou um caracter, usamos a função IsDigit:
using System;
public class Program
{
public static void Main()
{
char letra = 'a';
char digito = '1';
Console.WriteLine(char.IsDigit(digito)); // Saída: True
Console.WriteLine(char.IsDigit(letra)); // Saída: False
}
}
Parse:
using System;
public class Program
{
public static void Main()
{
string str = "1";
char chr = char.Parse(str);
Console.WriteLine(chr); // Saída: 1
}
}
TryParse:
using System;
public class Program
{
public static void Main()
{
string str = "a";
if (char.TryParse(str, out char chr))
{
Console.WriteLine($"Valor convertido: {chr}"); // Saída: Valor convertido: a
}
}
}
Convert
using System;
public class Program
{
public static void Main()
{
string str = "A";
char chr = Convert.ToChar(str);
Console.WriteLine(chr); // Saída: A
}
}
Representa uma cadeia de caracteres, uma coleção de caracteres que é usada para representar um texto. Um objeto string é uma coleção sequencial de objetos System.Char. Um objeto System.Char corresponde a uma unidade de código UTF-16.
O valor do objeto string é o conteúdo da coleção sequencial de objetos System.Char e esse valor é imutável (ou seja, é somente leitura).
O tamanho máximo de uma string na memória é de 2 GB ou cerca de 1.000.000.000 caracteres.
Você pode criar uma string de várias maneiras diferentes, como:
Definindo uma variável do tipo string:
string str = "Uma string";
char[] chars = { 's', 't', 'r', 'i', 'n', 'g' };
string str = new string(chars);
string str = "Hoje é " + DateTime.Now.ToString("D") + ".";
O .Net oferece várias extensões para lidarmos com strings, contar os caracteres, separar, alterar, juntar, substituir e etc:
Quando precisamos somente de um pedaço de uma string, usamos a função Substring:
using System;
public class Program
{
public static void Main()
{
string nome = "John Doe";
string primeiroNome = nome.Substring(0, 4);
string segundoNome = nome.Substring(5, 3);
Console.WriteLine(primeiroNome); // Saída: John
Console.WriteLine(segundoNome); // Saída: Doe
}
}
Quando precisamos juntar duas strings, podemos usar a função Concat:
using System;
public class Program
{
public static void Main()
{
string primeiroNome = "John";
string segundoNome = "Doe";
string nomeCompleto = string.Concat(primeiroNome, " ", segundoNome);
Console.WriteLine(nomeCompleto); // Saída: John Doe
}
}
Quando precisamos juntar um array de elementos em uma única string, podemos usar a função Join:
using System;
public class Program
{
public static void Main()
{
int[] valores = {1, 2, 4, 5, 6, 7, 8, 9, 10};
string texto = string.Join(" ", valores);
Console.WriteLine(texto); // Saída: 1 2 3 4 5 6 7 8 9 10
}
}
Para remover um pedaço do texto, podemos usar a função Remove:
using System;
public class Program
{
public static void Main()
{
string texto = "John Doe";
string primeiroNome = texto.Remove(4, 4);
Console.WriteLine(primeiroNome); // Saída: John
}
}
Para substituir uma letra, palavra ou pedaços de uma frase, podemos usar a função Replace
using System;
public class Program
{
public static void Main()
{
string texto = "John Doe";
string textoNormalizado = texto.Replace('o', 'a');
Console.WriteLine(textoNormalizado); // Saída: Jahn Dae
}
}
Para transformar um texto delimitado por algum caracter específico, e transformá-lo em um array de string, usamos a função Split
using System;
public class Program
{
public static void Main()
{
string texto = "John,Doe";
string[] textoSeparado = texto.Split(',');
Console.WriteLine(textoSeparado[0]); // Saída: John
Console.WriteLine(textoSeparado[1]); // Saída: Doe
}
}
Para limparmos espaços em branco no início e no final de uma string, usamos a função Trim:
using System;
public class Program
{
public static void Main()
{
string texto = " John Doe ";
string textoSemEspacos = texto.Trim();
Console.WriteLine(textoSemEspacos); // Saída: John Doe
}
}
A função
Trimtambém pode ser usada para remover os espaços em branco somente no início ou no final de uma string, usando suas variantesTrimStarteTrimEndrespectivamente.
Quando precisamos concatenar uma string, podemos usar também a interpolação de strings, adicionando o caracter $ no começo da string:
using System;
public class Program
{
public static void Main()
{
string primeiroNome = "John";
string segundoNome = "Doe";
string nomeCompleto = $"{primeiroNome} {segundoNome}";
Console.WriteLine(nomeCompleto); // Saída: John Doe
}
}
Quando precisamos concatenar uma string a partir de varias variáveis de uma maneira organizada, também podemos usar a função Format:
using System;
public class Program
{
public static void Main()
{
string primeiroNome = "John";
string segundoNome = "Doe";
string nomeCompleto = string.Format("{0} {1}", primeiroNome, segundoNome);
Console.WriteLine(nomeCompleto); // Saída: John Doe
}
}
Quando temos um texto muito extenso, que precisamos pular uma linha na IDE para tornar o código mais legível, podemos usar o caracter @ no começo de uma string:
using System;
public class Program
{
public static void Main()
{
string texto = @"
Lorem ipsum dolor sit amet, consectetur adipiscing elit,
sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.";
Console.WriteLine(texto);
}
}
Um integer é uma representação numérica de um número inteiro, e pode ser representado por um Int32, ou um Int64, os números 32 e 64 representam o numero de bytes que cada tipo pode alocar na memória.
Int32 é um tipo que representa os inteiros com sinal com valores que variam de -2.147.483.648 até 2.147.483.647.
Já o Int64 pode conter valores que variam de -9.223.372.036.854.775.808 até 9.223.372.036.854.775.807.
Dentro dos números inteiros também temos os UInt32 e UInt64, que seguem o mesmo comportamento dos inteiros comuns, porém só podem assumir valores positivos maiores que zero.
Definindo uma variável do tipo inteiro:
Int32 inteiro = 0; // define uma varável do tipo Int32
Int64 inteiro = 0; // define uma varável do tipo Int64
int inteiro = 0; // quando omitido o tamanho, por padrão é definida uma varável do tipo Int32
var numero = 10; // por padrão, sempre quando inicianmos uma variável sem especificar o seu tipo, é definida uma variável do tipo Int32 por padrão
Parse:
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
int numero = int.Parse(numeroStr);
Console.WriteLine(numero); // Saída: 10
}
}
TryParse:
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
if (int.TryParse(numeroStr, out int numero))
{
Console.WriteLine($"Valor convertido: {numero}"); // Saída: Valor convertido: 10
}
}
}
Convert
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
int numero = Convert.ToInt32(numeroStr);
Console.WriteLine(numero); // Saída: 10
}
}
O tipo Decimal representa números decimais, com vírgula, que variam de 79228162514264337593543950335 a -79228162514264337593543950335.
O tipo Decimal é apropriado para cálculos financeiros, que exigem um grande número de dígitos inteiros e fracionários significativos e nenhum erro de arredondamento.
Definindo uma variável do tipo decimal:
decimal numero = 1;
decimal numero = 2.5;
var numero = 2M;
Note o uso do
Mpara definir um decimal usando uma variável anônima
Parse:
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
decimal numero = decimal.Parse(numeroStr);
Console.WriteLine(numero); // Saída: 10
}
}
TryParse:
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
if (decimal.TryParse(numeroStr, out decimal numero))
{
Console.WriteLine($"Valor convertido: {numero}"); // Saída: Valor convertido: 10
}
}
}
Convert
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
decimal numero = Convert.ToDecimal(numeroStr);
Console.WriteLine(numero); // Saída: 10
}
}
O tipo Double representa um número de 64 bits de precisão dupla com valores que variam de -1.79769313486232 a 1.79769313486232, bem como zero positivo ou negativo.
Ele se destina a representar valores extremamente grandes (como distâncias entre planetas ou Galaxias) ou extremamente pequenos (como a massa de molecular de uma substância em quilogramas) e que geralmente são imprecisos (como a distância da terra para outro sistema solar).
Definindo uma variável do tipo decimal:
double numero = 1;
double numero = 2.5;
var numero = 2.5;
Parse:
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
double numero = double.Parse(numeroStr);
Console.WriteLine(numero); // Saída: 10
}
}
TryParse:
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
if (double.TryParse(numeroStr, out double numero))
{
Console.WriteLine($"Valor convertido: {numero}"); // Saída: Valor convertido: 10
}
}
}
Convert
using System;
public class Program
{
public static void Main()
{
string numeroStr = "10";
double numero = Convert.ToDouble(numeroStr);
Console.WriteLine(numero); // Saída: 10
}
}
Byte é um tipo de valor imutável que representa inteiros não assinados com valores que variam de 0 a 255.
O .NET também inclui um tipo de valor inteiro de 8 bits assinado, SByte , que representa valores que variam de -128 a 127.
O Tipo byte é muito utilizado quando queremos manipular arquivos do sistema, e precisamos ler ou gravar arquivos da memoria do computador.
Definindo uma variável do tipo byte:
byte valor = 64;
byte valor = 255;
var valor = (byte)25;
O tipo DateTime representa datas e horas com valores variando de 00:00:00 (meia-noite), 1º de janeiro de 0001 Anno Domini (era comum) até 11:59:59 P.M., 31 de dezembro, 9999 d.c. (C.E.) no calendário gregoriano.
Definindo uma variável do tipo DateTime:
var data = new DateTime(2008, 5, 1, 8, 30, 52);
DateTime data = DateTime.Now;
DateTime data = DateTime.UtcNow;
DateTime data = DateTime.Today;
Existem várias sobrecargas para a impressão de datas em formato de texto, o .Net fornece por padrão, o formato da data usado no computador em que o aplicativo está sendo utilizado, mas esse formato pode ser alterado da forma que desejarmos, como nestes exemplos:
using System;
public class Program
{
public static void Main()
{
DateTime data = new DateTime(2000, 1, 1);
Console.WriteLine(data); // Saída: 01/01/2000 00:00:00
Console.WriteLine(data.ToString("dd/MM/yyyy")); // Saída: 01/01/2000
Console.WriteLine(data.ToString("dd/MM/yyyy HH:mm:ss")); // Saída: 01/01/2000 00:00:00
Console.WriteLine(data.ToString("dd/MM/yyyy HH:mm:ss.sss")); // Saída: 01/01/2000 00:00:00.00
Console.WriteLine(data.ToString("MMMM yyyy")); // Saída: January 2000
Console.WriteLine(data.ToString("MMMM yy")); // Saída: January 00
Console.WriteLine(data.ToString("dddd, MMMM yyyy")); // Saída: Saturday, January 2000
}
}
Um Array é um conjunto de elementos de um mesmo tipo de dados onde cada elemento do conjunto é acessado pela posição no array que é dada através de um índice (uma sequência de números inteiros). Um array de uma dimensão é também conhecido como vetor,e , um array de mais de uma dimensão e conhecido como uma matriz.
Um array é uma estrutura de dados que contém uma série de dados ordenados, chamados "elementos". Os elementos são referenciados por número ordinal (índice), primeiro elemento é 0, segundo 1, etc.
Os elementos podem ser de qualquer tipo, string, char, int, double, etc...
No C# os arrays possuem o índice com base zero, ou seja, o primeiro elemento do array possui o índice zero (0).
Um array de uma dimensão é declarado informando o tipo de dados do array seguido do nome do array, lembrando que devemos colocar colchetes [] depois do tipo do array e não após o seu nome:
int[] numeros = {1, 2}; // Cria um array de 2 posições contendo os valores que passamos dentro das chaves
var numeros = new int[10]; // Cria um array com 10 posições mas nenhum elemento iniciado
Para definir os valores de um array que definimos sem nenhum valor, basta atribuir um valor a um índice específico, atribuindo o tipo correto aquele índice:
numeros[0] = 1;
numeros[1] = 2;
numeros[2] = 3;
numeros[7] = 4;
numeros[9] = 10;
Para acessarmos os valores de um array, seguimos a mesma lógica da atribuição de valor, onde usamos o índice que desejamos acessar para ter acesso ao valor que está atribuído a aquela poição do array:
Console.WriteLine(numeros[0]); // Valor: 1
Console.WriteLine(numeros[9]); // Valor: 10
Console.WriteLine(numeros[2]); // Valor: 3
Mas acessar todos os elementos de um array manualmente é quase impossível, sendo que podemos ter arrays gigantes com muitos elementos e não queremos ter que escrever uma linha de código para acessar cada um desses valores, pra isso usamos os laços de repetição:
For
using System;
public class Program
{
public static void Main()
{
string[] carros = {"Volvo", "BMW", "Ford", "Mazda"};
for (int i = 0; i < carros.Length; i++)
{
Console.WriteLine(carros[i]);
}
}
}
Foreach
using System;
public class Program
{
public static void Main()
{
string[] carros = {"Volvo", "BMW", "Ford", "Mazda"};
foreach(var carro in carros)
{
Console.WriteLine(carro);
}
}
}
Para um array de mais de uma dimensão a sintaxe usada para instanciá-lo pode ser:
string[,] nomes = new string[5,4]; // Declara um array bidimensional com 5 linhas e 4 colunas
int [,] matriz = new int [3,4] {
{0, 1, 2, 3} , /* inicia a linha indexada por 0 */
{4, 5, 6, 7} , /* inicia a linha indexada por 1 */
{8, 9, 10, 11} /* inicia a linha indexada por 2 */
};
Para o acesso de dados ou atribuição de valores em um array bidimencional, seguimos a mesma lógica de um array comum, porém agora sempre temos que prestar atenção na linha e coluna que queremos referenciar:
using System;
public class Program
{
public static void Main()
{
int[, ] a = new int[5, 2]{{0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}};
for (int i = 0; i < 5; i++)
{
for (int j = 0; j < 2; j++)
{
Console.WriteLine("a[{0},{1}] = {2}", i, j, a[i, j]);
}
}
/*
Saída:
a[0,0] = 0
a[0,1] = 0
a[1,0] = 1
a[1,1] = 2
a[2,0] = 2
a[2,1] = 4
a[3,0] = 3
a[3,1] = 6
a[4,0] = 4
a[4,1] = 8
*/
}
}
O C# é uma das linguagens de programação que oferece suporte a tipos nullables, ou seja, de um modo prático quer dizer que conseguimos iniciar objetos e variáveis e não atribuir valor algum a eles. Basicamente o que fazemos é reservar um espaço na memória que está apontando temporariamente para nenhum valor.
Essa implementação tem dois lados, um que pode facilitar nossa vida, e outro que pode atrapalhar. Podemos iniciar variáveis como:
int? x = null;
O que pode ser bom, se temos a necessidade de iniciar uma variável x sem valor temporariamente por algum motivo. Porém, se em algum ponto do sistema tentarmos fazer alguma operação com essa variável x, sem ainda ter atribuído um valor a ela, temos a temida NullReferenceException, que indica que tentamos acessar um valor na memória que não existe.
Isso pode causar muitos problemas, então temos que prestar muita atenção em como manipulamos os dados para não caírmos nessa falha.
No C#, basicamente todos os tipos podem ser nullables, apenas o identificando-os com o caracter ? depois da declaração de seu tipo.
int? x = null;
double? x = null;
DateTime? x = null;
string? x = null;
Todos os objetos que implementam esse comportamento nullable, tem seu valor padrão como
null, que pode ser diferente do seu tipo "não nullable", e implementam a funçãoHasValuee a propriedadeValue, para checagem e uso do valor respectivamente.
Tipos de valor e tipos de referência são as duas principais categorias de tipos do C#.
Uma variável de um tipo de valor, contém uma instância do tipo. Isso é diferente de uma variável de um tipo de referência, que contém uma referência a uma instância do tipo.
Ou seja, simplificando, cada variável do tipo de valor contém sua própria referência exclusiva, e mesmo quando copiada, não compartilha essa referência, ficando a cargo do CLR criar um novo local de armazenamento para a nova variável.
Por padrão, na atribuição, passando um argumento para um método e retornando um resultado de método, valores de variáveis são copiados. No caso de variáveis de tipo de valor, as instâncias de tipo correspondentes são copiadas. O exemplo a seguir demonstra esse comportamento:
using System;
public struct MutablePoint
{
public int X;
public int Y;
public MutablePoint(int x, int y) => (X, Y) = (x, y);
public override string ToString() => $"({X}, {Y})";
}
public class Program
{
public static void Main()
{
var p1 = new MutablePoint(1, 2);
var p2 = p1;
p2.Y = 200;
Console.WriteLine($"{nameof(p1)} after {nameof(p2)} is modified: {p1}");
Console.WriteLine($"{nameof(p2)}: {p2}");
MutateAndDisplay(p2);
Console.WriteLine($"{nameof(p2)} after passing to a method: {p2}");
}
private static void MutateAndDisplay(MutablePoint p)
{
p.X = 100;
Console.WriteLine($"Point mutated in a method: {p}");
}
}
// Expected output:
// p1 after p2 is modified: (1, 2)
// p2: (1, 200)
// Point mutated in a method: (100, 200)
// p2 after passing to a method: (1, 200)
Variáveis de tipos de referência armazenam referências em seus dados (objetos) enquanto que variáveis de tipos de valor contém diretamente seus dados. Com tipos de referência, duas variáveis podem fazer referência ao mesmo objeto, portanto, operações em uma variável podem afetar o objeto referenciado pela outra variável. Com tipos de valor, cada variável tem sua própria cópia dos dados e as operações em uma variável não podem afetar a outra.
Ou seja, simplificando, um tipo de referência na verdade está apontada para um endereço de memória que contém o seu valor de fato, quando copiamos uma variável deste tipo, estamos copiando este endereço, e não seu valor, sendo assim, quando alteramos os valores de uma dessas copias, o valor é alterado nas duas instâncias, já que elas apontam para o mesmo endereço de memória.
As palavras-chave são identificadores reservados predefinidos com significados especiais para o compilador. Elas não podem ser usadas como identificadores em seu programa, a não ser que incluam @ como prefixo. Por exemplo, @if é um identificador válido, mas if não é porque if é uma palavra-chave.
Abaixo está uma lista com algumas palavras-chaves mais conhecidas do C#:
| abstract | namespace | new | struct |
| as | event | null | switch |
| base | explicit | object | this |
| bool | extern | operator | throw |
| break | false | out | true |
| byte | finally | override | try |
| case | fixed | params | typeof |
| catch | float | private | uint |
| char | for | protected | ulong |
| checked | foreach | public | unchecked |
| class | goto | readonly | unsafe |
| const | if | ref | ushort |
| continue | implicit | return | using |
| decimal | in | sbyte | virtual |
| default | int | sealed | void |
| delegate | interface | short | volatile |
| do | internal | sizeof | while |
| double | is | stackalloc | |
| else | lock | static | |
| enum | long | string |
Use os modificadores de acesso, public, protected, internal ou private, para especificar um dos níveis de acessibilidade declarada a seguir para membros.
| Acessibilidade declarada | Significado |
|---|---|
| public | O acesso não é restrito. |
| protected | O acesso é limitado à classe que os contém ou aos tipos derivados da classe que os contém. |
| internal | O acesso é limitado ao assembly atual. |
| protected internal | O acesso é limitado ao assembly atual ou aos tipos derivados da classe que os contém. |
| private | O acesso é limitado ao tipo recipiente. |
| private protected | O acesso é limitado à classe que o contém ou a tipos derivados da classe que o contém no assembly atual. Disponível desde o C# 7.2. |
Um método, ou uma função, é um bloco de código que contém uma série de instruções. Um programa faz com que as instruções sejam executadas chamando o método e especificando os argumentos de método necessários. No C#, todas as instruções executadas são realizadas no contexto de um método.
O método Main é o ponto deentrada para cada aplicativo C# e échamado pelo Common Language Runtime (CLR) quando o programa é iniciado.
Um programa desenvolvido em C# segue uma estrutura padrão que é adotada por todas as aplicações, e consiste na seguintes partes:
- Um namespace;
- Uma classe;
- Um método Main;
- Declaração de usings;
Que podemos ver aqui:
using System;
namespace AppAcademy
{
public class Program
{
public static void Main()
{
Console.WriteLine("Hello World");
}
}
}
Quando esse código é executado, o resultado é o seguinte:
Hello World
Agora vamos destrinchar linha por linha nosso código e ver o que cada linha faz:
- A primeira linha do progama: "using System;", a palavra-chave using é usada para incluir o namespace System no programa;
- Próxima linha, a declaração do namespace: Um namespace é uma coleção de classes, o namespace AppAcademy contém a classe Program;
- A proxima linha define a classe Program, essa contém os dados e definições de métodos que o nosso programa usa;
- A quarta linha define o método Main, que é o ponto de entrada para todas as aplicações desenvolvidas com C#;
Os métodos são declarados em uma classe, struct ou interface especificando o nível de acesso como public ou private, modificadores opcionais, como abstract ou sealed, o tipo de valor de retorno, o nome do método e seus parâmetros. Juntas, essas partes são a assinatura do método.
abstract class Moto
{
// Qualquer um tem acesso
public void Ligar()
{
}
// Somente classes derivadas de Moto tem acesso
protected void Abastecer(int litros)
{
}
// Classes derivadas tem acesso e podem sobrecarregar este método
public virtual int Andar(int distancia, int velocidade)
{
return 1;
}
// Classes derivadas devem implementar este método
public abstract double VelocidadeMaxima();
}
Chamar um método em um objeto é como acessar um campo. Após o nome do objeto, adicione um ponto final, o nome do método e parênteses. Os argumentos são listados dentro dos parênteses e são separados por vírgulas.
Os métodos da classe Moto podem, portanto, ser chamados como no exemplo a seguir:
using System;
class MotoTest : Moto
{
public override double VelocidadeMaxima()
{
return 108.4;
}
}
public class Program
{
public static void Main()
{
MotoTest moto = new MotoTest();
moto.Ligar();
moto.Abastecer(15);
moto.Andar(5, 20);
double speed = moto.VelocidadeMaxima();
Console.WriteLine("A velocidade máxima é: {0}", speed);
}
}
A definição do método especifica os nomes e tipos de quaisquer parâmetros obrigatórios. Quando o código de chamada chama o método, ele fornece valores concretos, chamados argumentos, para cada parâmetro. Os argumentos devem ser compatíveis com o tipo de parâmetro, mas o nome do argumento (se houver) usado no código de chamada não precisa ser o mesmo que o parâmetro nomeado definido no método.
Por padrão, quando uma instância de um tipo de valor é passada para um método, sua cópia é passada em vez da própria instância. Portanto, as alterações no argumento não têm efeito sobre a instância original no método de chamada. Para passar uma instância de tipo de valor por referência, use a palavra-chave ref.
Quando um objeto detipo dereferência é passado para um método, uma referência ao objeto é passada. Ou seja, o método recebe não o objeto em si, mas um argumento que indica o local do objeto. Se você alterar um membro do objeto usando essa referência, a alteração será refletida no argumento no método de chamada, ainda que você passe o objeto por valor.
using System;
public class Program
{
public static void Method(ref int refArgument)
{
refArgument = refArgument + 44;
}
public static void Main()
{
int number = 1;
Method(ref number);
Console.WriteLine(number); // Saída: 45
}
}
Quando usamos um tipo de valor, é passada para um método, sua cópia é passada em vez da própria instância. Portanto, as alterações no argumento não têm efeito sobre a instância original no método de chamada.
using System;
public class Program
{
public static void Method(int arg)
{
arg = arg + 44;
}
public static void Main()
{
int number = 1;
Method(number);
Console.WriteLine(number); // Saída: 1
}
}
A palavra-chave in faz com que os argumentos sejam passados por referência, mas garante que o argumento não seja modificado.
Ela torna o parâmetro um alias para o argumento, que deve ser uma variável. Em outras palavras, qualquer operação no parâmetro é feita no argumento. É como as palavras-chave ref ou out, exceto que os argumentos in não podem ser modificados pelo método chamado.
using System;
public class Program
{
public static void Method(in int arg)
{
// Se descomentarmos essa linha, vemos o erro "Cannot assign to variable 'in int' because it is a readonly variable"
// Porque estamos tentando alterar o valor de uma parâmetro de entrada
// arg = arg + 44;
}
public static void Main()
{
int number = 1;
Method(number);
Console.WriteLine(number); // Saída: 1
}
}
A palavra-chave out faz com que os argumentos sejam passados por referência.
Ela torna o parâmetro um alias para o argumento, que deve ser uma variável. Em outras palavras, qualquer operação no parâmetro é feita no argumento. É como a palavra-chave ref, exceto pelo fato de que ref requer que a variável seja inicializada antes de ser passada.
using System;
public class Program
{
public static void OutArgExample(out int number)
{
number = 44;
}
public static void Main()
{
int initializeInMethod;
OutArgExample(out initializeInMethod);
Console.WriteLine(initializeInMethod); // Saída: 44
}
}
Os métodos de extensão ou extensions methods são uma implementação do padrão de projeto estrutural Composite e permitem que você adicione uma nova funcionalidade a um tipo de dado que já foi definido sem ter que criar um novo tipo derivado; dessa forma a funcionalidade se comporta como um outro membro do tipo.
using System;
namespace AppAcademy
{
public static class Program
{
public static void Main()
{
string str = "Minha string";
Console.WriteLine(str.RemoveLetrasA()); // Saída: Minh string
}
}
public static class MetodosDeExtensao
{
public static string RemoveLetrasA(this string args)
{
return args.Replace("a", "");
}
}
}
O desenvolvimento de software é extremamente amplo. Nesse mercado, existem diversas linguagens de programação, que seguem diferentes paradigmas. Um desses paradigmas é a Orientação a Objetos, que atualmente é o mais difundido entre todos. Isso acontece porque se trata de um padrão que tem evoluído muito, principalmente em questões voltadas para segurança e reaproveitamento de código, o que é muito importante no desenvolvimento de qualquer aplicação moderna.
O que é um paradigma de programação?
Um paradigma pode ser entendido como a forma com a qual se decide resolver determinado problema por meio da programação de computadores. Nesse sentido, temos alguns paradigmas possíveis que eventualmente podem ser usados mais de um (caso a linguagem escolhida ofereça suporte).
O paradigma da POO (Programação Orientada a Objetos) é um modelo de análise, projeto e programação baseado na aproximação entre o mundo real e o mundo virtual, através da criação e interação entre objetos, atributos, códigos, métodos, entre outros.
A programação orientada a objetos tem o propósito principal de aproximar o mundo lógico da programação e o mundo em que vivemos. À vista disso, ela parte do princípio de que tudo é objeto — isso mesmo, tudo o que existe são os objetos.
Uma classe é um gabarito para a definição de objetos. Através da definição de uma classe, descreve-se que propriedades ou atributos o objeto terá.
Uma classe mantém dois elementos importantes: estrutura e comportamento.
- Uma estrutura representa os atributos que descrevem a classe.
- Um comportamento representa os serviços que a classe suporta.
Imagine que você queira representar uma pessoa como um objeto de um sistema, olhando para essas duas palavras estrutura e comportamento, como poderíamos fazer essa representação?
Estrutura
Como podemos pensar na estrutura para que possamos representar uma pessoa, dentro de um sistema de computador?
Bom, primeiro teríamos que saber quais tipos de dados que nosso sistema precisa para poder representar uma pessoa do jeito mais simples e coeso o possível. Poderíamos falar que um objeto de pessoa tem dois braços, duas pernas, duas mãos com cinco dedos em cada uma, cabelo, nariz, boca, orelha e assim por diante... Mas qual a utilidade desses dados no nosso sistema?
Digamos que nosso sistema é um sistema de cadastro para promoção de uma padaria, quais dados precisamos para representar cada pessoa nesse cadastro?
Agora já temos uma ideia melhor de onde começar, e do que precisamos. Vamos representar uma pessoa com os seguintes dados: Nome, Sobrenome, Idade, CPF e Telefone.
Então a estrutura da nossa classe ja foi definida. Vamos pensar no seu comportamento.
Comportamento
No contexto que definimos, um cadastro para sorteio de uma padaria, quais comportamentos uma pessoa assume?
Bom, podemos dizer que ela realiza o cadastro no sorteio, e pode verificar o resultado no dia do mesmo.
Então definimos os dois comportamentos da nossa classe. E podemos representar ela desse jeito:
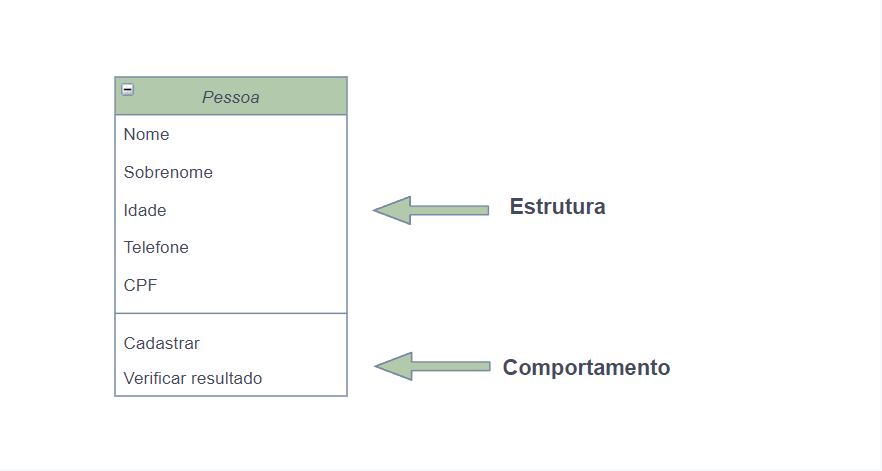
O reuso de código é uma das grandes vantagens da programação orientada a objetos. Muito disso se dá por uma questão que é conhecida como herança. Essa característica otimiza a produção da aplicação em tempo e linhas de código.
A herança é um mecanismo que permite que características comuns a diversas classes sejam agrupadas em uma classe base, ou superclasse. A partir de uma classe base, outras classes podem ser especificadas. Cada classe derivada ou subclasse apresenta as características (estrutura e métodos) da classe base e acrescenta a elas o que for definido de particularidade para ela.
Imaginamos a classe pessoa que descrevemos, nesse momento, somente definimos uma pessoa como um cliente/participante do sorteio, porém, podemos pensar também que existe um tipo de pessoa que está gerindo esse sorteio, como um funcionario da padaria.
Porém, esse funcionário tem uma estrutura muito parecida com um cliente da padaria, eles compartilham sua estrutura base. Para não termos duas definição de classe pessoa, uma para o cliente, e outra para o funcionário, usamos da herança para definir uma classe base com os dados compartilhados entre esses dois objetos, e implementamos, para cada tipo de pessoa diferente um novo tipo, que herda dessa classe base:
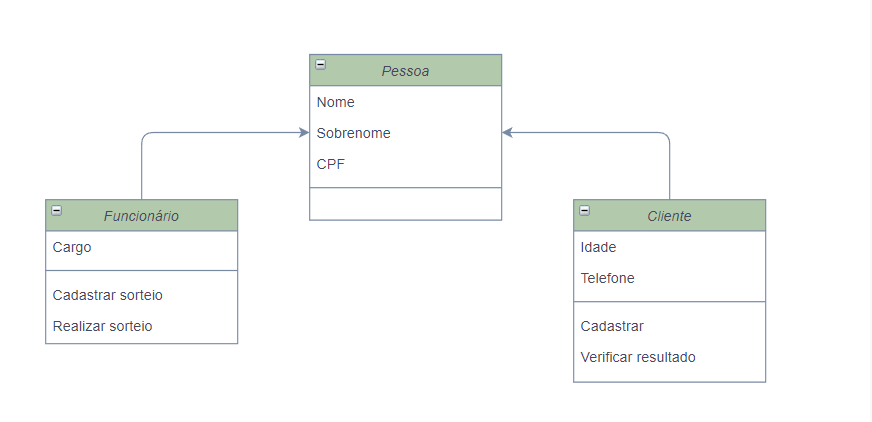
Veja que a classe base pessoa passou a ter somente os dados que os tipos funcionario e cliente compartilham, ficando a cargo de cada uma agora, implementar os dados pertinentes ao seu tipo, como o cargo do funcionário, ou o telefone do cliente.
O encapsulamento é uma das principais técnicas que define a programação orientada a objetos. Se trata de um dos elementos que adicionam segurança à aplicação em uma programação orientada a objetos pelo fato de esconder as propriedades, criando uma espécie de caixa preta.
O encapsulamento ele define que cada objeto contém todos os detalhes de implementação necessários sobre como ele funciona e oculta os detalhes internos sobre como ele executa os serviços.
No exemplo das nossas classes de pessoa, o comportamento de cada um está encapsulado dentro de seus métodos e propriedades específicas, podemos usar um outro exemplo para exemplificar:
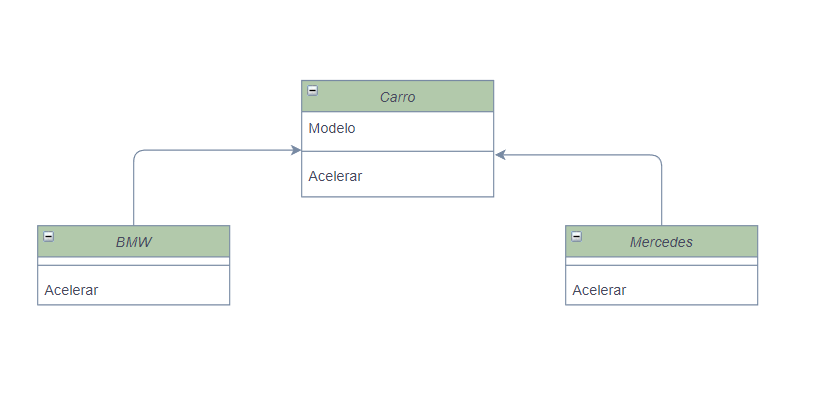
No diagrama temos definida a classe base Carro, e duas outras que fazem herança da mesma, BMW e Mercedes.
Note que dentro da classe base, foi definida uma função, ou comportamento, Acelerar, que é comum para todos os carros. Mas todos os carros fazem isso de um jeito diferente, um carro pode ter um acelerador elétrico, o outro a cabo e assim por diante, mas usando corretamente o encapsulamento todos os carros implementam esse comportamento, sem se preocupar com o que o outro objeto está fazendo, cada objeto que implementa essa classe base encapsula a função de acelerar, e pela perspectiva de um carro, todos eles aceleram, sem necessariamente saber como o processo é desenvolvido por baixo dos panos.
Outro ponto essencial na programação orientada a objetos é o chamado polimorfismo. Na natureza, vemos animais que são capazes de alterar sua forma conforme a necessidade, e é dessa ideia que vem o polimorfismo na orientação a objetos. Como sabemos, os objetos filhos herdam as características e ações de seus “ancestrais”. Entretanto, em alguns casos, é necessário que as ações para um mesmo método seja diferente. Em outras palavras, o polimorfismo consiste na alteração do funcionamento interno de um método herdado de um objeto pai.
Como um exemplo, podemos definir um objeto base Animal, e algumas outras classes que herdam dessa classe.
A classe Animal tem um comportamento que se chama Falar, e toda classe que herda desta deve implementar essa função conforme necessário:
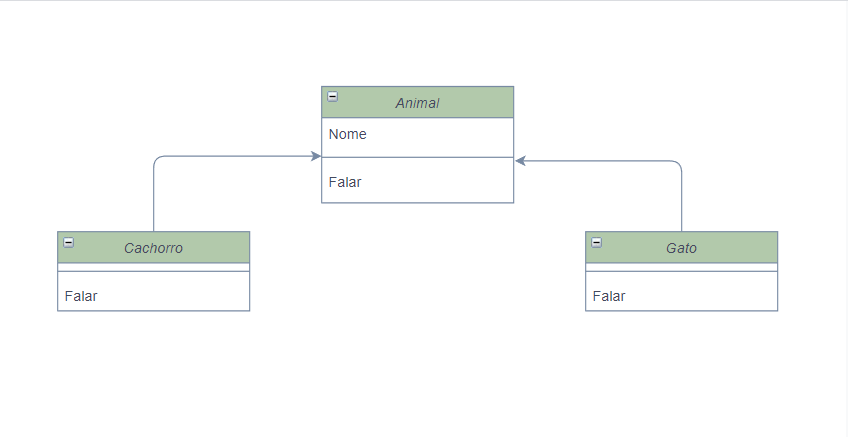
Podemos considerar que quando um objeto da classe Cachorro implementar a função Falar, será diferente da implementação da classe Gato.
Também chamada de interface ou template. Muitos simplificam sua explicação como sendo uma espécie de mistura de encapsulamento e polimorfismo. A ideia principal é representar um objeto de forma abstrata, que seja obrigatoriamente herdado por outras classes.
Como nos exemplos anteriores, usamos a abstração para criar um contrato na classe base, e obrigamos as classes que herdam dela a implementa-los, como vimos na função Falar do animal, ou Acelerar do carro.
Para facilitar nossa vida o C# implementou um sistemas de listas mais avançados do que os arrays e matrizes que já vimos. Foram desenvolvidadas várias interfaces, que tem como base a IEnumerable<T>, e essas oferecem várias vantagens para nós programadores e torna nossa vida mais prática, como o uso do LINQ, métodos de extensões, gerenciamento de memória entre outras coisas...
Uma lista, ao contrário de um array, tem o tamanho dinâmico, não é necessário definir o tamanho de uma lista no momento da sua criação, automaticamente, conforme necessidade, é alocado mais espaço na memória para comportar nosso objeto.
Existem vários tipos de listas por padrão no C#, e isso confunde um pouco qual tipo de lista escolher para cada situação, vamos falar das mais comuns:
IList<T>
É a mais comum, oferece mais métodos e liberdade para realizar operações na lista em troca de uma performance razoável.
IEnumerable<T>
Das interfaces é a mais comum, como já dito, é a interface base para todas as listas, então é bastante usada como retorno de funções, onde o chamador da função pode fazer a conversão da mesma para outro tipo de lista como o List\<T>.
IReadOnlyCollection<T>
É muito usada quando precisamos iniciar uma lista no momento da criação de um objeto por exemplo, e não queremos que esses dados sejam modificados posteriormente, é uma lista somente leitura.
IDictionary<T>
É também uma das mais conhecidas, quando precisamos de uma lista de chave-valor, onde a chave não pode se repetir.
Para instanciarmos uma lista, temos que usar o namespace System.Collections.Generic, e podemos declará-la das seguintes maneiras:
var list = new List<string>() {"a", "b", "c", "d"};
List<string> list = new List<string>() {"a", "b", "c", "d"};
List<string> list = new List<string>();
List<string> list = null;
Diferente dos arrays, não precisamos definir o tamanho da lista no momento da sua criação.
Adicionando valores em uma lista:
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
list.Add('e');
list.Add('f');
list.Add('g');
list.ForEach(x => {
Console.WriteLine(x);
});
}
}
Iterando os valores de uma lista:
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
// Podemos usar essa sintaxe do foreach
foreach(var chr in list)
{
Console.WriteLine(chr);
}
// Ou essa outra
list.ForEach(x => {
Console.WriteLine(x);
});
// Acessando o valor como num array usando colchetes e o index
for (int i = 0; i < list.Count; i++)
{
Console.WriteLine(list[i]);
}
}
}
Removendo valores de uma lista:
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
list.Remove('a');
list.ForEach(x => {
Console.WriteLine(x);
});
}
}
Como já foi mencionado, junto com as listas, o C# oferece um namespace System.Linq onde ficam as operações do LINQ ou Language-Integrated Query, que permitem uma padronização de como as listas são manipuladas no C#.
O LINQ oferece vários métodos de extensão que permitem a manipulação de listas de um jeito prático, assim também como uma sintaxe própria, semelhante ao SQL que também pode ser usada nos aplicativos do .Net.
Vamos ver os métodos mais usados da biblioteca:
Where
O método Where faz a busca na lista baseado na expressão que é passada por parâmetro:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd', 'a'};
var chrs = list.Where(c => c == 'a');
foreach(var chr in chrs)
{
Console.WriteLine(chr);
}
}
}
Any
O método Any verrifica se existe alguma ocorrência na lista baseado na expressão passada por parâmetro e retorna True caso exista ou False caso não:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd', 'a'};
Console.WriteLine(list.Any(c => c == 'a'));
}
}
First
O método First busca o primeiro elemento da lista, ou o primeiro elemento a satisfazer a expressão passada por parâmetro:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd', 'a'};
Console.WriteLine(list.First(c => c == 'a'));
}
}
SingleOrDefault;
O método SingleOrDefault busca o primeiro e único elemento da lista ou o null caso vazio, ou o primeiro elemento a satisfazer a expressão passada por parâmetro, caso haja mais de um elemento que satisfaça a mesma condição, uma excessão será lançada:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
Console.WriteLine(list.SingleOrDefault(c => c == 'a'));
}
}
FirstOrDefault
O método FirstOrDefault busca o primeiro elemento da lista ou o null caso vazio, ou o primeiro elemento a satisfazer a expressão passada por parâmetro, ao contrário do SingleOrDefault, caso haja mais de um elemento que satisfaça a mesma condição, nenhuma excessão será lançada:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd', 'a'};
Console.WriteLine(list.FirstOrDefault(c => c == 'a'));
}
}
Count
O método Count retorna o número total de elementos da lista, ou o número total de elementos da lista a satisfazer a expressão passada por parâmetro:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd', 'a'};
Console.WriteLine(list.Count(c => c == 'a'));
}
}
GroupBy
O método GroupBy retorna uma nova lista onde os valores são agrupados pelos valores que foram passados por parametro:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
Console.WriteLine(list.GroupBy(c => c));
}
}
Select
O método Select retorna uma nova lista onde os valores são resultado das propriedades ou objeto anônimo passado por parametro:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
Console.WriteLine(list.Select(c => new { NovaString = c.ToString() } ).First());
}
}
Contains
O método Contains verifica se uma lista está contida dentro de outra, ou contém um elemento específico, e retorna True caso sim ou False caso não:
using System;
using System.Linq;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var list = new List<char>() {'a', 'b', 'c', 'd'};
Console.WriteLine(list.Contains('a'));
}
}
Hoje em dia, a programação assíncrona é muito popular com a ajuda das palavras-chave async e await no C#.
É possível evitar gargalos de desempenho e aprimorar a resposta geral do seu aplicativo usando a programação assíncrona. No entanto, as técnicas tradicionais para escrever aplicativos assíncronos podem ser complicadas, dificultando sua escrita, depuração e manutenção.
O C# 5 apresentou uma abordagem de programação assíncrona simplificada que aproveita o suporte assíncrono no .NET Framework 4.5 e superior, no .NET Core e no Windows Runtime. O compilador faz o trabalho difícil que o desenvolvedor costumava fazer, e seu aplicativo mantém a estrutura lógica que se assemelha ao código síncrono. Como resultado, você obtém todas as vantagens da programação assíncrona com uma fração do esforço.
A assincronia é essencial para atividades que potencialmente podem bloquear o fluxo de um aplicativo, como o consumo de serviços de outra rede. O acesso a um recurso de uma rede externa muitas vezes é lento. Se tal atividade for bloqueada por um processo síncrono, todo o aplicativo deverá esperar. Em um processo assíncrono, o aplicativo poderá prosseguir com outro trabalho que não dependa desse recurso até a tarefa potencialmente causadora do bloqueio terminar.
As palavras-chave async e await em C# são a parte central da programação assíncrona. Usando essas duas palavras-chave, você pode usar recursos no .NET Framework, no .Net Core para criar um método assíncrono quase tão fácilmente quanto criar um método síncrono. Os métodos assíncronos que você define usando a palavra-chave async são chamados de métodos assíncronos.
As classes Task e Task<T> são o núcleo da programação assíncrona em .NET. Elas facilitam todos os tipos de interações com a operação assíncrona que representam, como:
- Adicionando tarefas de continuação;
- Bloqueando a thread atual para esperar até que a tarefa seja concluída;
- Sinalização de cancelamento (via CancelamentoTokens);
Depois de iniciar uma operação assíncrona e obter um objeto Task ou Task<T>, você pode continuar usando a thread de execução atual para executar de forma assíncrona outras instruções que não precisam do resultado da tarefa, ou interagir com a tarefa conforme necessário.
As palavras-chave async e await também são essenciais para a programação assíncrona em .Net. Elas não representam outra forma de programação assíncrona, mas usam as classes Task e Task<T> debaixo dos panos, simplificando a aplicação enquanto mantêm o poder que as classes Task fornecem ao programador quando necessário.
A palavra-chave async é adicionada à assinatura do método para permitir o uso da palavra-chave await no método. Ele também instrui o compilador a criar uma máquina de estado para lidar com a assincronicidade.
O tipo de retorno de um método assíncrono é sempre Task ou Task<T>.
A palavra-chave await é usada para esperar de forma assíncrona pela conclusão de uma Task ou Task<T>.
Ele pausa a execução do método atual até que a tarefa assíncrona que está sendo aguardada seja concluída. A diferença de chamar .Result ou .Wait() é que a palavra-chave await envia a thread atual de volta ao pool de threads, em vez de mantê-lo em um estado bloqueado.
Com o crescimento do uso da internet e a facilidade de acesso a web, hoje em dia quase não se fala mais em programas desktop, ou seja, programas que instalamos nos nossos computadores. Esses programas ficam instalados nos computadores e ocupam espaço em disco, não recebem atualizações, alocam espaço em memória, e etc...
Por isso vimos um grande crescimento dos serviços disponibilizados pela Web, os SaaS ou Software as a Service. Esse tipo de aplicação web permite que um sistema ou aplicativo possa ser acessado de qualquer lugar do mundo, de qualquer dispositivo, necessitando apenas de um nagevador e acesso a internet. Toda a infraestrutura fica a cargo dos criadores do aplicativo, e atualizações e melhorias podem ocorrer no meio do dia sem nenhum impacto para os usuários.
API é um conjunto de definições e protocolos usado no desenvolvimento e na integração de software de aplicações. API é um acrônimo em inglês que significa interface de programação de aplicações.
Uma API permite que sua solução ou serviço se comunique com outros produtos e serviços sem precisar saber como eles foram implementados. Isso simplifica o desenvolvimento de aplicações, gerando economia de tempo e dinheiro. Ao desenvolver novas ferramentas e soluções (ou ao gerenciar aquelas já existentes), as APIs oferecem a flexibilidade necessária para simplificar o design, a administração e o uso, além de fornecer oportunidades de inovação.
REST não é um protocolo ou padrão, mas sim um conjunto de restrições de arquitetura. Os desenvolvedores de API podem implementar a arquitetura REST de maneiras variadas.
Quando um cliente faz uma solicitação usando uma API RESTful, essa API transfere uma representação do estado do recurso ao solicitante ou endpoint.
O Hypertext Transfer Protocol, sigla HTTP (em português Protocolo de Transferência de Hipertexto) é um protocolo de comunicação utilizado para sistemas de informação de hipermídia, distribuídos e colaborativos. Ele é a base para a comunicação de dados da internet.
O protocolo HTTP define oito métodos (GET, HEAD, POST, PUT, DELETE, TRACE, OPTIONS e CONNECT) que indicam a ação a ser realizada no recurso especificado. O método determina o que o servidor deve fazer com o URL fornecido no momento da requisição de um recurso. Os métodos GET e POST são os que aparecem mais comumente durante o desenvolvimento web.
Em computação, JSON, um acrônimo de JavaScript Object Notation, é um formato compacto, de padrão aberto independente, de troca de dados simples e rápida (parsing) entre sistemas, que utiliza texto legível a humanos, no formato atributo-valor.
Os testes representam uma etapa de extrema importância no processo de desenvolvimento de software, pois visam validar se a aplicação está funcionando corretamente e se atende aos requisitos especificados.
Nesse contexto existem diversas técnicas que podem ser aplicadas em diferentes momentos e de diferentes formas para validar os aspectos principais do software. Vamos ver algumas delas a seguir.
Testes de Unidade ou teste unitário é a fase de testes onde cada unidade do sistema é testada individualmente. O objetivo é isolar cada parte do sistema para garantir que elas estejam funcionando conforme especificado.
Dessa forma, o desenvolvedor que fará a avaliação deve sempre pensar em quais requisitos aquela funcionalidade a ser testada tem que corresponder, qual deve ser entrada e saída de informações e, também, como funciona o processamento do fluxo daqueles dados.
Este tipo de teste é da responsabilidade do próprio programador durante a implementação, isto é, após codificar uma classe por exemplo, seria executado o teste de unidade.
Teste de integração é a fase do teste de software em que módulos são combinados e testados em grupo. Ela sucede o teste de unidade, em que os módulos são testados individualmente, e antecede o teste de sistema, em que o sistema completo (integrado) é testado num ambiente que simula o ambiente de produção.
Além desses dois tipos de teste mais comum, existem mais vários tipos de testes que podem ser aplicados em um software:
Teste de Unidade: Teste em um nível de componente ou classe. É o teste cujo objetivo é um “pedaço do código”.
Teste de Integração: Garante que um ou mais componentes combinados (ou unidades) funcionam. Podemos dizer que um teste de integração é composto por diversos testes de unidade.
Teste Operacional: Garante que a aplicação pode rodar muito tempo sem falhar.
Teste Positivo-negativo: Garante que a aplicação vai funcionar no “caminho feliz” de sua execução e vai funcionar no seu fluxo de exceção.
Teste de Regressão: Toda vez que algo for mudado, deve ser testada toda a aplicação novamente.
Teste de Caixa-preta: Testar todas as entradas e saídas desejadas. Não se está preocupado com o código, cada saída indesejada é visto como um erro.
Teste Caixa-branca: O objetivo é testar o código. Às vezes, existem partes do código que nunca foram testadas.
Teste Funcional: Testar as funcionalidades, requerimentos, regras de negócio presentes na documentação. Validar as funcionalidades descritas na documentação (pode acontecer de a documentação estar inválida)
Teste de Interface: Verifica se a navegabilidade e os objetivos da tela funcionam como especificados e se atendem da melhor forma ao usuário.
Teste de Performance: Verifica se o tempo de resposta é o desejado para o momento de utilização da aplicação.
Teste de Carga: Verifica o funcionamento da aplicação com a utilização de uma quantidade grande de usuários simultâneos.
Teste de Aceitação do usuário: Testa se a solução será bem vista pelo usuário. Ex: caso exista um botão pequeno demais para executar uma função, isso deve ser criticado em fase de testes. (aqui, cabem quesitos fora da interface, também).
Teste de Volume: Testar a quantidade de dados envolvidos (pode ser pouca, normal, grande, ou além de grande).
Testes de Stress: Testar a aplicação sem situações inesperadas. Testar caminhos, às vezes, antes não previstos no desenvolvimento/documentação.
Testes de Configuração: Testar se a aplicação funciona corretamente em diferentes ambientes de hardware ou de software.
Testes de Instalação: Testar se a instalação da aplicação foi OK.
Testes de Segurança: Testar a segurança da aplicação das mais diversas formas. Utilizar os diversos papéis, perfis, permissões, para navegar no sistema.
Objetos mock, objetos simulados ou simplesmente mock (do inglês mock object) em desenvolvimento de software são objetos que simulam o comportamento de objetos reais de forma controlada. São normalmente criados para testar o comportamento de outros objetos. Em outras palavras, os objetos mock são objetos “falsos” que simulam o comportamento de uma classe ou objeto “real” para que possamos focar o teste na unidade a ser testada.
SQL é uma linguagem padrão para trabalhar com bancos de dados relacionais. Ela é uma linguagem declarativa e que não necessita de profundos conhecimentos de programação para que alguém possa começar a escrever queries, as consultas e pedidps, que trazem resultados de acordo com o que você está buscando. SQL significa Standard Query Language, literalmente a linguagem padrão para realizar queries.
A linguagem SQL é utilizada de maneira relativamente parecida entre os principais bancos de dados relacionais do mercado: Oracle, MySQL, MariaDB, PostgreSQL, Microsoft SQL Server, entre muitos outros. Cada um tem suas características, sendo o MySQL e o PostgreSQL extremamente populares por possuírem versões gratuitas e de código aberto.
Para instalarmos nosso banco de dados Oracle, vamos usar o docker para fazer o download da imagem e criar um container onde vai ser hospedada nosso servidor do banco de dados.
Esse comando irá fazer o download da imagem do Oracle Xe, criar um container e expor a porta 1521 para usarmos a base de dados de fora do container:
docker run -d -p 1521:1521 -e ORACLE_ALLOW_REMOTE=true --name Oracle -h Oracle oracleinanutshell/oracle-xe-11g
Vamos acessar o terminal de linha de comando do container com o seguinte comando:
docker exec -it Oracle "bash"
Podemos checar o status da nossa base com o seguinte comando:
lsnrctl status
Agora iremos criar uma nova "base" no Oracle, seguindo esses comandos:
/bin/sqlplus / as sysdba
O usuário e senha são system e oracle respectivamente.
Agora, executamos todos esses comandos para criar nossa base de teste:
CREATE USER AppAcademy IDENTIFIED BY AppAcademy;
GRANT CREATE SESSION TO AppAcademy;
GRANT CREATE VIEW TO AppAcademy;
GRANT CREATE ANY TRIGGER TO AppAcademy;
GRANT CREATE ANY PROCEDURE TO AppAcademy;
GRANT CREATE SEQUENCE TO AppAcademy;
GRANT CREATE SYNONYM TO AppAcademy;
GRANT ALL PRIVILEGES TO AppAcademy;
GRANT UNLIMITED TABLESPACE TO AppAcademy;
Para testarmos, podemos sair da sessão atual e logar no nosso novo usuário que foi criado:
/bin/sqlplus
E inserir o usuário e senha AppAcademy
Para acessar os dados de uma interface gráfica, podemos instalar o DBeaver
O primeiro grupo é a DML (Data Manipulation Language - Linguagem de manipulação de dados). DML é um subconjunto da linguagem SQL que é utilizado para realizar inclusões, consultas, alterações e exclusões de dados presentes em registros. Estas tarefas podem ser executadas em vários registros de diversas tabelas ao mesmo tempo. Os comandos que realizam respectivamente as funções acima referidas são INSERT, UPDATE e DELETE.
| função | comandos SQL | descrição do comando | exemplo |
|---|---|---|---|
| Inclusões | INSERT | é usada para inserir um registro (formalmente uma tupla) a uma tabela existente. | INSERT INTO Pessoa (id, nome, sexo) VALUE; |
| Alterações | UPDATE | para mudar os valores de dados em uma ou mais linhas da tabela existente. | UPDATE Pessoa SET data_nascimento = '11/09/1985' WHERE id_pessoa = 7; |
| Exclusões | DELETE | permite remover linhas existentes de uma tabela. | DELETE FROM pessoa WHERE id_pessoa = 7; |
O segundo grupo é a DDL (Data Definition Language - Linguagem de Definição de Dados). Uma DDL permite ao utilizador definir tabelas novas e elementos associados. A maioria dos bancos de dados de SQL comerciais tem extensões proprietárias no DDL.
- CREATE TABLE
- CREATE INDEX
- CREATE VIEW
- ALTER TABLE
- ALTER INDEX
- DROP INDEX
- DROP VIEW
- TRUNCATE TABLE
O terceiro grupo é o DCL (Data Control Language - Linguagem de Controle de Dados). DCL controla os aspectos de autorização de dados e licenças de usuários para controlar quem tem acesso para ver ou manipular dados dentro do banco de dados.
Duas palavras-chaves da DCL:
- GRANT - autoriza ao usuário executar ou setar operações.
- REVOKE - remove ou restringe a capacidade de um usuário de executar operações.
Os comandos DTL (Data Transaction Language - Linguagem de Transação de Dados) são responsáveis por gerenciar diferentes transações ocorridas dentro de um banco de dados.
- BEGIN TRANSACTION - pode ser usado para marcar o começo de uma transação de banco de dados que pode ser completada ou não.
- COMMIT - finaliza uma transação dentro de um sistema de gerenciamento de banco de dados.
- ROLLBACK - faz com que as mudanças nos dados existentes desde o último COMMIT ou ROLLBACK sejam descartadas.
COMMIT e ROLLBACK interagem com áreas de controle como transação e locação. Ambos terminam qualquer transação aberta e liberam qualquer cadeado ligado a dados. Na ausência de um BEGIN WORK ou uma declaração semelhante, a semântica de SQL é dependente da implementação.
Embora tenha apenas um comando, a DQL é a parte da SQL mais utilizada.
O comando SELECT permite ao usuário especificar uma consulta como uma descrição do resultado desejado. Esse comando é composto de várias cláusulas e opções, possibilitando elaborar consultas das mais simples às mais elaboradas.
As cláusulas são condições de modificação utilizadas para definir os dados que deseja selecionar ou modificar em uma consulta:
- FROM – Utilizada para especificar a tabela, que se vai selecionar os registros.
- WHERE – Utilizada para especificar as condições que devem reunir os registros que serão selecionados.
- GROUP BY – Utilizada para separar os registros selecionados em grupos específicos.
- HAVING – Utilizada para expressar a condição que deve satisfazer cada grupo.
- ORDER BY – Utilizada para ordenar os registros selecionados com uma ordem especifica.
- DISTINCT – Utilizada para selecionar dados sem repetição.
- UNION – combina os resultados de duas consultas SQL em uma única tabela para todas as linhas correspondentes.
- AND – E lógico. Avalia as condições e devolve um valor verdadeiro caso ambos sejam corretos.
- OR – OU lógico. Avalia as condições e devolve um valor verdadeiro se algum for correto.
- NOT – Negação lógica. Devolve o valor contrário da expressão.
O SQL possui operadores relacionais, que são usados para realizar comparações entre valores, em estruturas de controle.
| Operador | Descrição | Comando | Exemplos |
|---|---|---|---|
| < | Menor | SELECT * FROM informacao.tabela WHERE idade < 18; | Seleciona todos os registros na "tabela" que possuem o campo "idade" com valores menores que 18. |
| > | Maior | SELECT * FROM informacao.tabela WHERE idade > 18; | Seleciona todos os registros na "tabela" que possuem o campo "idade" com valores maiores que 18. |
| <= | Menor ou igual | SELECT * FROM informacao.tabela WHERE idade <= 18; | Seleciona todos os registros na "tabela" que possuem o campo "idade" com valores menores ou iguais à 18. |
| >= | Maior ou igual | SELECT * FROM informacao.tabela WHERE idade >= 18; | Seleciona todos os registros na "tabela" que possuem o campo "idade" com valores maiores ou iguais à 18. |
| = | Igual | SELECT * FROM informacao.tabela WHERE idade = 18; | Seleciona todos os registros na "tabela" que possuem o campo "idade" com valores exatamente iguais à 18. |
| <> | Diferente | SELECT * FROM informacao.tabela WHERE idade <> 18; | Seleciona todos os registros na "tabela" que possuem o campo "idade" com valores que são diferentes de 18. |
| BETWEEN | Entre o intervalo | SELECT * FROM informacao.tabela WHERE idade BETWEEN 18 AND 21 | Seleciona todos os registros na "tabela" que possuem o campo "idade" entre 18 e 21 |
| LIKE | "Parecido" | SELECT * FROM informacao.tabela WHERE nome LIKE '%JOÃO%' | Seleciona todos os registros na "tabela" que possuem o campo "nome" que contenha a palavra "JOÃO" |
| IN | Entre os valores | SELECT * FROM informacao.tabela WHERE idade IN (18, 19, 20) | Seleciona todos os registros na "tabela" que possuem o campo "idade" entre os valores 18, 19 e 20 |
As funções de agregação, como os exemplos abaixo, são usadas dentro de uma cláusula SELECT em grupos de registros para devolver um único valor que se aplica a um grupo de registros:
- AVG – Utilizada para calcular a média dos valores de um campo determinado.
- COUNT – Utilizada para devolver o número de registros da seleção.
- SUM – Utilizada para devolver a soma de todos os valores de um campo determinado.
- MAX – Utilizada para devolver o valor mais alto de um campo especificado.
- MIN – Utilizada para devolver o valor mais baixo de um campo especificado.
- STDDEV - Utilizada para funções estatísticas de desvio padrão
- VARIANCE - Utilizada para funções estatísticas de variância
Uma cláusula JOIN é usada para combinar linhas de duas ou mais tabelas, com base em uma coluna relacionada entre elas.
- (INNER) JOIN: Retorna registros que possuem valores correspondentes em ambas as tabelas.
- LEFT (OUTER) JOIN: Retorna todos os registros da tabela da esquerda e os registros correspondentes da tabela da direita.
- RIGHT (OUTER) JOIN: Retorna todos os registros da tabela da direita e os registros correspondentes da tabela da esquerda.
- FULL (OUTER) JOIN: Retorna todos os registros quando há uma correspondência na tabela da esquerda ou da direita.
Uma Subquery (também conhecida como SUBCONSULTA ou SUBSELECT) é uma instrução do tipo SELECT dentro de outra instrução SQL. Desta forma, se torna possível efetuar consultas que de outra forma seriam extremamente complicadas ou impossíveis de serem feitas de outra forma.
SELECT
*
FROM
tabela1 AS T
WHERE
coluna1 IN
(
SELECT
coluna2
FROM
tabela2 AS T2
WHERE
T.id = T2.id
)
A view pode ser definida como uma tabela virtual composta por linhas e colunas de dados vindos de tabelas relacionadas em uma query (um agrupamento de SELECT’s, por exemplo). As linhas e colunas da view são geradas dinamicamente no momento em que é feita uma referência a ela.
CREATE [OR REPLACE] VIEW view_name [(column_aliases)] AS
defining-query
[WITH READ ONLY]
[WITH CHECK OPTION]
Como já dito, a query que determina uma view pode vir de uma ou mais tabelas, ou até mesmo de outras views.
Ao criarmos uma view, podemos filtrar o conteúdo de uma tabela a ser exibida, já que a função da view é exatamente essa: filtrar tabelas, servindo para agrupá-las, protegendo certas colunas e simplificando o código de programação.
CREATE VIEW employee_yos AS
SELECT
employee_id,
first_name || ' ' || last_name full_name,
FLOOR( months_between( CURRENT_DATE, hire_date )/ 12 ) yos
FROM
employees;
SELECT
*
FROM
employee_yos
WHERE
yos = 15
ORDER BY
full_name;
Uma UDF - User Defined Function é um segmento de código preparado que pode aceitar parâmetros, processar uma lógica e retornar dados em um banco de dados.
Da mesma forma que os procedimentos armazenados, as User Defined Functions desempenham um papel muito importante. Embora haja diferenças entre Stored Procedures e UDFs, as UDFs podem ser usadas para executar uma lógica complexa, podem aceitar parâmetros e retornar dados.
CREATE [OR REPLACE] FUNCTION function_name (parameter_list)
RETURN return_type
IS
O resultado da função pode ser usado em instruções Select, com cláusula Where e em junções (Join).
Funções UDF podem ser de dois tipos: escalares (que retornam no máximo um único valor) ou funções de conjunto, que retornam no máximo um conjunto de valores.
CREATE OR REPLACE FUNCTION get_total_sales(
in_year PLS_INTEGER
)
RETURN NUMBER
IS
l_total_sales NUMBER := 0;
BEGIN
-- get total sales
SELECT SUM(unit_price * quantity)
INTO l_total_sales
FROM order_items
INNER JOIN orders USING (order_id)
WHERE status = 'Shipped'
GROUP BY EXTRACT(YEAR FROM order_date)
HAVING EXTRACT(YEAR FROM order_date) = in_year;
-- return the total sales
RETURN l_total_sales;
END;
SELECT
get_total_sales(2017)
FROM
dual;
Stored Procedure, que traduzido significa Procedimento Armazenado, é uma conjunto de comandos em SQL que podem ser executados de uma só vez, como em uma função. Ele armazena tarefas repetitivas e aceita parâmetros de entrada para que a tarefa seja efetuada de acordo com a necessidade individual.
CREATE [OR REPLACE] PROCEDURE procedure_name
[ (parameter [,parameter]) ]
IS
[declaration_section]
BEGIN
executable_section
[EXCEPTION
exception_section]
END [procedure_nome];
- Quando temos várias aplicações escritas em diferentes linguagens, ou rodam em plataformas diferentes, porém executam a mesma função.
- Quando damos prioridade à consistência e segurança.
Packages ou Pacotes (em português), por sua vez, são objetos PL/SQL utilizados para agrupar os seguintes componentes, quando houver relação entre eles:
- Tipos PL/SQL;
- Variáveis, estruturas de dados e exceções;
- Stored Procedures e Functions;
CREATE [OR REPLACE] PACKAGE package_name
[ AUTHID { CURRENT_USER | DEFINER } ]
{ IS | AS }
[definitions of public TYPES
,declarations of public variables, types, and objects
,declarations of exceptions
,pragmas
,declarations of cursors, procedures, and functions
,headers of procedures and functions]
END [package_name];
O .Net oferece nativamente uma interface genérica para controle de acesso a dados (ADO.NET), o que torna muito simples implementar e oferecer suporte para vários tipos de bancos de dados.
Cada empresa, ou comunidade, desenvolve e disponibiliza essa implementação através do nuget para que outros desenvolvedores possam usa-las.
Alguns exemplos de clientes suportados são:
- SQL Server;
- PostgreSQL;
- MySQL;
- SQLite;
- MongoDB;
- RavenDB;
- Redis;
- Cassandra;
Uma Connection String, ou string de conexão, é o caminho que passamos para nossa aplicação achar o nosso servidor de banco de dados. Ela contém vários parâmetros, como usuário, senha, porta, protocolos e etc...
Cada banco de dados segue um próprio padrão de connection strings, nós iremos usar uma parecida com essa:
Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=XE)));User Id=AppAcademy;Password=AppAcademy;
Para acessarmos nosso BD, iremos usar uma biblioteca chamada "Oracle.ManagedDataAccess.Core"
O jeito mais performático de performarmos operações num banco de dados através de uma aplicação, é usando sua biblioteca nativa diretamente no código. Isso faz com que existam menos camadas de código até chegarmos no BD e nos proporciona um controle maior, mas essa abordagem pode levar a muitas linhas de código.
Exemplo:
using System;
using Oracle.ManagedDataAccess.Client;
namespace SimpleDataAccess
{
class Program
{
static void Main(string[] args)
{
try
{
var connectionString = @"Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=XE)));User Id=AppAcademy;Password=AppAcademy;";
using (var conn = new OracleConnection(connectionString))
{
conn.Open();
using (var cmd = new OracleCommand(@"select sysdate from dual", conn))
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
{
Console.WriteLine("Data do servidor de banco de dados: " + Convert.ToDateTime(reader["sysdate"]));
}
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}
}
}
Um Micro ORM (object relacional mapper) é uma biblioteca que nos ajuda com o mapeamento dos objetos do banco de dados, para objetos do nosso domínio.
Considere que temos uma tabela chamada Pessoas, com a seguinte estrutura, que é igual a representada no nosso domínio:
CREATE TABLE Pessoas
(
Nome VARCHAR2(100) NOT NULL,
Idade INT NOT NULL,
Documento VARCHAR2(14)
);
Com o modelo usado anteriormente, nosso código de consulta, ficaria mais ou menos assim:
using System;
using Oracle.ManagedDataAccess.Client;
namespace SimpleDataAccess
{
class Program
{
static void Main(string[] args)
{
try
{
var connectionString = @"Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=XE)));User Id=AppAcademy;Password=AppAcademy;";
var pessoas = new List<Pessoa>();
using (var conn = new OracleConnection(connectionString))
{
conn.Open();
using (var cmd = new OracleCommand(@"select * from pessoas", conn))
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
{
var pessoa = new Pessoa
{
Nome = reader["NOME"],
Documento = reader["DOCUMENTO"],
Idade = Convert.ToInt32(reader["IDADE"]),
}
pessoas.Add(pessoa);
}
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}
}
}
Quando usamos um ORM, como o Dapper, o nosso código fica muito mais limpo e menor, e com muito pouco prejuízo em questão de performance da aplicação:
using System;
using Dapper;
using Oracle.ManagedDataAccess.Client;
namespace DapperDataAccess
{
class Program
{
static void Main(string[] args)
{
try
{
var connectionString = @"Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=XE)));User Id=AppAcademy;Password=AppAcademy;";
var conn = new OracleConnection(connectionString);
var pessoas = conn.Query<Pessoa>("select * from pessoas");
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}
}
}
O Entity Framework é o ORM mais utilizado e conhecido do mundo .Net. Ele nos permite mapear, manter, e trabalhar com nossa base de dados sem nem mesmo usar o SQL.
Com o sistema de migrations, a base e seus objetos são criados automaticamente conforme a configuração feita no C#.
Um exemplo de como usar o EF Core:
Primeiro precisamos implementar o contexto da nossa aplicação, herdando da classe DbContext do EF Core:
using Microsoft.EntityFrameworkCore;
using System.Diagnostics.CodeAnalysis;
namespace EFCoreDataAccess
{
public class AppContext : DbContext
{
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseOracle(@"Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=XE)));User Id=test_db;Password=test_db;");
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Pessoa>()
.HasKey(c => c.Id);
base.OnModelCreating(modelBuilder);
}
public DbSet<Pessoa> Pessoas { get; set; }
}
}
A nossa entidade:
public class Pessoa
{
public Guid Id { get; set; }
public int Idade { get; set; }
public string Nome { get; set; }
public string Documento { get; set; }
}
Após rodar os comandos Add-Migration e Update-Database, podemos listar todos as pessoas desse jeito:
using System;
using System.Linq;
namespace EFCoreDataAccess
{
public class Program
{
static void Main(string[] args)
{
using (var context = new AppContext())
{
var pessoas = context.Pessoas.ToList();
}
}
}
}
É um conjunto de princípios com foco em domínio, exploração de modelos de formas criativas e definir e falar a linguagem Ubíqua, baseado no contexto delimitado.
Antes de percorrermos com mais detalhes os principais pontos do DDD, é fundamental que consigamos entender de forma clara seus três pilares e como os mesmos têm relação entre si.
Domínio é o coração do negócio em que você está trabalhando. É baseado em um conjunto de ideias, conhecimento e processos de negócio. É a razão do negócio existir. Sem o domínio todo o sistema, todos os processos auxiliares, não servirão para nada.
Se uma empresa existe, é porque ela tem um core business e, normalmente, esse core business é composto pelo domínio principal.
Quando falamos em DDD, não falamos apenas em desenvolver um software, mas sim em entender a modelagem do projeto como um todo. Se você não souber modelar o software, não conseguirá fazê-lo crescer e ser mantido a médio e longo prazo.
O DDD preza que os desenvolvedores façam parte do processo, entendendo o negócio e todos os seus modelos nos diferentes ângulos e não somente participando de reuniões com especialistas.
Um dos pontos mais importantes do DDD, onde 99% das pessoas acabam ignorando, que é falar e extrair a linguagem Ubíqua.
Linguagem Ubíqua é a linguagem falada no dia dia, no contexto da empresa. É a linguagem que utiliza as terminologias da realidade do negócio.
O Clean Code, não é um design pattern de arquitetura propriamente dito, e mais um conjunto de boas práticas que temos podemos seguir para manter a escalabilidade, confiabilidade e reduzir custos de manutenção dos nossos sistemas.
Como relatado por Robert C. Martin em seu livro clássico, Clean Code, um Best Seller da nossa área, algumas práticas e visões são importantíssimas para mantermos a vida do nosso software.
Dentre muitas recomendações, podemos listar algumas:
- Siga as convenções: Siga sempre os padrões do projeto;
- KISS: Mantenha isto estupidamente simples;
- Regra do escoteiro: Deixe sempre o acamapamento mais limpo do que você encontrou;
- Causa raiz: Sempre procure a causa raiz do problema;
- S — Single Responsiblity Principle (Princípio da responsabilidade única)
- O — Open-Closed Principle (Princípio Aberto-Fechado)
- L — Liskov Substitution Principle (Princípio da substituição de Liskov)
- I — Interface Segregation Principle (Princípio da Segregação da Interface)
- D — Dependency Inversion Principle (Princípio da inversão da dependência)
Esses princípios ajudam o programador a escrever códigos mais limpos, separando responsabilidades, diminuindo acoplamentos, facilitando na refatoração e estimulando o reaproveitamento do código.
Princípio da Responsabilidade Única — Uma classe deve ter um, e somente um, motivo para mudar.
Princípio Aberto-Fechado — Objetos ou entidades devem estar abertos para extensão, mas fechados para modificação, ou seja, quando novos comportamentos e recursos precisam ser adicionados no software, devemos estender e não alterar o código fonte original.
Princípio da substituição de Liskov — Uma classe derivada deve ser substituível por sua classe base.
Princípio da Segregação da Interface — Uma classe não deve ser forçada a implementar interfaces e métodos que não irão utilizar.
Princípio da Inversão de Dependência — Dependa de abstrações e não de implementações.
CQRS significa Separação das Operações de Comando e de Consulta, um padrão que separa as operações de leitura e atualização para um armazenamento de dados. Implementar o CQRS em seu aplicativo pode maximizar seu desempenho, escalabilidade e segurança. A flexibilidade criada migrando para o CQRS permite que um sistema evolua melhor ao longo do tempo e impede que os comandos de atualização causem conflitos de mesclagem no nível de domínio.
Dentre muitos outros patterns, podemos ressaltar mais alguns:
- Mediator;
- Factory;
- Repository;
- Facade;
- Proxy;
Os genéricos permitem que você personalize um método, uma classe, uma estrutura ou uma interface para o tipo exato de dados no qual ele atua. Por exemplo, em vez de usar a classe , que permite que chaves e valores sejam de qualquer tipo, você pode usar a classe genérica e especificar os tipos permitidos para a chave e o valor. Entre os benefícios de genéricos estão maior reutilização de códigos e segurança de tipos.
public class Generic<T>
{
public T Field;
}
Quando você cria uma instância de uma classe genérica, pode especificar os tipos reais para substituir os parâmetros de tipo. Isso estabelece uma nova classe genérica, conhecida como uma classe genérica construída, com seus tipos escolhidos substituídos em todos os locais em que aparecem os parâmetros de tipo.
using System;
namespace AppAcademy
{
public static class Program
{
public static void Main()
{
Generic<string> g = new Generic<string>();
g.Field = "A string";
Console.WriteLine("Generic.Field = \"{0}\"", g.Field); // Saída: eric.Field = "A string"
Console.WriteLine("Generic.Field.GetType() = {0}", g.Field.GetType().FullName); // Saída: Generic.Field.GetType() = System.String
}
}
}
A reflexão fornece objetos (do tipo Type) que descrevem assemblies, módulos e tipos. É possível usar a reflexão para criar dinamicamente uma instância de um tipo, associar o tipo a um objeto existente ou obter o tipo de um objeto existente e invocar seus métodos ou acessar suas propriedades e campos. Se você estiver usando atributos em seu código, a reflexão permite acessá-los.
using System;
namespace AppAcademy
{
public static class Program
{
public static void Main()
{
int i = 42;
Type type = i.GetType();
Console.WriteLine(type); // Saída: System.Int32
}
}
}
A reflexão é útil nas seguintes situações:
- Quando você precisa acessar atributos nos metadados do seu programa. Para obter mais informações, consulte Recuperando informações armazenadas em atributos.
- Para examinar e instanciar tipos em um assembly.
- Para criar novos tipos em runtime. Usar as classes em System.Reflection.Emit.
- Para executar a associação tardia, acessar métodos em tipos criados em tempo de execução.
using System;
namespace AppAcademy
{
public class Pessoa
{
public Guid Id { get; set; }
public int Idade { get; set; }
public string Nome { get; set; }
public string Documento { get; set; }
}
public static class Program
{
public static void Main()
{
var p = new Pessoa
{
Id = Guid.NewGuid(),
Idade = 23,
Nome = "Daniel",
Documento = "000000000"
};
foreach(var prop in p.GetType().GetProperties())
{
Console.WriteLine($"{prop.Name}: {prop.GetValue(p)}");
}
}
/*
Saída:
Id: 18f2a777-9864-4504-bb12-72d3ee979419
Idade: 23
Nome: Daniel
Documento: 000000000
*/
}
}
Um delegado é um tipo que representa referências aos métodos com lista de parâmetros e tipo de retorno específicos. Ao instanciar um delegado, você pode associar sua instância a qualquer método com assinatura e tipo de retorno compatíveis. Você pode invocar (ou chamar) o método através da instância de delegado.
Delegados são usados para passar métodos como argumentos a outros métodos. Os manipuladores de eventos nada mais são do que métodos chamados por meio de delegados.
using System;
namespace AppAcademy
{
public delegate void SimplesDelegate();
public class Program
{
public static void minhaFuncao()
{
Console.WriteLine("Eu fui chamada por um delegate ...");
}
public static void Main()
{
SimplesDelegate simplesDelegate = new SimplesDelegate(minhaFuncao);
simplesDelegate(); // Saída: Eu fui chamada por um delegate...
}
}
}
Banco de dados NOSQL do tipo chave-valor, o Redis é uma alternativa open source extremamente popular entre Desenvolvedores Web. Um dos usos mais comuns desta tecnologia consiste na implementação de cache distribuído (algo essencial em cenários envolvendo a necessidade de escalar uma aplicação), valendo-se para isto da excelente performance em operações de leitura oferecida pelo Redis (graças ao armazenamento de dados em memória).
Para instalarmos o Redis no nosso ambiente individual, vamos usar o Docker, basta executar o comando:
docker run -d --name Redis -p 6379:6379 redis:latest
Exemplo de uso:
using System;
using StackExchange.Redis;
using System.Threading.Tasks;
namespace Redis
{
public class Program
{
static readonly ConnectionMultiplexer redis = ConnectionMultiplexer.Connect(
new ConfigurationOptions
{
EndPoints = { "localhost:6379" }
});
static async Task Main(string[] args)
{
var db = redis.GetDatabase();
db.StringSet("A", "B");
var res = db.StringGet("A");
Console.WriteLine(res); // Saída: B
}
}
}
Podemos acessar diretamente a base do Redis dentro do nosso container usando o comando:
docker exec -it Redis "bash"
E após o acesso, usamos a ferramenta de cli do Redis:
redis-cli;
set A B;
get A;
del A;
exit
O RabbitMQ é o servidor de mensageria open-source mais famoso atualmente, sendo utilizado por empresas de todos os tamanhos.
Ele é desenvolvido em Erlang, e utiliza o protocolo AMQP para suporte a mensagens. Assim como o conceito de mensageria no geral, ele ajuda aplicações escalarem seu processamento através do processamento assíncrono das mensagens que são publicadas nele. Dentre as suas características e funcionalidades, encontra-se:
- Tópicos;
- Dead-letter queues
- Agendamento de entregas
- Envio em batch (ou lotes)
- Transações
- Deduplicação
Alguns conceitos a respeito de mensageira são essenciais para que se possa entender o RabbitMQ, e como ocorre o processamento de mensagens.
Mensagem: são um bloco de dados, em formato binário. Uma mensagem pode conter dados em diferentes formatos, como texto, JSON, XML, etc.
Fila: armazena diversas mensagens enquanto o cliente ou consumidor delas não as retira dela. Em uma fila, uma mensagem não pode ser processada mais de uma vez. Imagine como se fosse uma carta normal, indo para sua caixa de correio.
Tópico: semelhante a uma fila, porém permite envio de cópias de mensagens a diferentes clientes (ou assinantes).
O fluxo, de maneira resumida, é o seguinte:
-
Uma mensagem é publicada em uma fila, sendo armazenada ali até que algum cliente a consuma;
-
Um cliente da fila solicita a próxima mensagem dela, a retirando da fila e processando;
-
Em caso de erro no processamento (e dependendo da configuração sobre reconhecimento, ou acknowledgement), a mensagem deve ser devolvida.
A fila no RabbitMQ tem algumas características, que são importantes de se entender:
Durável: se sim, metadados dela são armazenados no disco e poderão ser recuperados após o reinício do nó do RabbitMQ. Além disso, em caso de mensagens persistentes, estas são restauradas após o reinício do nó junto a fila durável. Em caso de uma mensagem persistente em uma fila não-durável, ela ainda será perdida após reiniciar o RabbitMQ.
Auto-Delete: se sim, a fila vai ser apagada caso, após um consumer ter se conectado, todos se desconectaram e ela ficar sem conexões ativas.
Exclusiva se sim, apenas uma conexão será permitida a ela, e após esta encerrar, a fila é apagada.
Outros conceitos importantes de se entender são os de Exchange e Routing Key.
Exchange: são agentes responsáveis por rotear as mensagens para filas, utilizando atributos de cabeçalho, routing keys, ou bindings.
Routing Key: funciona como um relacionamento entre um Exchange e uma fila, descrevendo para qual fila a mensagem deve ser direcionada.
Para instalar o servidor do RabbitMQ no nosso ambiente individual, vamos novamente usar o Docker, basta executar o comando:
docker run -d --name RabbitMQ -p 5672:5672 -p 15672:15672 rabbitmq:3.9-management
Após a instalação, conseguimos vizualizar a GUI do Rabbit no endereço: http://localhost:15672 e podemos fazer o login com o usuário e senha guest.
Exemplo de envio e consumo de mensagem:
Envio
var factory = new ConnectionFactory() {HostName = "localhost"};
using (var connection = factory.CreateConnection())
using (var channel = connection.CreateModel())
{
channel.ExchangeDeclare(exchange: "mensagens", type: ExchangeType.Fanout);
var message = $"Mensagem {counter}";
var body = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchange: "mensagens", routingKey: "", basicProperties: null, body: body);
Console.WriteLine($"Enviada a mensagem: {message}");
counter++;
}
Consumo
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.ExchangeDeclare(exchange: "mensagens", type: ExchangeType.Fanout);
channel.QueueDeclare(queue: "mensagens", durable: false, exclusive: false, autoDelete: false, arguments: null);
channel.QueueBind(queue: "mensagens", exchange: "mensagens", routingKey: "");
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body.ToArray();
var message = Encoding.UTF8.GetString(body);
Console.WriteLine($"Recebida a mensagem: {message}");
};
channel.BasicConsume(queue: queueName, autoAck: true, consumer: consumer);
A razão pela qual fazemos benchmarking é que antes que possamos e devemos começar a otimizar o código, devemos primeiro entender nossa posição atual. Isso é fundamental para validarmos que nossas mudanças estão tendo o impacto que desejamos e, o mais importante, não piorando nosso desempenho.
Um benchmark é simplesmente uma medida ou conjunto de medidas relacionadas à execução de algum código. Os benchmarks permitem comparar o desempenho relativo do código conforme você começa a fazer esforços para melhorar o desempenho. Um benchmark pode ter um escopo bastante amplo ou, como costuma acontecer, você pode se ver testando pequenas mudanças nos micro-benchmarks. O principal é garantir que você tenha um mecanismo para comparar as alterações propostas com o código original que, então, guiará seu trabalho de otimização. É importante usar dados, não suposições ao otimizar o código.
No .Net, a biblioteca mais famosa para fazermos nossos benchmarks é a BenchmarkDotNet.
Exemplo de benchmark de código:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System;
using System.Linq;
namespace Benchmark
{
public class Program
{
public static void Main(string[] args)
{
var summary = BenchmarkRunner.Run<MeuBenckmark>();
}
}
[MemoryDiagnoser]
public class MeuBenckmark
{
public static Random _rdn = new Random();
public int[] _data;
[GlobalSetup]
public void GlobalSetup()
{
_data = new int[1_000_000_000];
for (int i = 0; i < 1_000_000_000; i++)
_data[i] = _rdn.Next(int.MinValue, int.MaxValue);
}
[Benchmark]
public int[] OrderWithFor()
{
var arr = _data;
for (int i = 0; i < arr.Length - 1; i++)
{
if (arr[i] > arr[i + 1])
{
int tmp = arr[i + 1];
arr[i + 1] = arr[i];
arr[i] = tmp;
}
}
return arr;
}
[Benchmark]
public int[] OrderWithLinq()
{
var arr = _data;
arr.ToList().Sort();
return arr;
}
}
}
O gRPC é um framework do Google que implementa RPC, e tem inúmeras vantagens para a escolha do gRPC.
Principais vantagens
- Desenvolvimento de API Contract-first, com Protocol Buffer por padrão;
- Disponível em mais de 10 linguagens de programação;
- Suporte a chamadas streaming do cliente para o servidor, do servidor para cliente e bidirecional (falarei mais deste assunto);
- Reduz a utilização da rede, latência, pois os dados são trafegados em binário;
- Utiliza o protocolo HTTP2;
Protocol buffer ou protobuf é um método criado pelo Google de serialização de dados estruturados, agnóstico de linguagem. A transferência de dados chega a ser até 6x mais rápida que um JSON. O gRPC utiliza o arquivo com extensão .proto para criar o código base, garantindo o Contract-first. A serialização/deserialização faz um uso menos intensivo da CPU pelo fato das mensagens estarem em formato binário, ou seja, mais próximo de como o computador representa os dados.
O .Net dá suporte nativo para criação de APIs que usam o gRPC para o tráfego de dados.
Exemplo de serviço em C#:
using Grpc.Services;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
namespace Grpc
{
public class Startup
{
// This method gets called by the runtime. Use this method to add services to the container.
// For more information on how to configure your application, visit https://go.microsoft.com/fwlink/?LinkID=398940
public void ConfigureServices(IServiceCollection services)
{
services.AddGrpc(opt => {
opt.EnableDetailedErrors = true;
});
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseRouting();
app.UseEndpoints(endpoints =>
{
endpoints.MapGrpcService<GreeterService>();
endpoints.MapGrpcService<CalculoService>();
endpoints.MapGet("/", async context =>
{
await context.Response.WriteAsync("Communication with gRPC endpoints must be made through a gRPC client. To learn how to create a client, visit: https://go.microsoft.com/fwlink/?linkid=2086909");
});
});
}
}
}
proto
syntax = "proto3";
option csharp_namespace = "Grpc";
package calculos;
service Calculos {
rpc Sum (SumRequest) returns (Result);
rpc Subtract (SubtractRequest) returns (Result);
}
message SumRequest {
int32 val1 = 1;
int32 val2 = 2;
}
message SubtractRequest {
int32 val1 = 1;
int32 val2 = 2;
}
message Result {
int32 result = 1;
}
Service
using Grpc.Core;
using Microsoft.Extensions.Logging;
using System.Threading.Tasks;
namespace Grpc.Services
{
public class CalculoService : Calculos.CalculosBase
{
private readonly ILogger<GreeterService> _logger;
public CalculoService(ILogger<GreeterService> logger)
{
_logger = logger;
}
public override Task<Result> Subtract(SubtractRequest request, ServerCallContext context)
{
return Task.FromResult(new Result
{
Result_ = request.Val1 - request.Val2
});
}
public override Task<Result> Sum(SumRequest request, ServerCallContext context)
{
return Task.FromResult(new Result
{
Result_ = request.Val1 + request.Val2
});
}
}
}
csproj
<ItemGroup>
<Protobuf Include="Protos\greet.proto" GrpcServices="Server" />
<Protobuf Include="Protos\calculo.proto" GrpcServices="Server" />
</ItemGroup>
A tecnologia Docker usa o kernel do Linux e recursos do kernel como Cgroups e namespaces para segregar processos. Assim, eles podem ser executados de maneira independente. O objetivo dos containers é criar essa independência: a habilidade de executar diversos processos e aplicações separadamente para utilizar melhor a infraestrutura e, ao mesmo tempo, manter a segurança que você teria em sistemas separados.
As ferramentas de container, incluindo o Docker, fornecem um modelo de implantação com base em imagem. Isso facilita o compartilhamento de uma aplicação ou conjunto de serviços, incluindo todas as dependências deles em vários ambientes. O Docker também automatiza a implantação da aplicação (ou de conjuntos de processos que constituem uma aplicação) dentro desse ambiente de container.
Modularidade
A abordagem do Docker para a containerização se concentra na habilidade de desativar uma parte de uma aplicação, seja para reparo ou atualização, sem interrompê-la totalmente. Além dessa abordagem baseada em microsserviços, é possível compartilhar processos entre várias aplicações da mesma maneira como na arquitetura orientada a serviço (SOA).
Camadas e controle de versão de imagens
Cada arquivo de imagem Docker é composto por uma série de camadas. Elas são combinadas em uma única imagem. Uma nova camada é criada quando há alteração na imagem. Toda vez que um usuário especifica um comando, como executar ou copiar, uma nova camada é criada.
Reversão
Talvez a melhor vantagem da criação de camadas seja a habilidade de reverter quando necessário. Toda imagem possui camadas. Não gostou da iteração atual de uma imagem? Simples, basta reverter para a versão anterior. Esse processo é compatível com uma abordagem de desenvolvimento ágil e possibilita as práticas de integração e implantação contínuas (CI/CD) em relação às ferramentas.
Implantação rápida
Antigamente, colocar novo hardware em funcionamento, provisionado e disponível, levava dias. E as despesas e esforço necessários para mantê-lo eram onerosos. Os containers baseados em docker podem reduzir o tempo de implantação de horas para segundos. Ao criar um container para cada processo, é possível compartilhar rapidamente esses processos similares com novos aplicativos.
O suporte do .Net para docker é bem amplo, e existem vários tutoriais de como fazer a publicação de um container .Net no Docker, a própria Microsoft fornece templates que podemos usar, e o Visual Studio 2019 já oferece suporte ao mesmo sem nem precisarmos mexer em código.
Para criar nossa aplicação executaremos o seguinte comando:
dotnet new webapi dockerapi
Isso vai criar nosso projeto inicial. Agora criamos uma solução e vinculamos ao projeto:
dotnet new sln dockerapi
dotnet sln add .\dockerapi\dockerapi.csproj
Depois que nosso projeto foi criado, devemos criar o arquivo Dockerfile:
FROM mcr.microsoft.com/dotnet/aspnet:5.0-focal AS base
WORKDIR /app
EXPOSE 5000
ENV ASPNETCORE_URLS=http://+:5000
ENV ASPNETCORE_ENVIRONMENT=Development
# Creates a non-root user with an explicit UID and adds permission to access the /app folder
# For more info, please refer to https://aka.ms/vscode-docker-dotnet-configure-containers
RUN adduser -u 5678 --disabled-password --gecos "" appuser && chown -R appuser /app
USER appuser
FROM mcr.microsoft.com/dotnet/sdk:5.0-focal AS build
WORKDIR /src
COPY ["DockerApi/DockerApi.csproj", "DockerApi/"]
RUN dotnet restore "DockerApi/DockerApi.csproj"
COPY . .
WORKDIR "/src/DockerApi"
RUN dotnet build "DockerApi.csproj" -c Release -o /app/build
FROM build AS publish
RUN dotnet publish "DockerApi.csproj" -c Release -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "DockerApi.dll"]
Com nosso Dockerfile criado, podemos buildar a imagem e rodar o container:
docker build -t dockerapi --rm --no-cache -f .\DockerApi\Dockerfile .
docker run -d -p 5000:5000/tcp dockerapi:latest
Agora nosso container já está configurado e podemos acessa-lo pela Url: http://localhost:5000/swagger/index.html
- Apresentação;
- Como funciona um computador:
- Portas lógicas;
- Processos sequenciais;
- Input/Output;
- Sistema binário:
- Diferenças entre o sistema decimal e binário;
- Representação de dados no sistema binário:
- Caracteres;
- Imagem;
- Vídeo;
- Algoritimos:
- O que é um algorítimo;
- O C#;
- O .Net;
- Compilador / IL;
- Codigo gerenciado (GC);
- Frameworks (.Net Core, .Net Framework, .Net Standard);
- Futuro do .Net;
- CLI; (Download - https://dotnet.microsoft.com/download/dotnet/3.1)
- IDE's
- Visual Studio; (Download - https://visualstudio.microsoft.com/pt-br/downloads/)
- Visual Studio Code; (Download - https://code.visualstudio.com/download)
- Git for windows (Download - https://windows.github.com);
- Comandos Git (https://training.github.com/downloads/pt_BR/github-git-cheat-sheet.pdf):
- git config;
- git init;
- git clone;
- git status;
- git diff;
- git add [arquivo];
- git commit -m "[mensagem]"
- git branch
- git branch [nome-do-branch
- git checkout [nome-do-branch]
- git merge [branch]
- git stash;
- git stash pop;
- git fetch [marcador];
- git push [alias] [branch];
- git pull;
- Gitflow;
- Flow (Master, Development, Release);
- Feature;
- Hotfix;
- Bugfix;
- Tag;
- GitKraken (Download - https://www.gitkraken.com/download);
- Variáveis:
- Tipos de variáveis: Variáveis estáticas; Variáveis de instância; Elementos de matriz; Parâmetros de valor; Parâmetros de referência; Parâmetros de saída; Variáveis locais;
- Operadores:
- Operadores lógicos;
- Operadores aritiméticos;
- Operadores de igualdade;
- Operadores de comparação;
- Operadores ternários;
- Instruções:
- Instruções de seleção / condicionais:
- if;
- else;
- else if;
- switch;
- Instruções de iteração / Laços de repetição:
- for;
- while;
- do-while;
- foreach;
- Instruções de atalho
- return;
- continue;
- break;
- Tratamentos de exceções
- throw;
- try-catch;
- try-finally;
- try-catch-finally;
- Instruções de seleção / condicionais:
- Char
- Trabalhando com char;
- Conversores (Parse, TryParse, Convert);
- Representação binária;
- String
- Trabalhando com strings;
- Integer
- Trabalhando com inteiros;
- Conversores (Parse, TryParse, Convert);
- Decimal;
- Trabalhando com decimais;
- Conversores (Parse, TryParse, Convert);
- Double;
- Trabalhando com doubles;
- Conversores (Parse, TryParse, Convert);
- Byte;
- Trabalhando com bytes;
- DateTime;
- Trabalhando com datas;
- Conversores;
- ToString();
- Array;
- Trabalhando com arrays;
- Tipos de arrays (1D, 2D);
- Iterando um array;
- Null:
- Perigos;
- Tipos nullables;
- NullReferenceException;
- Tipos de valor;
- Tipos de referência;
- Palavras-chave;
- Acessibilidade:
- Público;
- Privado;
- Interno;
- Estrutura de um programa .Net;
- Namespaces;
- Classe;
- Método Main;
- Declaração;
- Parâmetros:
- Passando por referência;
- Passando por valor;
- Parâmetros de entrada (in);
- Parâmetros de saída (out);
- Extension methods;
- Paradigmas de programação;
- Classes;
- Herança;
- Encapsulamento;
- Polimorfismo;
- Abstração;
- IEnumerable, List, Collection, ReadonlyCollection:
- Diferenças entre interfaces de lista;
- Quando usar / não usar;
- Trabalhando com listas;
- LINQ:
- Where;
- Any;
- First;
- SingleOrDefault;
- FirstOrDefault;
- Count;
- GroupBy;
- Select;
- Contains;
- Performance;
- Tasks;
- Async e Await;
- Paralelismo:
- Parallel library:
- Parallel For;
- Parallel Foreach;
- Task collection:
- WaitAll;
- WhenAll;
- Parallel library:
- CancelationTokens;
- Conceitos:
- REST;
- HTTP;
- API;
- JSON;
- Postman;
- Consumo de web services;
- Construção de APIs:
- Boas práticas;
- Autenticação;
- Cache;
- Tratamento de erros;
- Resiliência;
- Rate limit;
- Logging;
- Background Jobs:
- Hangfire;
- WorkerServices;
- Testes unitários;
- Teste de integração;
- xUnit;
- nUnit;
- Mock;
- Docker
- Docker desktop (Dowload - https://www.docker.com/products/docker-desktop)
- Docker pull (Dowload imagem do Oracle);
- DML - Linguagem de Manipulação de Dados;
- DDL - Linguagem de Definição de Dados;
- DCL - Linguagem de Controle de Dados;
- DTL - Linguagem de Transação de Dados;
- DQL - Linguagem de Consulta de Dados;
- Palavras-chave em SQL:
- Cláusulas;
- Operadores Lógicos;
- Operadores relacionais;
- Funções de Agregação;
- Joins:
- LEFT JOIN;
- RIGHT JOIN;
- Subquery;
- View;
- Funções;
- Stored Procedures;
- Packages;
- Acesso com ADO.NET;
- Dapper;
- Entity Framework:
- Migrations;
- Fluent mapping;
- Criação de APIs:
- Repository;
- Unity of Work;
- DDD;
- Clean Code;
- SOLID;
- CQRS;
- Design Patterns:
- Mediator;
- Factory;
- Injeção de dependência;
- Repository;
- Facade;
- Proxy;
- Notification; ...
- Tipos genéricos;
- Reflection;
- Delegates
- Cache (Redis);
- Mensageria (RabbitMQ);
- Benchmark;
- gRPC;
- Docker;