01. Background
I use the term asynchronous video to refer to any representation of spatial data (video) whose pixel value measurements are not temporally synchronous. That is, each pixel can express data at different points in time from any other pixel.
We can contrast this notion with framed video, where all the pixels represent data in lockstep with each other (i.e., frames), and these measurements are almost always recorded at fixed intervals (meaning the frame rate does not change over time).
Wikipedia has a decent summary. Basically, these are cameras whose pixels operate asynchronously, meaning that they directly capture asynchronous video. The dominant event camera technology used in the literature is the Dynamic Vision System (DVS).
My research is focused on the notion of casting arbitrary video sources to a single, unified, asynchronous representation. This repository provides lots of tools to accomplish that task.
Event cameras are on the rise, gaining ever higher resolution and precision, but the software ecosystem is not keeping up. Most researchers in the space are focused chiefly on building applications for these cameras, rather than on building complete, generic systems. What happens when a new camera type comes out in a year or two with a different data format, or which captures a different type of event data? Well, all the applications out there will have to be adapted, one by one, to be compatible with the new camera. That seems wasteful. Instead, I propose the use of a common, intermediate representation for building applications on top of. We can have utilities for casting the proprietary data format of various event cameras to this one representation. Then, when that new camera comes out, all we have to do is write a new data casting tool to transform it to that unified representation. All existing applications should still work without modification.
We can also (quite easily, in fact) transform the data from a classical framed video to this representation. This means that applications built for the representation will also be compatible with "regular" cameras. We can thus build cool applications which exploit the inter-frame stability of traditional video in novel ways, without having to resort to complicated, obtuse RNN architectures (this opinion of ML is meant to be only slightly snarky).
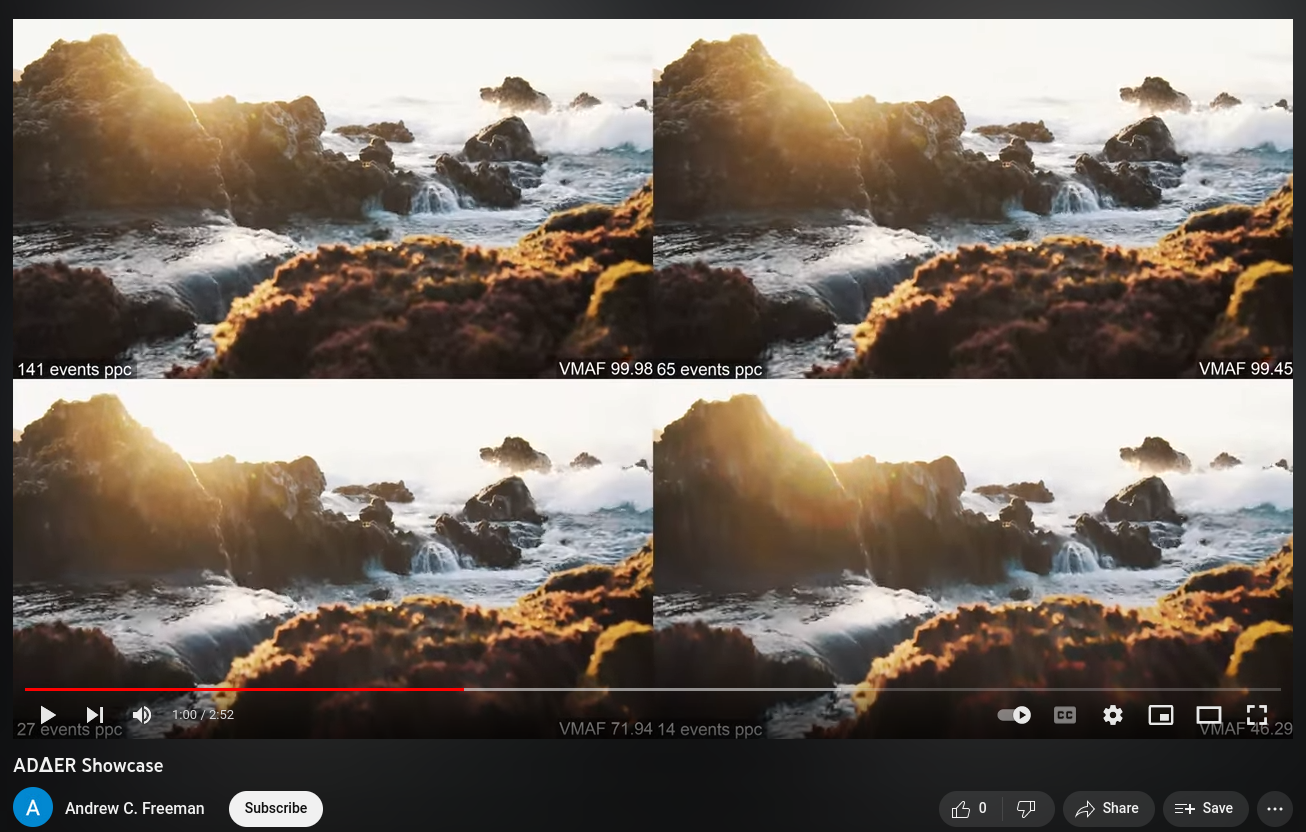
Finally, compression for event camera data is a topic rarely breached in the literature. Even worse, lossy compression has essentially not been explored at all. Why not? Well, the data representation produced by these cameras is inherently difficult to compress, since each event only conveys information relative to previous events at that pixel (i.e., contrast change). Most often, events will be grouped into temporal bins as some sort of framed representation, inherently quantizing their temporal information and throwing away much of the precision they convey. That's where all the loss occurs, and it's not driven by some quality metric or application-level directive. This seems backwards. Why capture this extraordinary event data, only to shoehorn it back into frames? I think we should try, insofar as is practical, to keep asynchronous data asynchronous. We need a tunable, dynamic, lossy compression scheme in the asynchronous domain, and this scheme must be fast enough that we can build real-time systems. Having a camera with microsecond precision gets me nowhere if the application-level processing of that data takes 10x longer than the recording time.
To address these concerns, I propose the ADΔER (pronounced "adder") representation is inspired by the ASINT camera design by Singh et al. It aims to help us move away from thinking about video in terms of fixed sample rates and frames, and to provide a one-size-fits-all ("narrow waist") method for representing intensity information asynchronously.
Under the ASINT model, a pixel
Practically speaking, it's most useful to think about ADΔER in reference to the source data type. In the context of framed video, ADΔER allows us to have multi-frame intensity averaging for stable (unchanging) regions of a scene. This can function both to denoise the video and enable higher dynamic range, all while preserving the temporal synchronicity of the source. See the info on simultaneous transcoding to quickly test this out!