feat(ingest/kinesis): AWS Kinesis Data Streams + Amazon Data Firehose source#17592
feat(ingest/kinesis): AWS Kinesis Data Streams + Amazon Data Firehose source#17592treff7es wants to merge 16 commits into
Conversation
… source
Adds a new ingestion source covering both AWS streaming services under
two DataHub platforms that mirror AWS's own service split:
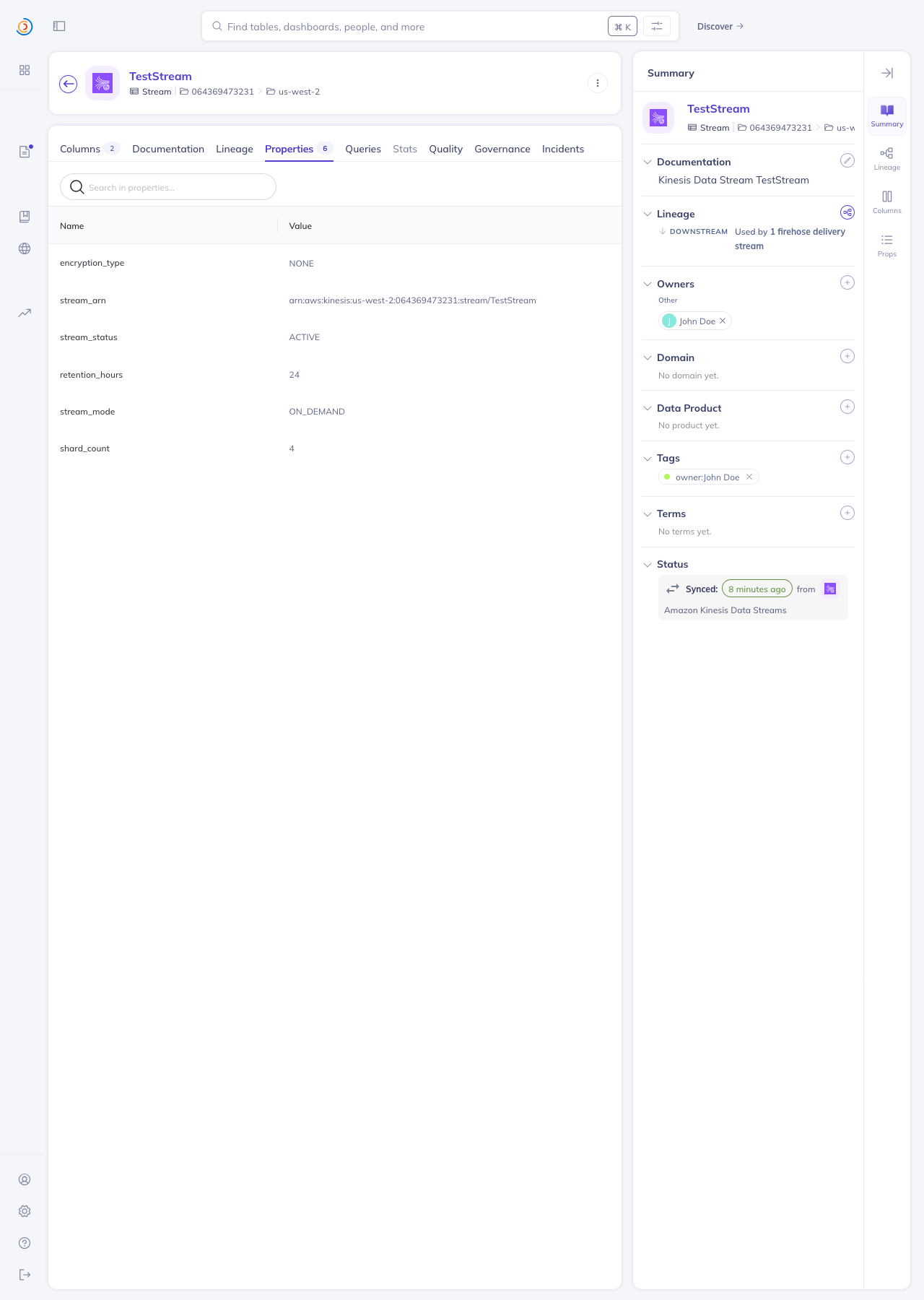
- `kinesis` (display name: *Amazon Kinesis Data Streams*) — KDS streams
as Datasets (`Stream` subtype) under a regional Container, with
custom properties (ARN, shard count, retention, encryption, stream
mode), AWS resource tags as DataHub tags, configurable
tag-key-as-ownership, and optional `schemaMetadata` resolved from
AWS Glue Schema Registry.
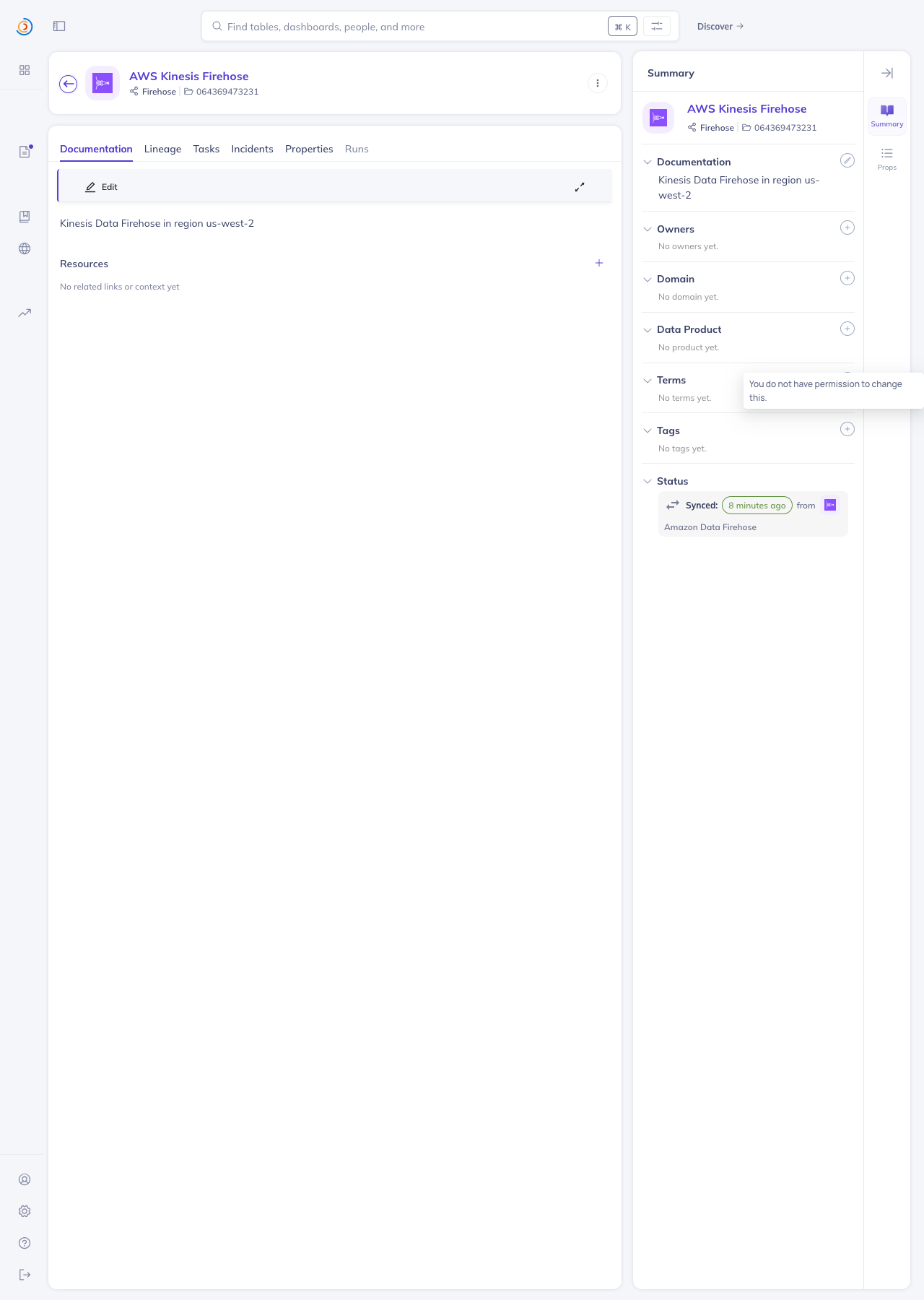
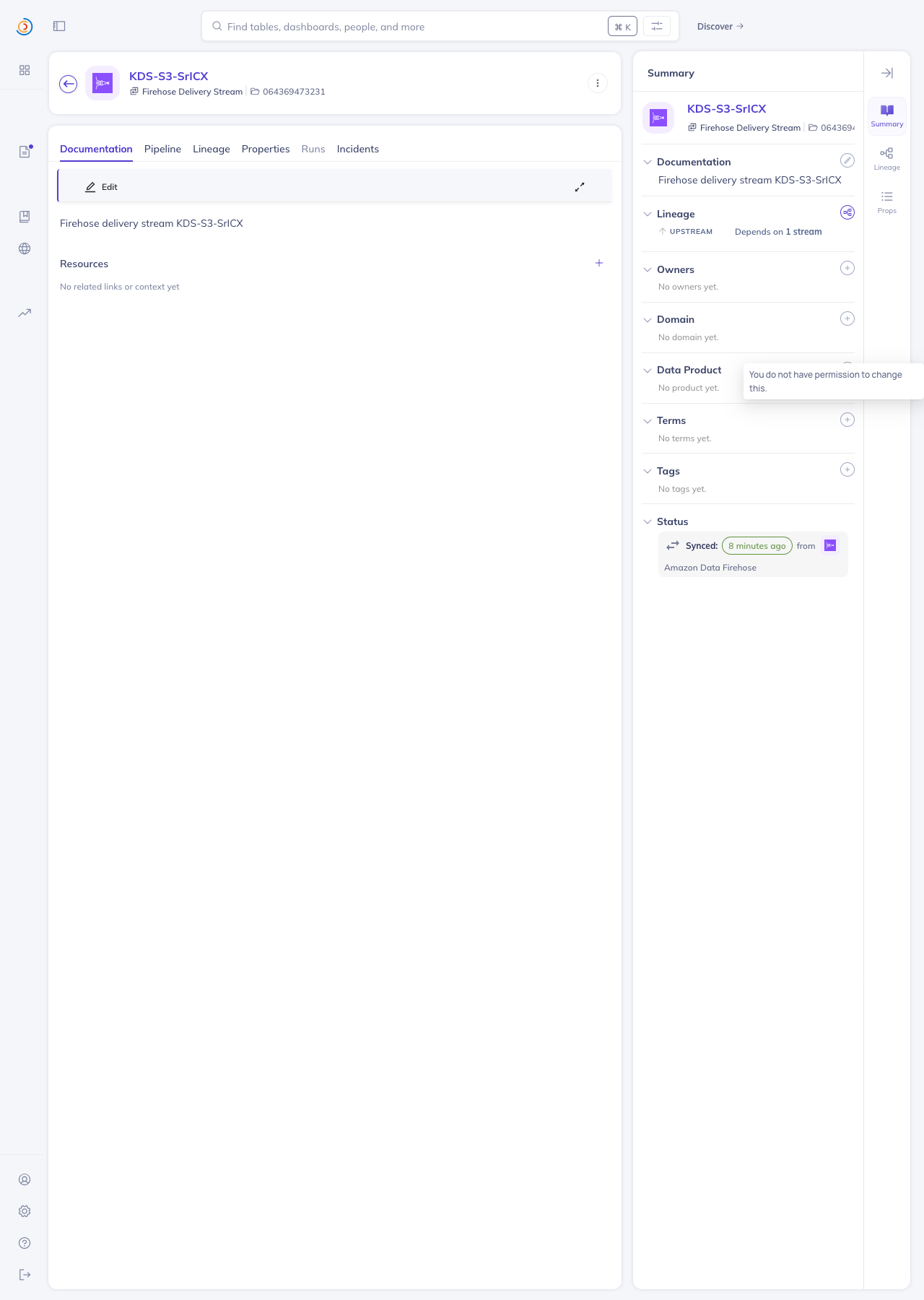
- `kinesis-firehose` (display name: *Amazon Data Firehose*) — Firehose
delivery streams as DataJobs (`Firehose Delivery Stream` subtype)
under one regional DataFlow per recipe (`Firehose` subtype), with
`dataJobInputOutput` edges from the source Kinesis stream to the
destination platform. Six Firehose destinations supported with their
own URN handlers: S3, Redshift, OpenSearch/Elasticsearch, Snowflake,
Apache Iceberg, MongoDB.
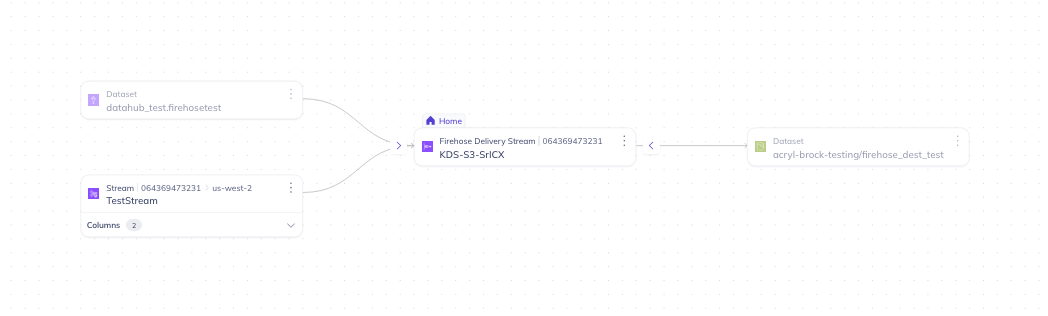
The two platforms share one connector, one IAM policy, and one
ingestion run — both are emitted from a single recipe. The split
mirrors AWS's service / API namespace / IAM-prefix split (KDS vs KDF)
and makes cross-service lineage (`Stream → Firehose → S3`) visually
distinct in the lineage viewer.
Capabilities (per `@capability` decorators):
- DESCRIPTIONS, CONTAINERS, LINEAGE_COARSE, TAGS, OWNERSHIP,
SCHEMA_METADATA (opt-in via `glue_schema_registry.enabled`),
DELETION_DETECTION (via stateful ingestion).
Cross-platform lineage configuration:
- `destination_platform_map` accepts per-destination overrides for
`platform_instance`, `env`, and `convert_urns_to_lowercase`
(default `True`, mirroring Snowflake source's default). Set
`convert_urns_to_lowercase: false` for case-sensitive destinations
(Iceberg, MongoDB) or when the destination's own source recipe set
that flag to False.
Firehose format-conversion lineage:
- Extended S3 destinations with `DataFormatConversionConfiguration`
surface the referenced Glue Catalog table as an additional UPSTREAM
on the Firehose DataJob, because that table's schema governs what
gets written to S3.
Schema Registry (opt-in):
- Avro / JSON / Protobuf schemas fetched from AWS Glue Schema
Registry via `glue:GetSchemaVersion`. Two resolution routes:
explicit `stream_schema_map` (recommended) or
`use_naming_convention: true` (off by default — AWS doesn't define
a stream↔schema relationship, unlike Kafka's TopicNameStrategy).
Identity:
- Account-id auto-resolved at source init via
`sts:GetCallerIdentity`. The connector composes
`<account_id>-<region>` as the default `platform_instance` so URNs
disambiguate across accounts and regions.
Stateful ingestion:
- `StaleEntityRemovalHandler` wired in. Entities removed from AWS
since the last successful run are soft-deleted in DataHub. Requires
`platform_instance` to be set (auto-resolved or explicit).
Error-handling discipline:
- Per-stream / per-delivery-stream failures (AccessDenied,
network errors) are recoverable: a single resource's failure
surfaces as `report.warning`, the connector continues with the
next.
- List-API mid-pagination failures escalate to `report.failure`
(with explicit soft-delete-risk wording) because partial data
would let stateful ingestion incorrectly soft-delete un-listed
streams on the next run.
- All boto3 callsites catch `(ClientError, BotoCoreError)` via a
shared `aws_error_code` helper.
Tests:
- 108 unit tests across 13 files (config, identity, region, report,
schema registry, tagging, stateful, firehose, firehose
destinations, stream, aws_utils, connection).
- 1 LocalStack integration test with a 24KB / 805-event golden file
exercising the full flow (KDS streams + Firehose delivery streams
+ S3 lineage + tags + ownership).
Documentation:
- Full docs under `docs/sources/kinesis/` (README.md + kinesis_pre.md
+ kinesis_post.md + kinesis_recipe.yml).
- Both platforms registered in `data-platforms.yaml` with the
official AWS architecture icons.
- Discoverability: separate `kinesis-firehose` entry in the
integrations catalog (`supported_via: kinesis`) and the docs
sidebar (ref entry pointing at the same Kinesis page) so users
searching for "Firehose" or "Amazon Data Firehose" find the docs.
Not currently supported (called out in docs Limitations section):
- USAGE_STATS via CloudWatch metrics
- Multi-region ingestion in a single recipe (run one per region)
- Multi-registry GSR support in a single recipe
- Schema inference from record sampling (relies on GSR)
- Lambda consumer discovery
- Kinesis Data Analytics (KDA / managed Flink)
- Firehose destinations beyond the six listed above (HTTP, Datadog,
Splunk, New Relic, Coralogix, LogicMonitor, Dynatrace, Honeycomb,
Sumo Logic)
- Glue Schema Registry cross-schema references ($ref / named imports)
Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
|
Linear: ING-2764 |
Codecov Report❌ Patch coverage is 📢 Thoughts on this report? Let us know! |
|
🔴 Meticulous spotted visual differences in 30 of 1554 screens tested: view and approve differences detected. Meticulous evaluated ~10 hours of user flows against your PR. Last updated for commit |
Bundle ReportChanges will increase total bundle size by 5.45kB (0.02%) ⬆️. This is within the configured threshold ✅ Detailed changes
Affected Assets, Files, and Routes:view changes for bundle: datahub-react-web-esmAssets Changed:
|
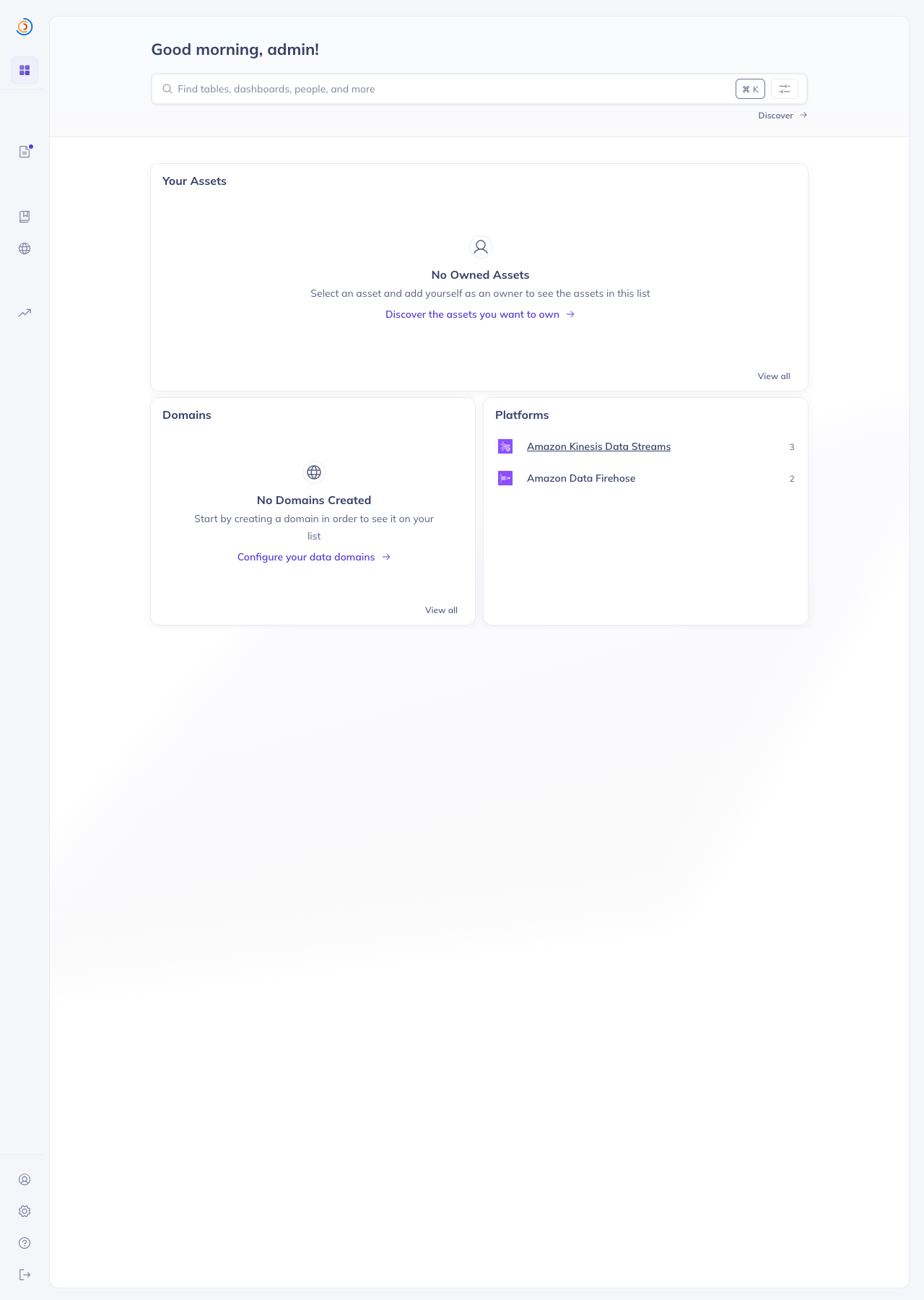
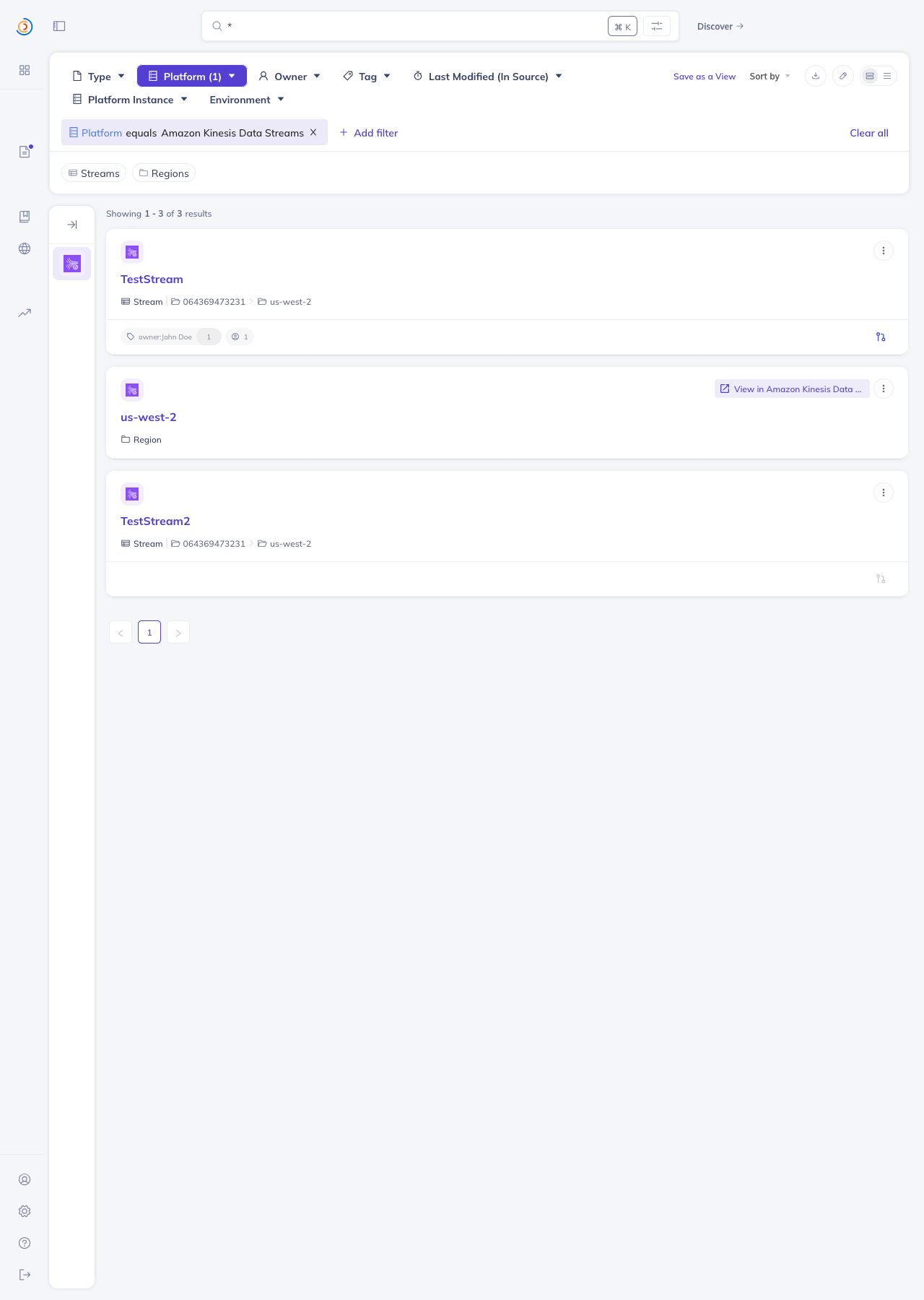
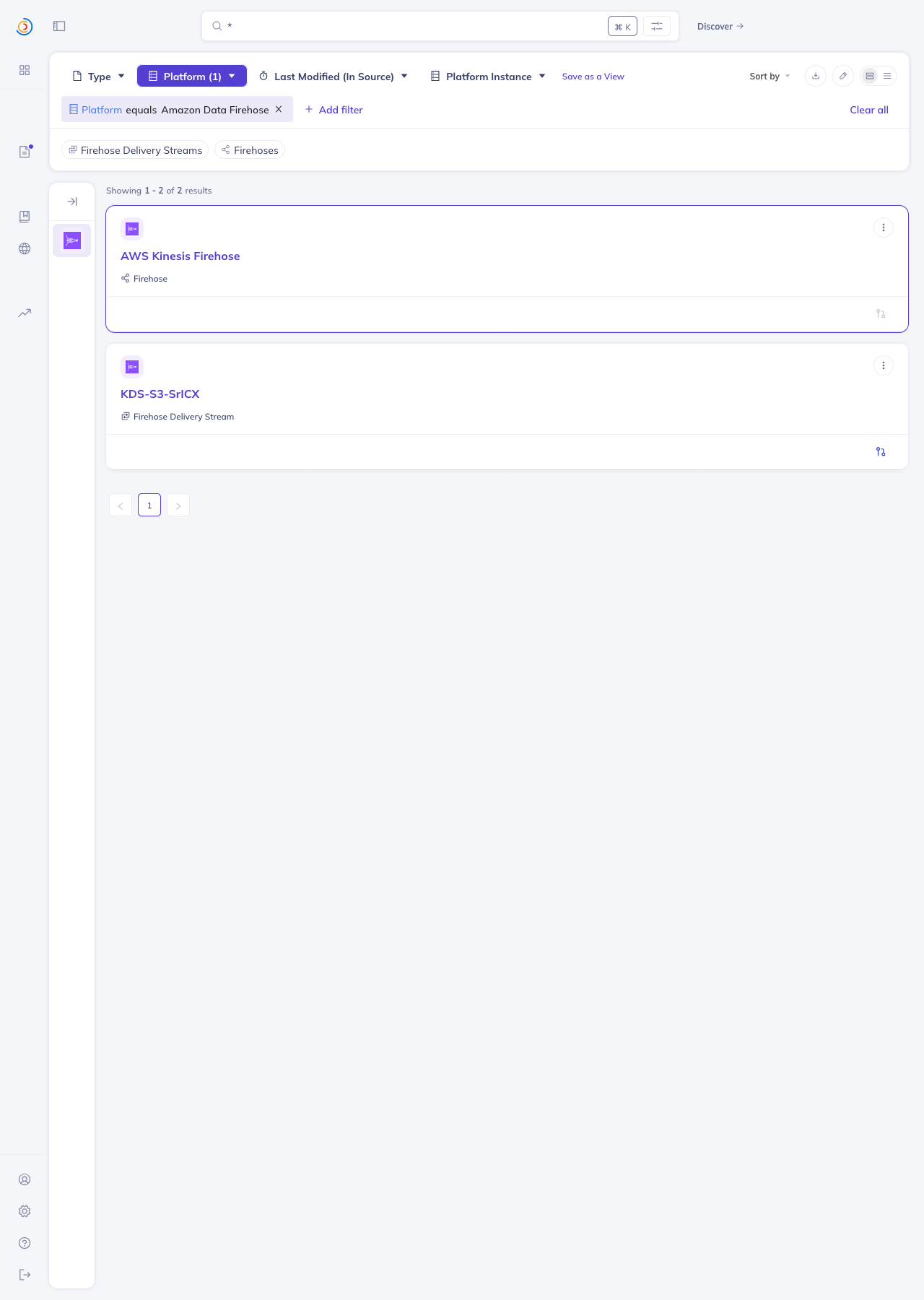
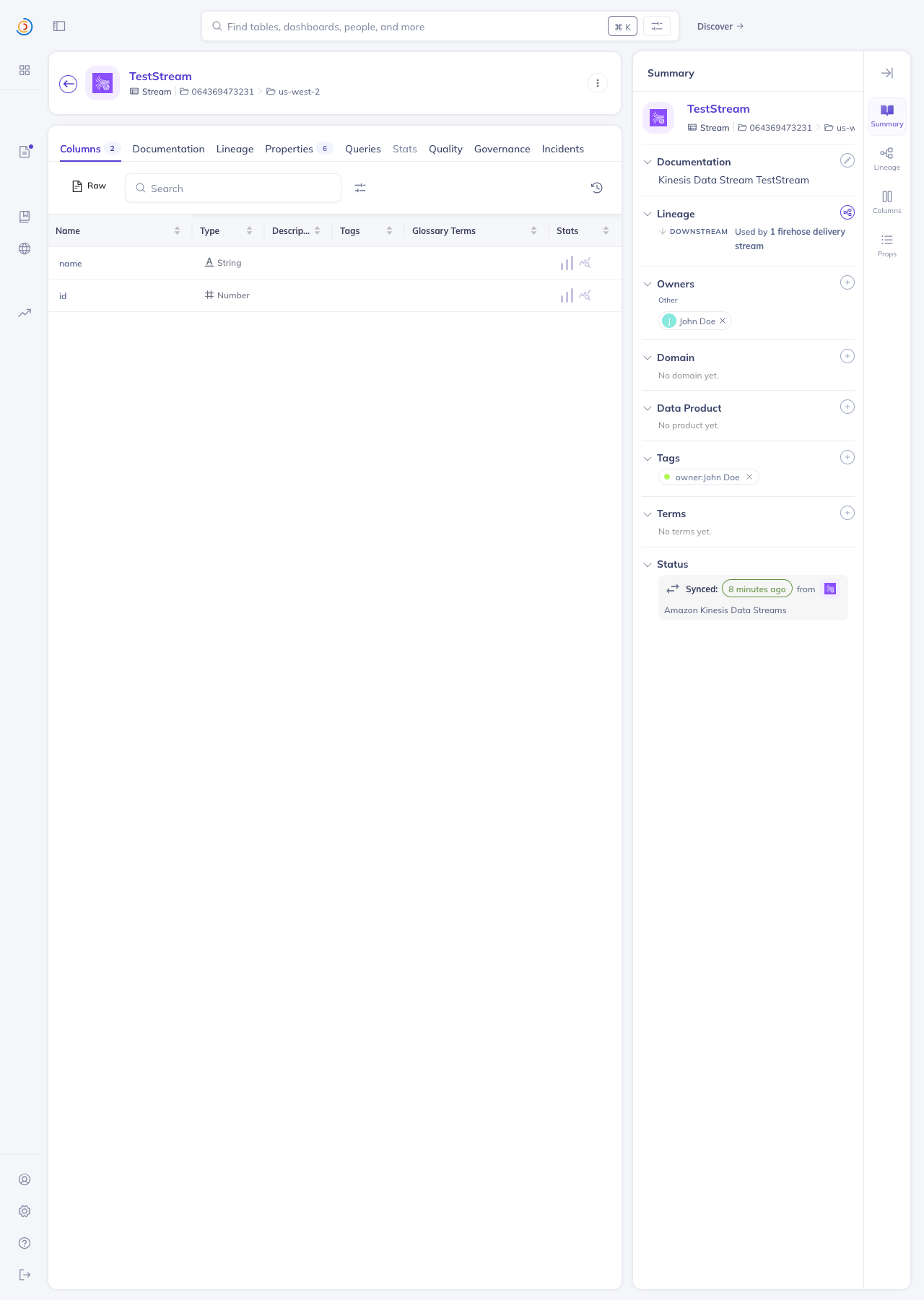
Screenshots from local DataHubIngested against an AWS sandbox account (us-west-2) with 2 KDS streams and 1 Firehose delivery stream, producing the full chain Home page — both platforms registered with the right names + icons
Browse
|
- mypy: narrow boto3 typed-client mocks with cast(MagicMock, ...), narrow MetadataWorkUnit unions with isinstance(MetadataChangeProposalWrapper), type setup_test_data._client service as Literal["kinesis","s3","firehose","iam"], drop redundant avro.schema.parse() in kinesis_schema_registry (the schema_util helper already accepts a raw str and parses internally; pass swallow_exceptions=False to preserve our parse-failed reporting), add assert region is not None in _emit_region_container (constructor already validates this; the assert just propagates the narrowing). - markdown: apply :datahub-web-react:mdPrettierWrite (table-cell padding in README.md and kinesis_post.md; no content changes). No `# type: ignore` comments added — all fixes use proper type-narrowing constructs.
…rotobuf_util CI's validate-plugin-deps job builds a fresh venv with only the declared [kinesis] extras and imports the source. Two issues surfaced: 1. pyproject.toml is the source of truth for optional-dependencies (it overrides setup.py's extras_require). The setup.py entry "kinesis": aws_common was being ignored. Add the equivalent kinesis = [boto3, botocore, urllib3] block to pyproject.toml. 2. kinesis_schema_registry.py imported protobuf_util at module level, which transitively pulls in grpc/networkx/google.protobuf — none of which are part of aws_common. Move the import inside the `if data_format == "PROTOBUF":` branch so the bare kinesis install stays small (boto3-only) and protobuf deps are only required when the GSR actually serves a protobuf-format schema.
…tern) The previous commit lazy-imported protobuf_util to avoid pulling grpc/networkx/protobuf into the base kinesis install. Reverting to match how kafka handles the same situation: protobuf_util is imported at module load time and the heavy deps are declared in the plugin's extras. Kinesis and kafka are structurally similar (schema-registry- backed sources that handle AVRO/JSON/PROTOBUF) so they should follow the same pattern. Adds grpcio, grpcio-tools, networkx to the kinesis extras — the same trio kafka declares.
…en lock setup.py is the source of truth (scripts/generate_pyproject_deps.py emits pyproject.toml from it). Add kafka_protobuf to the kinesis extras so grpcio/grpcio-tools/networkx are installed by 'pip install acryl-datahub[kinesis]', then regenerate pyproject.toml, uv.lock, and constraints.txt via :metadata-ingestion:updateLockFile. kafka_protobuf is reused as-is — the same trio kafka declares for the same module (protobuf_util imported by both kafka's confluent_schema_registry and kinesis_schema_registry). The name is a misnomer for kinesis but renaming it touches kafka and is out of scope here.
# Conflicts: # metadata-ingestion/uv.lock
Connector Tests ResultsAll connector tests passed for commit To skip connector tests, add the Autogenerated by the connector-tests CI pipeline. |
…and regional DataFlow
Each entity now carries an AWS console link in its primary aspect:
- KDS Stream (Dataset, datasetProperties.externalUrl):
https://console.aws.amazon.com/kinesis/home?region={r}#/streams/details/{name}
- Firehose Delivery Stream (DataJob, dataJobInfo.externalUrl):
https://console.aws.amazon.com/firehose/home?region={r}#/details/{name}
- Firehose regional DataFlow (dataFlowInfo.externalUrl):
https://console.aws.amazon.com/firehose/home?region={r}
The regional Container already had its external URL set. Golden file
regenerated with the new aspects.
# Conflicts: # metadata-ingestion/setup.py # metadata-ingestion/uv.lock # metadata-service/configuration/src/main/resources/bootstrap_mcps.yaml
| The Kinesis source ships in the base `acryl-datahub` package — `boto3` is already a core dependency, so there is no separate `[kinesis]` extra: | ||
|
|
||
| ```shell | ||
| pip install 'acryl-datahub' | ||
| ``` |
There was a problem hiding this comment.
setup.py and pyproject.toml, which add a [kinesis]
# setup.py:720-722
# kafka_protobuf reused for Glue Schema Registry PROTOBUF support
# (kinesis_schema_registry imports protobuf_util at module load).
"kinesis": aws_common | kafka_protobuf,
pip install 'acryl-datahub' will hit ModuleNotFoundError: No module named grpc the moment the source loads. The doc should say pip install acryl-datahub[kinesis].
|
|
||
| Notes on each statement: | ||
|
|
||
| - **`AccountIdentityRead`** — used at source init to call `sts:GetCallerIdentity` and resolve the AWS account ID. The connector uses the account ID as part of the default `platform_instance` (`<account_id>-<region>`) so URNs disambiguate across accounts and regions. If you omit this statement (or `sts:GetCallerIdentity` is denied), the connector logs a warning and continues with `platform_instance=None`; URNs then won't include the account ID, so cross-account collision-safety depends on you setting `platform_instance` explicitly in the recipe. |
There was a problem hiding this comment.
This says the default platform_instance is <account_id>-<region>, but the code sets it to account_id alone (kinesis.py:150), and the comment above it explicitly keeps region out of platform_instance
| # typos at typecheck time: `make_client(session, "firhose")` fails the | ||
| # Literal check instead of returning a misconfigured boto3 client whose | ||
| # first API call surfaces an unhelpful botocore error. "sts" intentionally | ||
| # omitted — `_resolve_account_id` constructs it directly via |
There was a problem hiding this comment.
Minor: _resolve_account_id builds STS via self._session.client("sts"), so aws_config.aws_endpoint_url isn't applied to STS (only the AWS_ENDPOINT_URL env var is) — unlike every other client, which goes through make_client. It degrades gracefully (warning + platform_instance=None), so not a blocker, but it's inconsistent, and against a custom data endpoint with public STS reachable it could resolve a real account id that doesn't match the data source. The comment in kinesis_config.py:36-38 ("runs before the rest of the config is loaded") is also inaccurate — this runs in __init__ with full config. Consider adding "sts" to the AwsService Literal and routing through make_client.
| yield from gen_containers( | ||
| container_key=region_key, | ||
| name=region, | ||
| sub_types=["Region"], |
There was a problem hiding this comment.
Minor: Should we add this to common.subtypes.py.
|
|
||
| def _region_key(self) -> KinesisRegionKey: | ||
| return KinesisRegionKey( | ||
| region=self.config.aws_config.aws_region or "unknown", |
There was a problem hiding this comment.
or "unknown" here is unreachable — __init__ (kinesis.py:133-138) raises ValueError if the region can't be resolved, so aws_region is always set by the time _region_key runs
| region=self.config.aws_config.aws_region or "unknown", | |
| region=self.config.aws_config.aws_region", |
|
|
||
| @pydantic.field_validator("env") | ||
| @classmethod | ||
| def validate_env(cls, v: Optional[str]) -> Optional[str]: |
There was a problem hiding this comment.
DestinationPlatformDetail.validate_env diverges from standard env handling. It rebuilds the env set via vars(FabricTypeClass) reflection with no .upper() normalization, so env: prod is accepted at the top level (EnvConfigMixin uppercases it) but raises ValueError inside a destination_platform_map entry.
Suggestion reuse ALL_ENV_TYPES from datahub.emitter.mce_builder and .upper()-normalizing.
| "this source's env." | ||
| ), | ||
| ) | ||
| convert_urns_to_lowercase: bool = Field( |
There was a problem hiding this comment.
Should we keep default as False?
There was a problem hiding this comment.
True is the default in other platforms to make sure urns going to match
…ocs, normalize destination env, route STS through make_client, sanitize protobuf stream names, dedup subtype/platform constants
…on/platform_instance myth, trim IAM policy to used permissions, fix per-region platform_instance guidance, declare SCHEMA_METADATA capability
… aws_error_code - Drop the connector's built-in tags-as-ownership (config extract_owners/owner_tag_key, helpers, capability, emission). Ownership is now derived from the emitted globalTags via the standard extract_ownership_from_tags transformer, documented in the connector docs + starter recipe. Avoids duplicating a platform feature per connector. - Move the generic aws_error_code helper from kinesis_aws_utils into aws/aws_common.py (and its tests into test_aws_common); delete the kinesis-local module. - Regenerate the connector registry (kinesis no longer advertises OWNERSHIP). - Update unit tests, integration recipes, and the golden file; integration test passes.
…uilder, surface dropped lineage Addresses high/medium findings from the connector review: - Consolidate the near-identical fetch_tags into a shared fetch_aws_resource_tags helper in kinesis_tagging (HIGH). - Extract _platform_instance_aspect() (firehose DataFlow + DataJob) and a shared report_listing_failure() for the first-page-vs-mid-pagination templates (MEDIUM). - Replace urn_builder: Callable[..., str] with a DestinationUrnBuilder Protocol so handler call-site keyword typos are caught (MEDIUM). - _source_stream_urn now warns when a KinesisStreamAsSource ARN is unparseable instead of silently dropping the upstream edge (MEDIUM). - Add tests: JSON GSR parsing, malformed-source-ARN warning. Skipped (not defects): config post-init mutation (standard DataHub source pattern; asserts narrow Optional for mypy) and env-as-Literal (matches EnvConfigMixin).
…berg drops, drop dead tag guard, add tests - Surface partial Iceberg table drops (some valid, one missing DestinationTableName) at the orchestrator — previously a non-empty result slipped past the matched-but-empty net silently (MEDIUM). - Remove the dead `extract_tags` ternary in both extractors (fetch_tags already returns [] when disabled; build_global_tags_from_aws_tags([]) is None) (MEDIUM). - Add tests: region resolution + ValueError, _custom_properties ON_DEMAND/default stream-mode, OpenSearch legacy key + missing IndexName, MongoDB missing field, Iceberg partial-drop reporting. - Drop stale "Task N" dev comments and a stale platform_instance docstring.
The warn_if_configured_but_disabled validator guarded stream_schema_map but not use_naming_convention — the other activation knob, equally inert when enabled=False. Make the invariant symmetric so a use_naming_convention:true / enabled:false recipe fails fast instead of silently doing nothing. Updates the disabled-short-circuit test to a valid bare-disabled config and adds a rejection test for the new case.
… ingest Refactor the Kinesis integration test to the repo's standard harness instead of the bespoke subprocess strategy: - Use the docker_compose_runner fixture + wait_for_port (as delta_lake/neo4j/ clickhouse do) instead of shelling out to `docker compose up/down` with a hand- rolled health poll. - Seed test data in-process via boto3 fixtures; delete the standalone setup_test_data.py that was invoked via subprocess. - Run ingestion in-process via run_datahub_cmd instead of subprocess to the `datahub` CLI — removes the DATAHUB_BIN/"stale global datahub" workaround. - File sink writes a relative path (run_datahub_cmd isolates to tmp_path); add an explicit container_name so wait_for_port can exec the LocalStack container. Golden output is byte-identical; integration test passes against LocalStack 3.0.
Summary
Adds a new ingestion source covering both AWS streaming services under two DataHub platforms that mirror AWS's own service split:
kinesis(display name: Amazon Kinesis Data Streams) — KDS streams as Datasets (Streamsubtype) under a regional Container.kinesis-firehose(display name: Amazon Data Firehose) — Firehose delivery streams as DataJobs (Firehose Delivery Streamsubtype) under one regional DataFlow per recipe.The two platforms share one connector, one IAM policy, and one ingestion run.
Capabilities
DESCRIPTIONS,CONTAINERS,TAGS,OWNERSHIPLINEAGE_COARSE— FirehosedataJobInputOutputedges from the source KDS stream to the destination platform (S3, Redshift, OpenSearch/Elasticsearch, Snowflake, Apache Iceberg, MongoDB)SCHEMA_METADATA(opt-in viaglue_schema_registry.enabled) — Avro / JSON / Protobuf schemas from AWS Glue Schema RegistryDELETION_DETECTIONvia stateful ingestionsts:GetCallerIdentityfor cross-account URN safetydestination_platform_mapwith per-destinationplatform_instance/env/convert_urns_to_lowercaseoverridesTests
Documentation
metadata-ingestion/docs/sources/kinesis/data-platforms.yamlwith official AWS architecture iconskinesis-firehoseentry in the integrations catalog and the docs sidebar (so users searching "Firehose" or "Amazon Data Firehose" find the connector)Test plan
pytest tests/unit/kinesis/— 108 passpytest tests/integration/kinesis/against LocalStack 3.0 — passes with the bundled golden file./gradlew :docs-website:yarnStart) — page renders cleanly, sidebar shows both platformsChecklist
Not supported (see docs Limitations section)
USAGE_STATSvia CloudWatch🤖 Generated with Claude Code