A lightweight, type-safe, PaddleOCR implementation in Bun/Node.js for text detection and recognition in JavaScript environments.
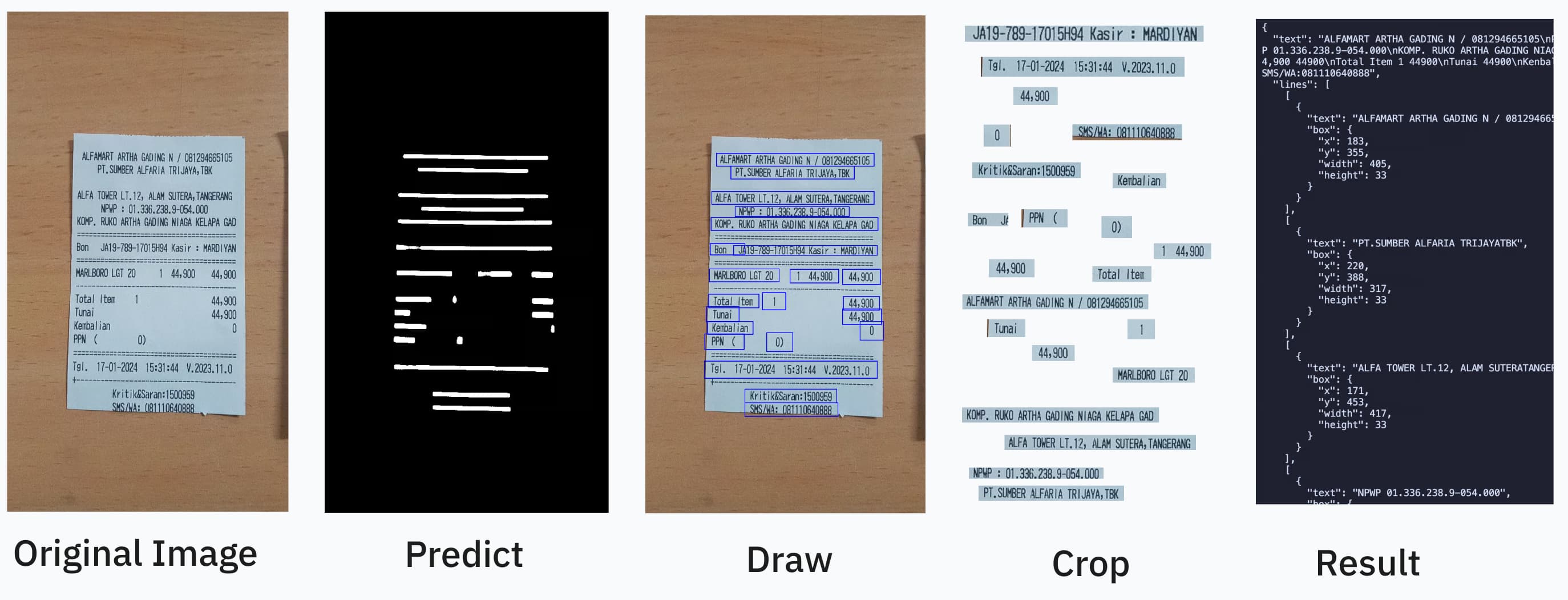
OCR should be as easy as:
import { PaddleOcrService } from "ppu-paddle-ocr";
const service = new PaddleOcrService();
await service.initialize();
const result = await service.recognize(fileBufferOrCanvas);
await service.destroy();You can combine it further by using open-cv https://github.com/PT-Perkasa-Pilar-Utama/ppu-ocv for more improved accuracy.
import { ImageProcessor } from "ppu-ocv";
const processor = new ImageProcessor(bodyCanvas);
processor.grayscale().blur();
const canvas = processor.toCanvas();
processor.destroy();ppu-paddle-ocr brings the powerful PaddleOCR optical character recognition capabilities to JavaScript environments. This library simplifies the integration of ONNX models with Node.js applications, offering a lightweight solution for text detection and recognition without complex dependencies.
Built on top of onnxruntime-node, ppu-paddle-ocr handles all the complexity of model loading, preprocessing, and inference, providing a clean and simple API for developers to extract text from images with minimal setup.
- Lightweight: Optimized for performance with minimal dependencies
- Easy Integration: Simple API to detect and recognize text in images
- Cross-Platform: Works in Node.js and Bun environments
- Customizable: Support for custom models and dictionaries
- Pre-packed Models: Includes optimized PaddleOCR models ready for immediate use, with automatic fetching and caching on the first run.
- TypeScript Support: Full TypeScript definitions for enhanced developer experience
- Auto Deskew: Using multiple text analysis to straighten the image
Install using your preferred package manager:
npm install ppu-paddle-ocr
yarn add ppu-paddle-ocr
bun add ppu-paddle-ocrNote
This project is developed and tested primarily with Bun. Support for Node.js, Deno, or browser environments is not guaranteed.
If you choose to use it outside of Bun and encounter any issues, feel free to report them. I'm open to fixing bugs for other runtimes with community help.
To get started, create an instance of PaddleOcrService and call the initialize() method. This will download and cache the default models on the first run.
import { PaddleOcrService } from "ppu-paddle-ocr";
// Create a new instance of the service
const service = new PaddleOcrService({
debugging: {
debug: false,
verbose: true,
},
});
// Initialize the service (this will download models on the first run)
await service.initialize();
const result = await service.recognize("./assets/receipt.jpg");
console.log(result.text);
// It's important to destroy the service when you're done to release resources.
await service.destroy();You can fine-tune the ONNX Runtime session configuration for optimal performance:
import { PaddleOcrService } from "ppu-paddle-ocr";
// Create a service with optimized session options
const service = new PaddleOcrService({
session: {
executionProviders: ["cpu"], // Use CPU-only for consistent performance
graphOptimizationLevel: "all", // Enable all optimizations
enableCpuMemArena: true, // Better memory management
enableMemPattern: true, // Memory pattern optimization
executionMode: "sequential", // Better for single-threaded performance
interOpNumThreads: 0, // Let ONNX decide optimal thread count
intraOpNumThreads: 0, // Let ONNX decide optimal thread count
},
});
await service.initialize();
const result = await service.recognize("./assets/receipt.jpg");
console.log(result.text);
await service.destroy();You can provide custom models via file paths, URLs, or ArrayBuffers during initialization. If no models are provided, the default models will be fetched from GitHub.
const service = new PaddleOcrService({
model: {
detection: "./models/custom-det.onnx",
recognition: "https://example.com/models/custom-rec.onnx",
charactersDictionary: customDictArrayBuffer,
},
});
// Don't forget to initialize the service
await service.initialize();You can dynamically change the models or dictionary on an initialized instance.
// Initialize the service first
const service = new PaddleOcrService();
await service.initialize();
// Change the detection model
await service.changeDetectionModel("./models/new-det-model.onnx");
// Change the recognition model
await service.changeRecognitionModel("./models/new-rec-model.onnx");
// Change the dictionary
await service.changeTextDictionary("./models/new-dict.txt");See: Example usage
You can provide a custom dictionary for a single recognize call without changing the service's default dictionary. This is useful for one-off recognitions with special character sets.
// Initialize the service first
const service = new PaddleOcrService();
await service.initialize();
// Use a custom dictionary for this specific call
const result = await service.recognize("./assets/receipt.jpg", {
dictionary: "./models/new-dict.txt",
});
// The service's default dictionary remains unchanged for subsequent calls
const anotherResult = await service.recognize("./assets/another-image.jpg");You can disable caching for individual OCR calls if you need fresh processing each time:
// Initialize the service first
const service = new PaddleOcrService();
await service.initialize();
// Process with caching (default behavior)
const cachedResult = await service.recognize("./assets/receipt.jpg");
// Process without caching for this specific call
const freshResult = await service.recognize("./assets/receipt.jpg", {
noCache: true,
});
// You can also combine noCache with other options
const result = await service.recognize("./assets/receipt.jpg", {
noCache: true,
flatten: true,
});- detection:
PP-OCRv5_mobile_det_infer.onnx - recogniton:
en_PP-OCRv4_mobile_rec_infer.onnx - dictionary:
en_dict.txt(97 class)
See: Models See also: How to convert paddle ocr model to onnx
All options are grouped under the PaddleOptions interface:
export interface PaddleOptions {
/** File paths, URLs, or buffers for the OCR model components. */
model?: ModelPathOptions;
/** Controls parameters for text detection. */
detection?: DetectionOptions;
/** Controls parameters for text recognition. */
recognition?: RecognitionOptions;
/** Controls logging and image dump behavior for debugging. */
debugging?: DebuggingOptions;
/** ONNX Runtime session configuration options. */
session?: SessionOptions;
}Options for individual recognize() calls.
| Property | Type | Default | Description |
|---|---|---|---|
flatten |
boolean |
false |
Return flattened results instead of grouped by lines. |
dictionary |
string | ArrayBuffer |
null |
Custom character dictionary for this specific call. |
noCache |
boolean |
false |
Disable caching for this specific call. |
Specifies paths, URLs, or buffers for the OCR models and dictionary files.
| Property | Type | Required | Description |
|---|---|---|---|
detection |
string | ArrayBuffer |
No (uses default model) | Path, URL, or buffer for the text detection model. |
recognition |
string | ArrayBuffer |
No (uses default model) | Path, URL, or buffer for the text recognition model. |
charactersDictionary |
string | ArrayBuffer |
No (uses default dictionary) | Path, URL, buffer, or content of the dictionary file. |
Note
If you omit model paths, the library will automatically fetch the default models from the official GitHub repository. Don't forget to add a space and a blank line at the end of the dictionary file.
Controls preprocessing and filtering parameters during text detection.
| Property | Type | Default | Description |
|---|---|---|---|
autoDeskew |
boolean |
False |
Correct orientation using multiple text analysis. |
mean |
[number, number, number] |
[0.485, 0.456, 0.406] |
Per-channel mean values for input normalization [R, G, B]. |
stdDeviation |
[number, number, number] |
[0.229, 0.224, 0.225] |
Per-channel standard deviation values for input normalization. |
maxSideLength |
number |
960 |
Maximum dimension (longest side) for input images (px). |
paddingVertical |
number |
0.4 |
Fractional padding added vertically to each detected text box. |
paddingHorizontal |
number |
0.6 |
Fractional padding added horizontally to each detected text box. |
minimumAreaThreshold |
number |
20 |
Discard boxes with area below this threshold (px²). |
Controls parameters for the text recognition stage.
| Property | Type | Default | Description |
|---|---|---|---|
imageHeight |
number |
48 |
Fixed height for resized input text line images (px). |
Enable verbose logs and save intermediate images to help debug OCR pipelines.
| Property | Type | Default | Description |
|---|---|---|---|
verbose |
boolean |
false |
Turn on detailed console logs of each processing step. |
debug |
boolean |
false |
Write intermediate image frames to disk. |
debugFolder |
string |
out |
Output directory for debug images. |
Controls ONNX Runtime session configuration for optimal performance.
| Property | Type | Default | Description |
|---|---|---|---|
executionProviders |
string[] |
['cuda', 'cpu'] |
Execution providers to use (e.g., ['cpu'], ['cuda', 'cpu']). |
graphOptimizationLevel |
'disabled' | 'basic' | 'extended' | 'layout' | 'all' |
'all' |
Graph optimization level for better performance. |
enableCpuMemArena |
boolean |
true |
Enable CPU memory arena for better memory management. |
enableMemPattern |
boolean |
true |
Enable memory pattern optimization. |
executionMode |
'sequential' | 'parallel' |
'sequential' |
Execution mode for the session ('sequential' for single-threaded performance). |
interOpNumThreads |
number |
0 |
Number of inter-op threads (0 lets ONNX decide). |
intraOpNumThreads |
number |
0 |
Number of intra-op threads (0 lets ONNX decide). |
Run bun task bench. Current result:
> bun task bench
$ bun scripts/task.ts bench
Running benchmark: index.bench.ts
clk: ~3.07 GHz
cpu: Apple M1
runtime: bun 1.3.0 (arm64-darwin)
benchmark avg (min … max) p75 / p99 (min … top 1%)
------------------------------------------- -------------------------------
infer test 1 ~2.79 µs/iter 2.63 µs █
(2.38 µs … 526.92 µs) 6.08 µs █
( 0.00 b … 928.00 kb) 144.47 b ▄█▅▁▂▁▁▁▁▂▁▁▁▁▁▁▁▁▁▁▁
infer test 2 ~2.59 µs/iter 2.65 µs █
(2.47 µs … 2.87 µs) 2.82 µs █▅▂▂█ █ ▂
( 0.00 b … 1.18 kb) 85.15 b ▆▃█████▆█▆██▆▆▆█▃▁▁▁▃
summary
infer test 2
1.08x faster than infer test 1
------------------------------------------- -------------------------------
infer deskew test 1 ~13.42 ms/iter 14.08 ms █ ▃▃██ █
(11.53 ms … 16.43 ms) 16.25 ms █ ████▂█▂▂ ▂▂▂▂
( 0.00 b … 2.58 mb) 805.57 kb ██▅▅▇█▇█▃▅▅▃▁▅▇▃▃▁▃▁▃
infer deskew test 2 ~13.46 ms/iter 14.05 ms █
(11.48 ms … 16.55 ms) 15.65 ms ▇█▇ ▂█ ▂▇
( 0.00 b … 1.06 mb) 79.36 kb ████▃▁██▁██▃▁▁▃▃▆▁▃▁▃
summary
infer deskew test 2
1.01x faster than infer deskew test 1Performance Note: The benchmark shows ~2.7µs per iteration with caching enabled. Without caching, performance is approximately 269ms/iter.