Обзор библиотек для извлечения текста из презентаций и аудио
PyPDF2 может быть установлен как обычный программный пакет, так и с использованием pip3
PdfFileReader сначала импортируется класс. Затем, используя этот класс, он открывает документ и извлекает информацию о документе, используя метод getDocumentInfo(), количество используемых страниц getDocumentInfo() и содержимое первой страницы.
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов pdf.getPage(0) извлекает первую страницу документа. В конце концов, извлеченная информация печатается в stdout
#!/usr/bin/python
from PyPDF2 import PdfFileReader
pdf_document = "example.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages() print (info)
print ("number of pages: %i" % pages) page1 = pdf.getPage(0)
print(page1)
print(page1.extractText())
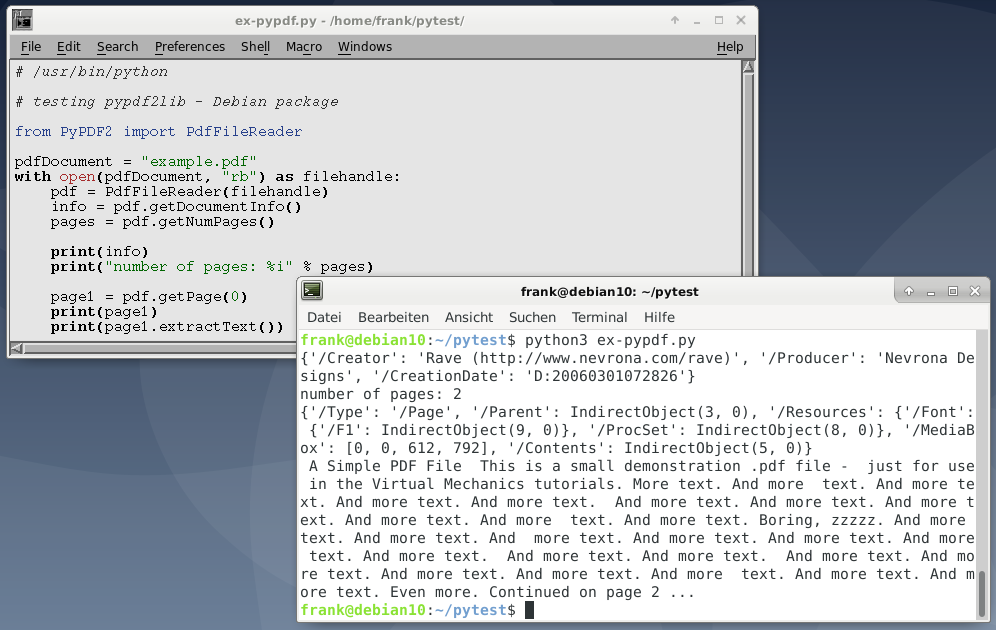
Как показано выше, извлеченный текст печатается на постоянной основе. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены в потоке содержимого страницы, и их использование может привести к неожиданностям. Это в основном зависит от внутренней структуры документа PDF и от того, как поток инструкций PDF был создан процессом записи PDF.
PyMuPDF доступен на веб-сайте PyPi, и вы устанавливаете пакет с помощью следующей команды в терминале:
$ pip3 install PyMuPDF
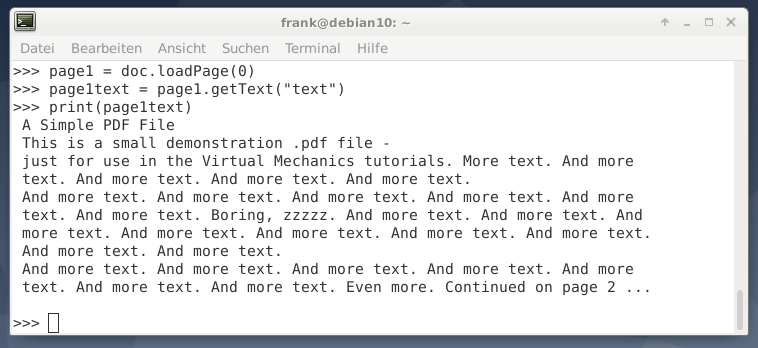
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2. Импортируемый модуль имеет имя fitz и возвращается к предыдущему имени PyMuPDF.
#!/usr/bin/python
import fitz
pdf_document = "example.pdf"
doc = fitz.open(pdf_document):
print ("number of pages: %i" % doc.pageCount)
print(doc.metadata)page1 = doc.loadPage(0)
page1text = page1.getText("text")
print(page1text)
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений - целые абзацы с разрывами строк сохраняются такими же, как в PDF-документе
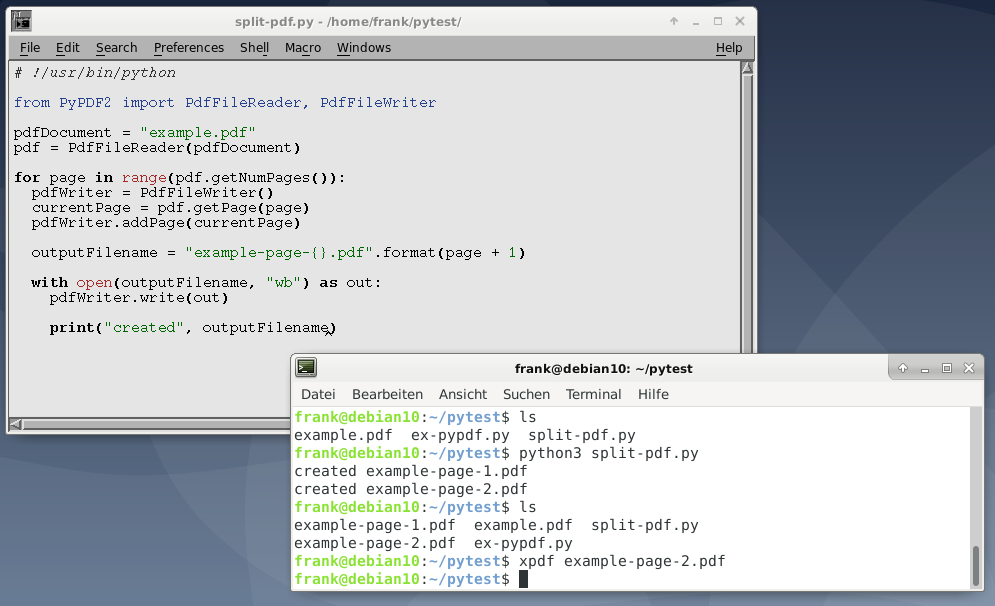
Для этого примера, в первую очередь необходимо импортировать классы PdfFileReader и PdfFileWriter. Затем мы открываем файл PDF, создаем объект для чтения и перебираем все страницы, используя метод объекта для чтения getNumPages.
Внутри цикла for мы создаем новый экземпляр PdfFileWriter, который еще не содержит страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод pdfWriter.addPage(). Этот метод принимает объект страницы, который мы получаем, используя метод PdfFileReader.getPage().
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «page» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме (режиме wb) записи двоичного файла и используем метод write() класса pdfWriter для сохранения извлеченной страницы на диск.
#!/usr/bin/python
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "example.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "example-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
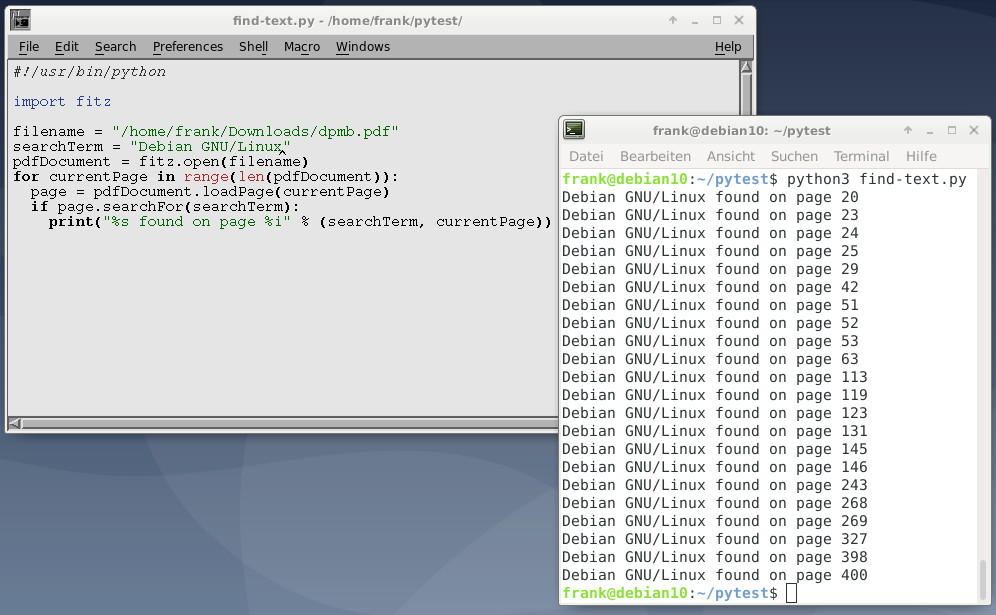
Этот вариант использования довольно практичен и работает аналогично pdfgrep. Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат данную строку поиска. Страницы загружаются одна за другой, и с помощью метода searchFor() обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на stdout.
#!/usr/bin/python
import fitz
filename = "example.pdf"
search_term = "invoice"
pdf_document = fitz.open(filename):
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
Выполните следующую команду для установки библиотеки:
pip install SpeechRecognition
Первым шагом, как всегда, является импорт необходимых библиотек. В этом случае нам нужно импортировать только что загруженную библиотеку speech_recognition
import speech_recognition as speech_recog
Для преобразования речи в текст нам нужен единственный класс - это класс Recognizer из модуля speech_recognition. В зависимости от базового API, используемого для преобразования речи в текст, класс Recognizer имеет следующие методы:
- recognize_bing(): Использует Microsoft Bing Speech API
- recognize_google(): Использует Google Speech API
- recognize_google_cloud(): Использует Google Cloud Speech API
- recognize_houndify(): Использует Houndify API от SoundHound
- recognize_ibm(): Использует IBM Speech to Text API
- recognize_sphinx(): Использует PocketSphinx API
Среди всех вышеперечисленных способов метод recognize_sphinx() можно использовать в автономном режиме для перевода речи в текст.
Чтобы распознать речь из аудиофайла, мы должны создать объект класса AudioFile модуля speech_recognition. Путь аудиофайла, который вы хотите перевести в текст, передается в конструктор класса AudioFile. Выполните следующий скрипт:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
В приведенном выше коде обновите путь к аудиофайлу, который вы хотите расшифровать.
Мы будем использовать метод recognize_google() для расшифровки наших аудио файлов. Тем не менее, метод recognize_google() требует объект AudioData модуля speech_recognition в качестве параметра. Чтобы преобразовать наш аудиофайл в объект AudioData, мы можем использовать метод record() класса Recognizer. Нам нужно передать объект AudioFile методу record(), как показано ниже:
with sample_audio as audio_file:
audio_content = recog.record(audio_file)
Теперь, если вы проверите тип переменной audio_content, вы увидите, что она имеет тип speech_recognition.AudioData.
type(audio_content)
Результат:
speech_recognition.AudioData
Теперь мы можем просто передать объект audio_content методу recognize_google() объекта класса Recognizer(), и аудиофайл будет преобразован в текст. Выполните следующий скрипт:
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas tank degrees office 30 face before you go out the race was badly strained and hung them the stray cat gave birth to kittens the young girl gave no clear response the meal was called before the bells ring what weather is in living'
Приведенный выше результат показывает текст аудиофайла. Вы можете видеть, что файл не был на 100% правильно транскрибирован, но точность довольно разумная.
Вместо того, чтобы транскрибировать полную речь, вы также можете транскрибировать определенный сегмент аудиофайла. Например, если вы хотите транскрибировать только первые 10 секунд аудиофайла, вам нужно передать 10 в качестве значения параметра duration метода record(). Посмотрите на следующий скрипт:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
audio_content = recog.record(audio_file, duration=10)
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas'
Таким же образом вы можете пропустить некоторую часть аудиофайла с самого начала, используя параметр offset. Например, если вы не хотите транскрибировать первые 4 секунды звука, передайте 4 в качестве значения для атрибута offset. Например, следующий скрипт пропускает первые 4 секунды аудиофайла, а затем транскрибирует аудиофайл в течение 10 секунд.
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
audio_content = recog.record(audio_file, offset=4, duration=10)
recog.recognize_google(audio_content)
Результат:
'take the winding path to reach the lake no closely the size of the gas tank web degrees office dirty face'
Аудио файл может содержать шум по разным причинам. Шум действительно может повлиять на качество перевода речи в текст. Чтобы уменьшить шум, класс Recognizer содержит метод adjust_for_ambient_noise(), который принимает объект AudioData в качестве параметра. Следующий скрипт показывает, как можно улучшить качество транскрипции, удалив шум из аудиофайла:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
recog.adjust_for_ambient_noise(audio_file)
audio_content = recog.record(audio_file)
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas tank web degrees office 30 face before you go out the race was badly strained and hung them the stray cat gave birth to kittens the younger again no clear response the mail was called before the bells ring what weather is in living'
Вывод очень похож на то, что мы получили ранее; это связано с тем, что в аудиофайле уже было очень мало шума.