The code repository for paper "Kalman Filter Enhanced Group Relative Policy Optimization for Language Model Reasoning".
conda create --name krpo python=3.12 -y
conda activate krpo
conda install -c conda-forge cudatoolkit cudatoolkit-dev -y
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
The base model is Llama-3.2-1B-Instruct, please follow the huggingface to fetch the model https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
For model training, the commandline is:
bash run.sh [GPU id]
For instance:
bash run.sh 0
For model evaluation, the resume path of the tested model can be specified in the eval_krpo.sh file. The evaluation can be performed with:
bash eval.sh [GPU id]
For example:
bash eval.sh 0
In both train.py and eval.py, group_advantages_baseline() function is how the baseline model gets group advantages.
Performed more experiments with base models Qwen2.5-0.5B-Instruct and Qwen2.5-1.5B-Instruct on Normal level difficulty Arithmetic questions:
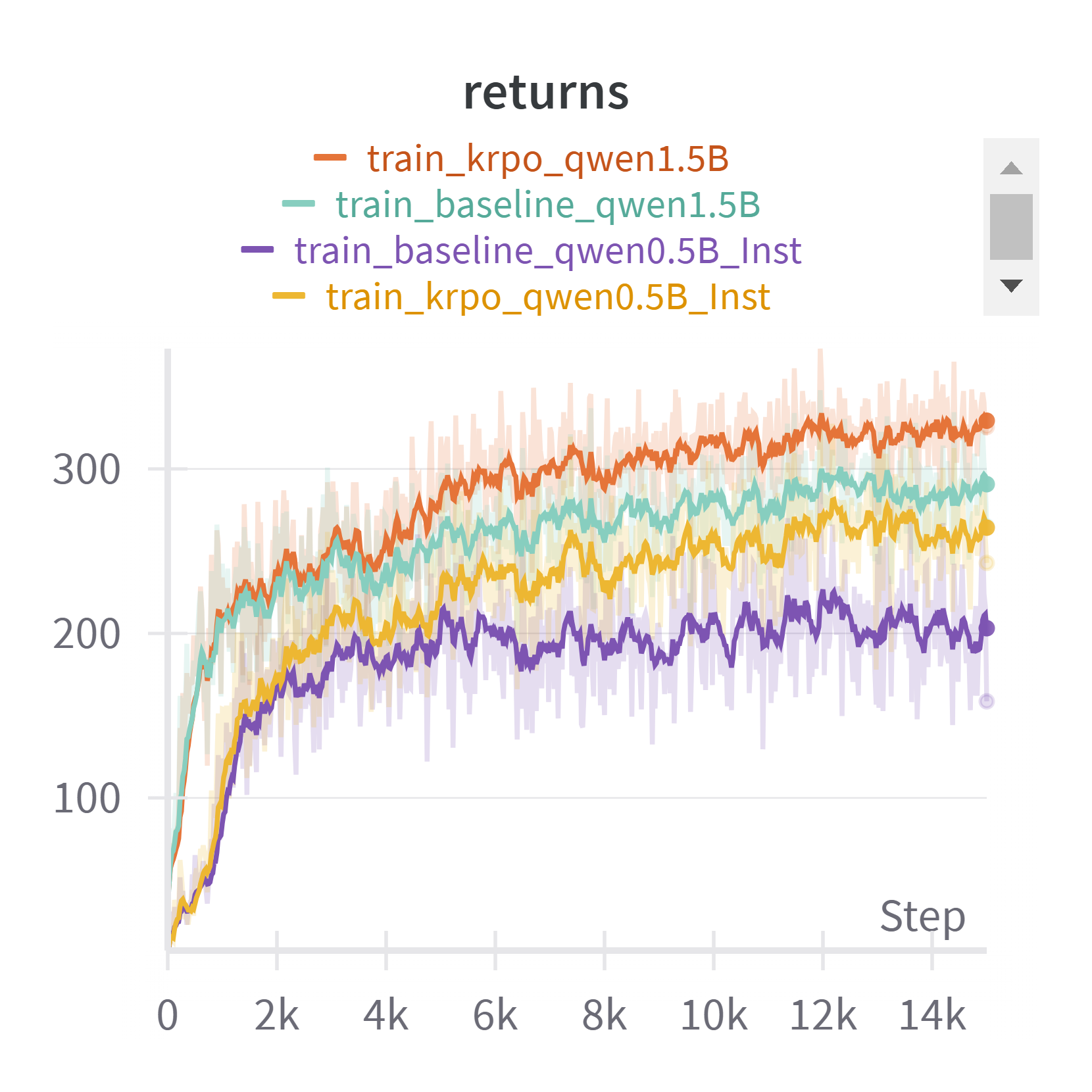
Also on additional datasets --- AMC and AIME:

If you got a chance to use our code, you can cite us!
Enjoy!!