A number of Python-related libraries exist for the programming of solutions either employing multiple CPUs or multicore CPUs in a symmetric multiprocessing (SMP) or shared memory environment, or potentially huge numbers of computers in a cluster or grid environment.
There are many levels to parallel processing:
- Single Machine
- threading in Python
- uses threads
- threads run in the same memory space
- multiprocessing Python Package
- uses processes
- processes have separate memory
- Create Queue and Process
- Add a Process (method and arguments) to the queue
- Start running and block until all completed
- -- or --
- Create a process Pool()
- Use the Pool() map functionality (map / reduce)
- threading in Python
- GPU
- CPU has multiple cores, GPU have thousands of cores
- pyCUDA
- Cluster Computing / Distributed Processing
- Unlike SMP architectures and especially in contrast to thread-based concurrency, cluster (and grid) architectures offer high scalability due to the relative absence of shared resources
Basic view of distributed computing...
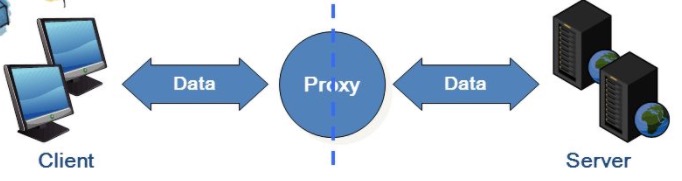 from http://slideplayer.com/slide/7076521/
from http://slideplayer.com/slide/7076521/
-
Client - where we run our main script
-
Proxy - "Broker" which can be Redis or RabbitMQ (essentially a key-value store)
-
Server - Worker process(es)
$ celery worker
-
Client - where we run our main script
-
Proxy - Scheduler process
$ dask-scheduler -
Server - Worker process(es)
$ dask-worker
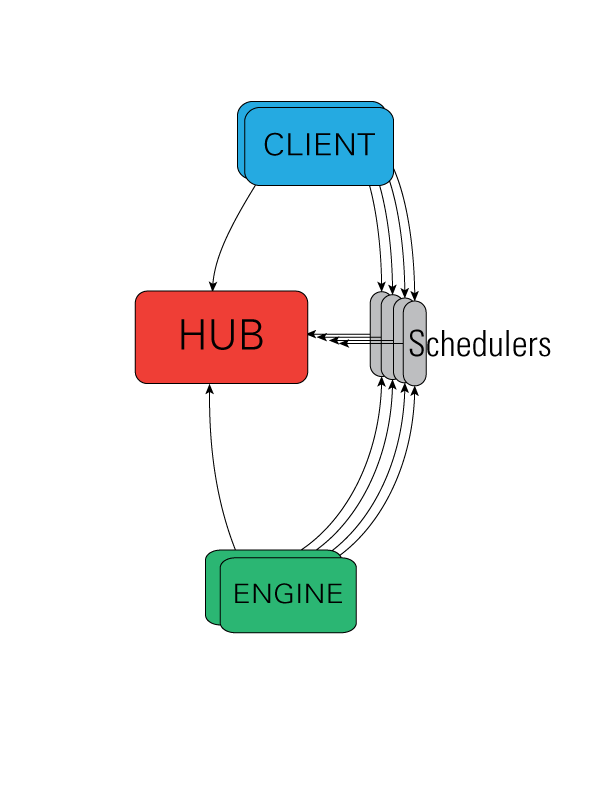
The IPython architecture consists of four components:
- IPython engine - The engine listens for requests over the network, runs code, and returns results
- IPython controller - provide an interface for working with a set of engines (Scheduler and Hub)
- IPython hub - process that keeps track of engine connections, schedulers, clients, as well as all task requests and results.
- IPython scheduler - all actions that can be performed on the engine go through a Scheduler
- IPython client
Many, many others out there https://wiki.python.org/moin/ParallelProcessing
Also, Dask and ipyparallel have some connectability with Juptyer notebooks.