
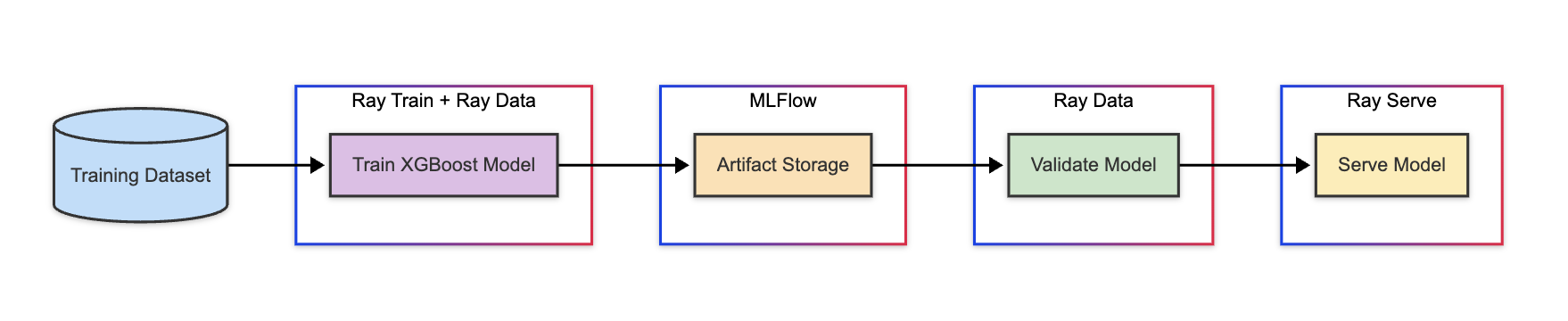
This tutorial implements an end-to-end XGBoost application on Anyscale, covering:
- Distributed data preprocessing and model training: Ingest and preprocess data at scale using Ray Data. Then, train a distributed XGBoost model using Ray Train
notebooks/01-Distributed_Training.ipynb - Model Validation using Offline Inference: Evaluate the model using Ray Data offline batch inference
notebooks/02-Validation.ipynb. - Online Model Serving: Deploy the model as a scalable online service using Ray Serve. For example,
notebooks/03-Serving.ipynb - Production Deployment: Create production batch Jobs for offline workloads (data prep, training, batch prediction) and potentially online Services.
Install the dependencies using pip:
pip install -r requirements.txt
# For development only, install the dev dependencies:
# pip install -r requirements_dev.txt
# Install the dist_xgboost package
pip install -e .This application was developed on Anyscale Workspaces, enabling development without thinking about infrastructure, just like on a laptop. Workspaces come with:
- Development tools: Spin up a remote session from your local IDE (cursor, VSCode) and start coding, using the same tools you love but with the power of Anyscale's compute.
- Dependencies: Continue to install dependencies using familiar tools like pip. Anyscale ensures proper dependency distribution to your cluster.
- Scalable Compute: Leverage any reserved instance capacity, spot instance from any compute provider of your choice by deploying Anyscale into your account. Alternatively, you can use the Anyscale cloud for a full cloud-native experience.
- Under the hood, Anyscale creates and smartly manages a cluster.
- Debugging: Leverage a distributed debugger to get the same VSCode-like debugging experience.
Learn more about Anyscale Workspaces through the official documentation.
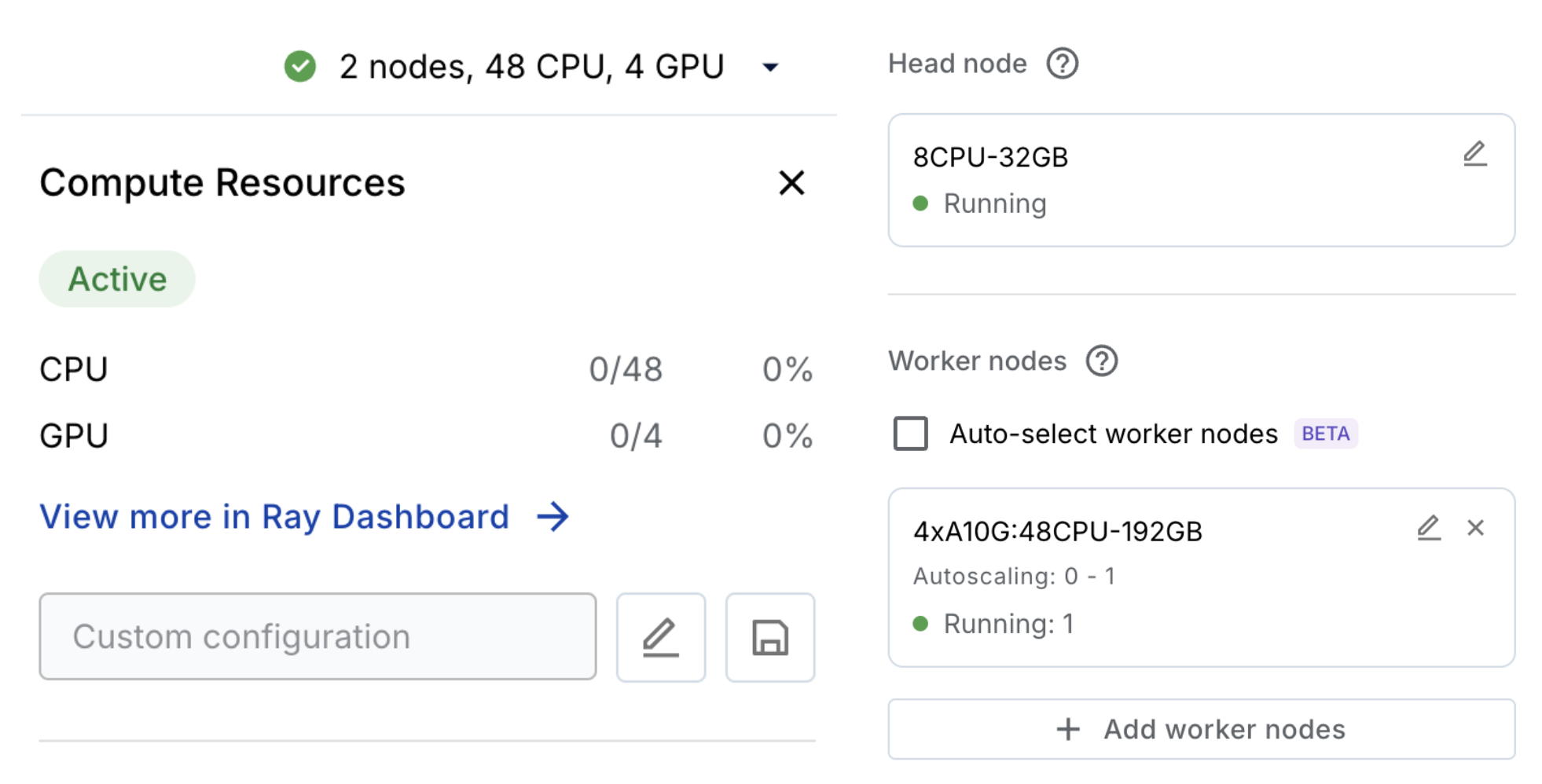
Seamlessly integrate with your existing CI/CD pipelines by leveraging the Anyscale CLI or SDK to deploy highly available services and run reliable batch jobs. Development in an environment that's almost identical to production (multi-node cluster) drastically speeds up dev → prod velocity. This includes proprietary RayTurbo features to optimize workloads for performance, fault tolerance, scale, and observability.
Abstract away infrastructure from your ML/AI developers so they can focus on their core ML development. You can additionally better manage compute resources and costs with the enterprise governance and observability and administrator capabilities so you can set resource quotas, set priorities for different workloads and gain observability of your utilization across your entire compute fleet. If you're already on a Kubernetes cloud (Amazon Elastic Kubernetes Service, Google Kubernetes Engine, etc.), then you can still leverage the proprietary optimizations from RayTubo you can see in action in these tutorials through the Anyscale K8s Operator.
Below is a list of infrastructure headaches Anyscale removes so you can focus on your ML development.👇
Click here to see the infrastructure pains Anyscale removes
🚀 1. Fast Workload Launch
- With Kubernetes (Amazon Elastic Kubernetes Service/Google Kubernetes Engine), you must manually create a cluster before launching anything.
- This includes setting up VPCs, Identity and Access Management roles, node pools, autoscaling, etc.
- Anyscale handles all of this automatically; you just define your job or endpoint and run it.
⚙️ 2. No GPU Driver Hassles
- Kubernetes requires you to install and manage NVIDIA drivers and the device plugin for GPU workloads.
- On Anyscale, GPU environments just work—drivers, libraries, and runtime are pre-configured.
📦 3. No KubeRay or CRD Management
- Running Ray on K8s needs:
- Installing KubeRay
- Writing and maintaining custom YAML manifests
- Managing Custom Resource Definitions
- Tuning stateful sets and pod configuration
- On Anyscale, this is all abstracted—you launch Ray clusters without writing a single YAML file.
🧠 4. No Need to Learn K8s Internals
- With Kubernetes, users must:
- Inspect pods/logs
- Navigate dashboards
- Manually send http requests to Ray endpoints
- Anyscale users never touch pods. Everything is accessible through the CLI, SDK, or UI.
💸 5. Spot Instance Handling Just Works
- Kubernetes requires custom node pools and lifecycle handling for spot instance interruptions.
- With Anyscale, preemptible VMs are automatically managed with node draining and rescheduling.