01. Background
The ADΔER (pronounced "adder") representation is inspired by the ASINT camera design by Singh et al. It aims to help us move away from thinking about video in terms of fixed sample rates and frames, and to provide a one-size-fits-all ("narrow waist") method for representing intensity information asynchronously.
Under the ASINT model, a pixel
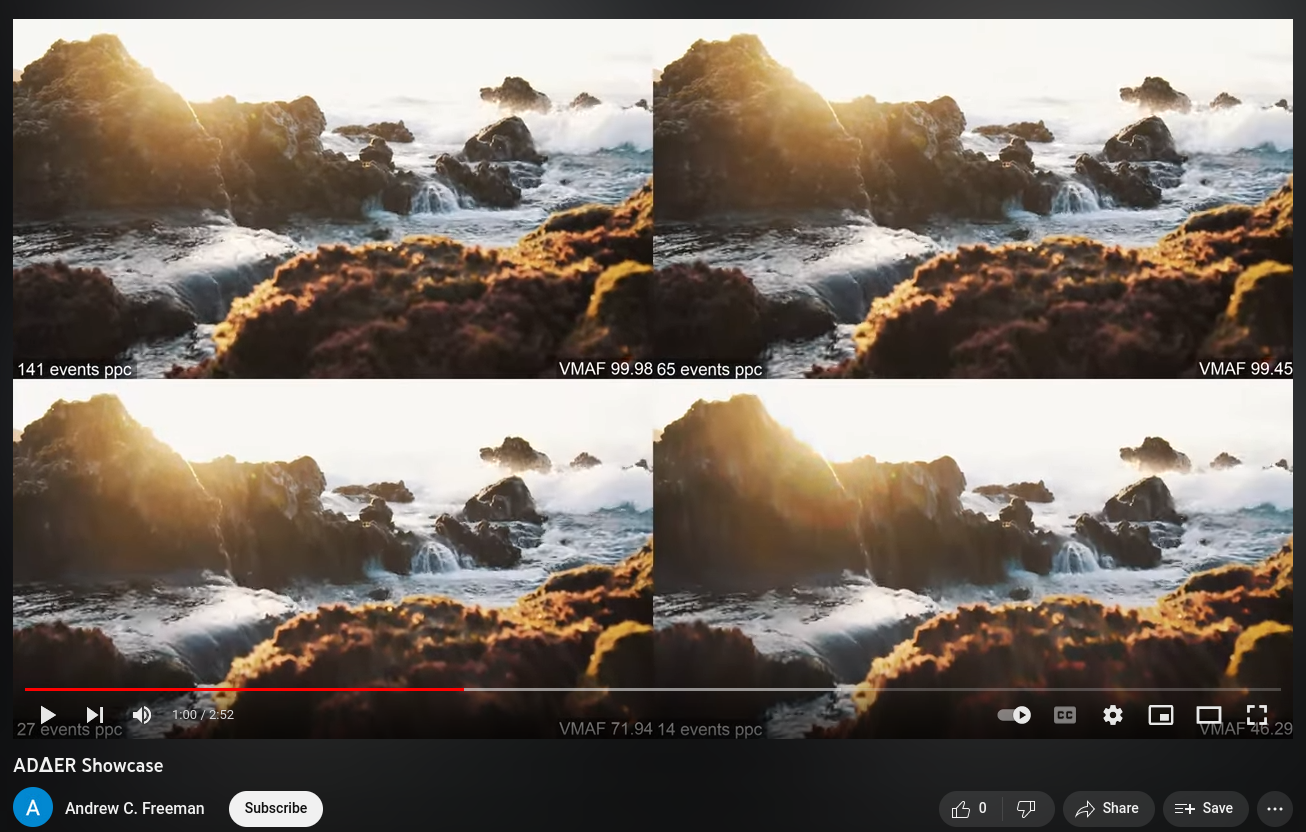
Practically speaking, it's most useful to think about ADΔER in reference to the source data type. In the context of framed video, ADΔER allows us to have multi-frame intensity averaging for stable (unchanging) regions of a scene. This can function both to denoise the video and enable higher dynamic range, all while preserving the temporal synchronicity of the source. See the info on simultaneous transcoding to quickly test this out!
I use the term asynchronous video to refer to any representation of spatial data (video) whose pixel value measurements are not temporally synchronous. That is, each pixel can express data at different points in time from any other pixel.
We can contrast this notion with framed video, where all the pixels represent data in lockstep with each other (i.e., frames), and these measurements are almost always recorded at fixed intervals (meaning the frame rate does not change over time).
Wikipedia has a decent summary. Basically, these are cameras whose pixels operate asynchronously, meaning that they directly capture asynchronous video. The dominant event camera technology used in the literature is the Dynamic Vision System (DVS).
TODO