The OlmoEarth models are a flexible, multi-modal, spatio-temporal family of foundation models for Earth Observations.
The OlmoEarth models exist as part of the OlmoEarth platform. The OlmoEarth Platform is an end-to-end solution for scalable planetary intelligence, providing everything needed to go from raw data through R&D, to fine-tuning and production deployment.
We recommend Python 3.12, and recommend using uv. To install dependencies with uv, run:
git clone git@github.com:allenai/olmoearth_pretrain.git
cd olmoearth_pretrain
uv sync --locked --all-extras --python 3.12
# only necessary for development
uv tool install pre-commit --with pre-commit-uv --force-reinstalluv installs everything into a venv, so to keep using python commands you can activate uv's venv: source .venv/bin/activate. Otherwise, swap to uv run python.
For inference and model loading without training dependencies:
uv sync --lockedOlmoEarth is built using OLMo-core. OLMo-core's published Docker images contain all core and optional dependencies.
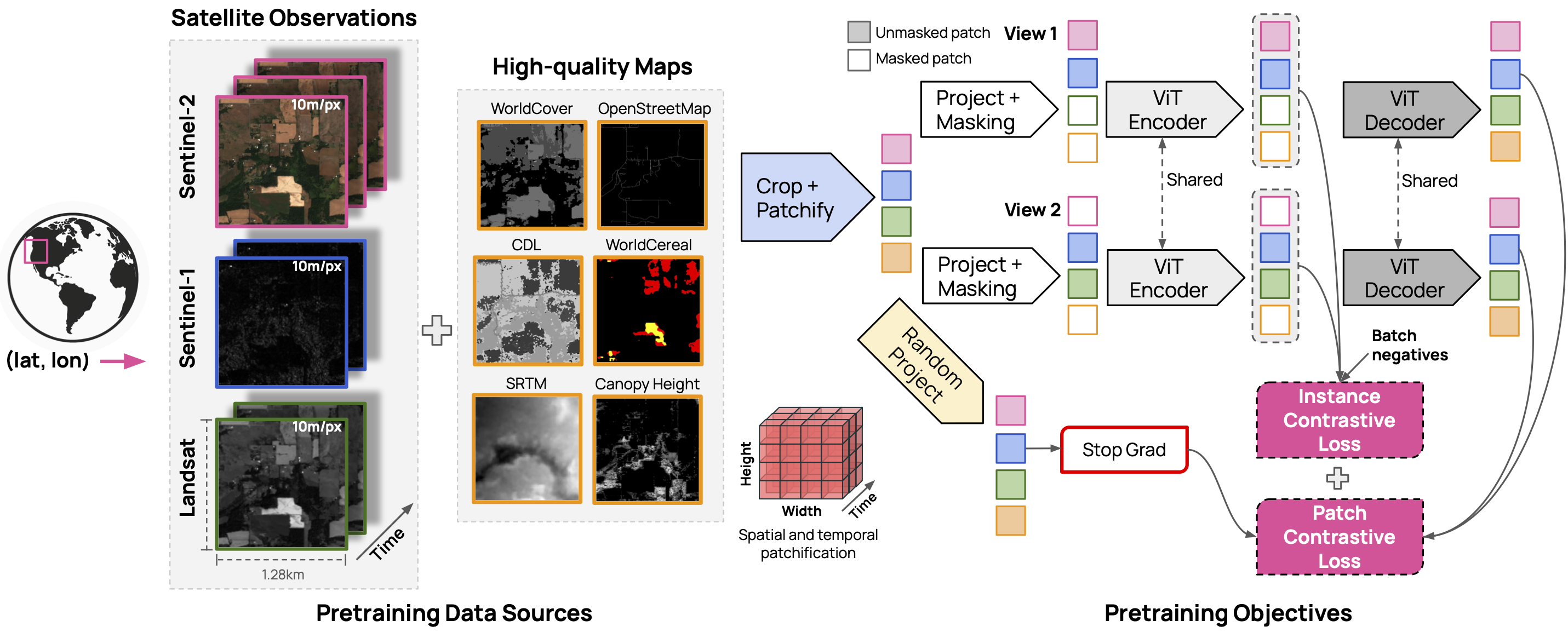
The OlmoEarth models are trained on three satellite modalities (Sentinel 2, Sentinel 1 and Landsat) and six derived maps (OpenStreetMap, WorldCover, USDA Cropland Data Layer, SRTM DEM, WRI Canopy Height Map, and WorldCereal).
We iteratively release improvements to our OlmoEarth models. These are recorded in our changelog.
v1
The v1 models were trained using the scripts in scripts/official/v1. We describe this model in the original OlmoEarth report.
| Model Size | Weights | Encoder Params | Decoder Params |
|---|---|---|---|
| Nano | link | 1.4M | 800K |
| Tiny | link | 6.2M | 1.9M |
| Base | link | 89M | 30M |
| Large | link | 308M | 53M |
v1.1
The v1.1 models were trained using the scripts in scripts/official/v1_1. We describe this model in the OlmoEarth v1.1 tech report.
| Model Size | Weights | Encoder Params | Decoder Params |
|---|---|---|---|
| Nano | link | 1.7M | 800K |
| Tiny | link | 12.5M | 1.9M |
| Base | link | 114M | 30M |
v1.2
The v1.2 models were trained using the scripts in scripts/official/v1_2. We describe this model in the OlmoEarth v1.2 tech report.
| Model Size | Weights | Encoder Params | Decoder Params |
|---|---|---|---|
| Nano | link | 1.7M | 800K |
| Tiny | link | 12.5M | 1.9M |
| Small | link | 35.6M | 7.4M |
| Base | link | 114M | 30M |
InferenceQuickstart shows how to initialize the OlmoEarth model and apply it on a satellite image.
We also have several more in-depth tutorials for computing OlmoEarth embeddings and fine-tuning OlmoEarth on downstream tasks:
- Fine-tuning OlmoEarth for Segmentation
- Computing Embeddings using OlmoEarth
- Fine-tuning OlmoEarth in rslearn
Additionally, olmoearth_projects has several examples of active OlmoEarth deployments.
Our pretraining dataset contains 285,288 samples from around the world of 2.56km×2.56km regions, although many samples contain only a subset of the timesteps and modalities.
The distribution of the samples is available below:
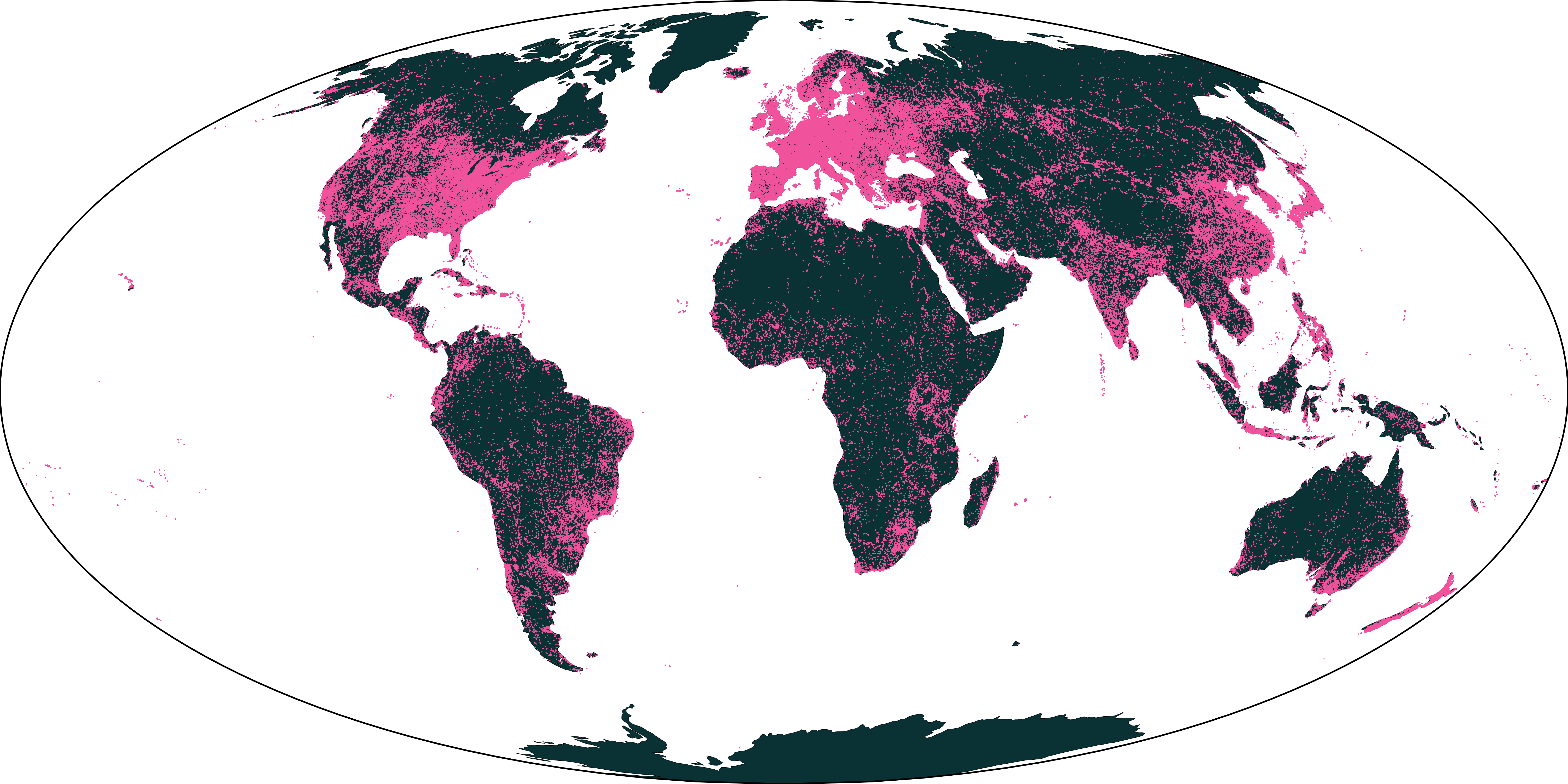
The dataset can be downloaded here.
Detailed instructions on how to make your own pretraining dataset are available in the dataset README.
Detailed instructions on how to pretrain your own OlmoEarth model are available in Pretraining.md.
Detailed instructions on how to replicate our evaluations is available here:
Tests can be run with different dependency configurations using uv run:
# Full test suite (all dependencies except flash-attn, including olmo-core)
uv run --extra all-no-flash pytest tests/
# Model loading tests with full deps (with olmo-core)
uv run --extra all-no-flash pytest tests_minimal_deps/
# Model loading tests with minimal deps only (no olmo-core)
uv run --extra dev pytest tests_minimal_deps/The tests_minimal_deps/ directory contains tests that verify model loading works both with and without olmo-core installed. These run twice in CI to ensure compatibility.
This code is licensed under the OlmoEarth Artifact License.