You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: docs/tutorials/integrating-autoware/tuning-parameters-and-performance/evaluation/evaluating-real-time-performance/index.md
+3-3Lines changed: 3 additions & 3 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -118,7 +118,7 @@ Refer to the [Pull Request](https://github.com/autowarefoundation/autoware_unive
118
118
119
119
The following figure is a time-series plot of the turnaround time of the main processing part of `ring_outlier_filter`, analyzed as described in the "Performance Measurement" section above.
The horizontal axis indicates the number of callbacks called (i.e., callback index), and the vertical axis indicates the turnaround time.
124
124
@@ -127,7 +127,7 @@ When analyzing the performance of the sensing module from the viewpoint of perfo
127
127
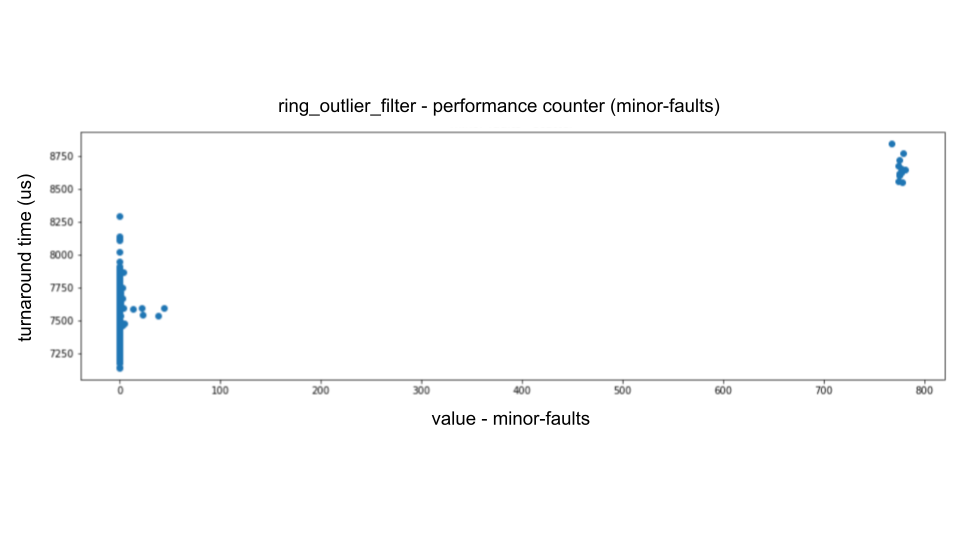
Analysis of the performance counter shows that the largest fluctuations come from `minor-faults` (i.e., soft page faults), the second largest from `LLC-store-misses` and `LLC-load-misses` (i.e., cache misses in the last level cache), and the slowest fluctuations come from instructions (i.e., message data size fluctuations).
128
128
For example, when we plot `minor-faults` on the horizontal axis and turnaround time on the vertical axis, we can see the following dominant proportional relationship.
129
129
130
-
130
+

131
131
132
132
To achieve zero soft page faults, heap allocations must only be made from areas that have been first touched in advance.
133
133
We have developed a library called [`heaphook`](https://github.com/tier4/heaphook) to avoid soft page faults while running Autoware callback.
@@ -176,7 +176,7 @@ First, we will pick up `detection_area` module in `behavior_velocity_planner` no
176
176
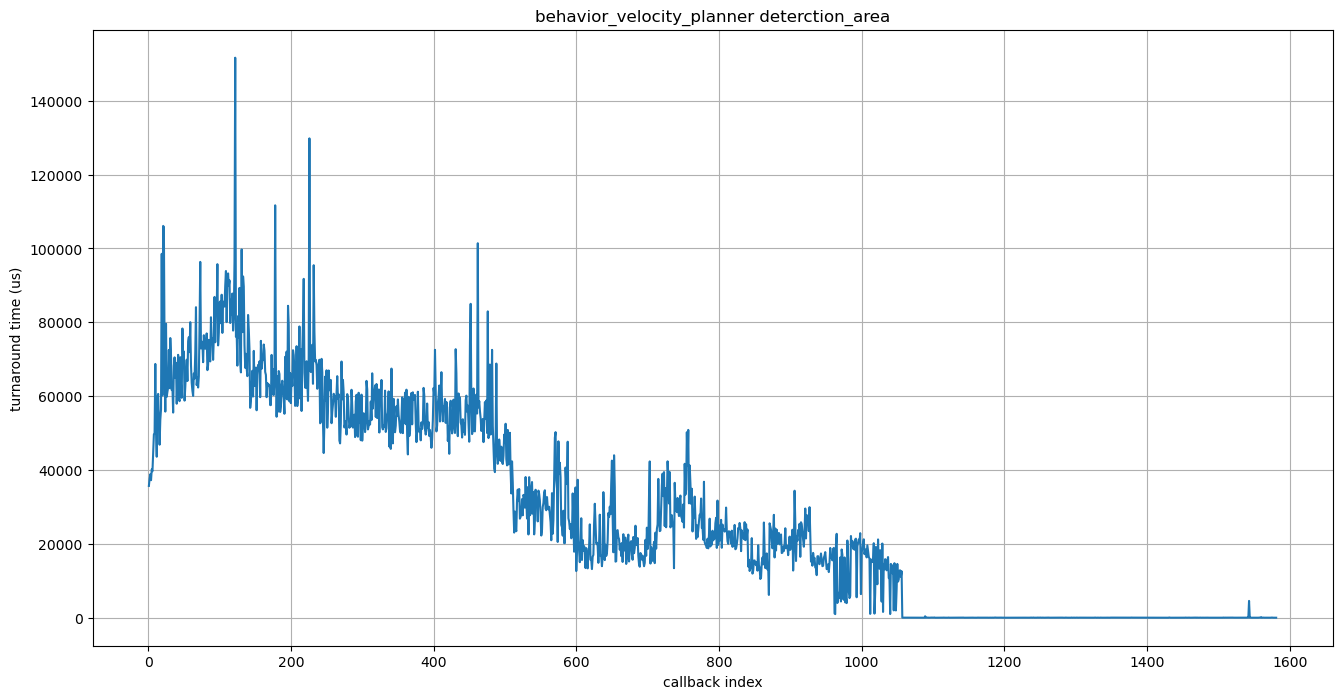
We have followed the performance analysis steps above to obtain the following graph.
177
177
Axises are the same as the graphs in the sensing case study.
178
178
179
-
179
+

180
180
181
181
Using [`pmu_analyzer`](https://github.com/sykwer/pmu_analyzer) tool to further identify the bottleneck, we have found that the following multiple loops were taking up a lot of processing time:
0 commit comments