This repo is the official project repository of the paper Sonata: Self-Supervised Learning of Reliable Point Representations and is mainly used for providing pre-trained models, inference code and visualization demo. For reproduce pre-training process of Sonata, please refer to our Pointcept codebase.
[ Pretrain ] [ Sonata ] - [ Homepage ] [ Paper ] [ Bib ]
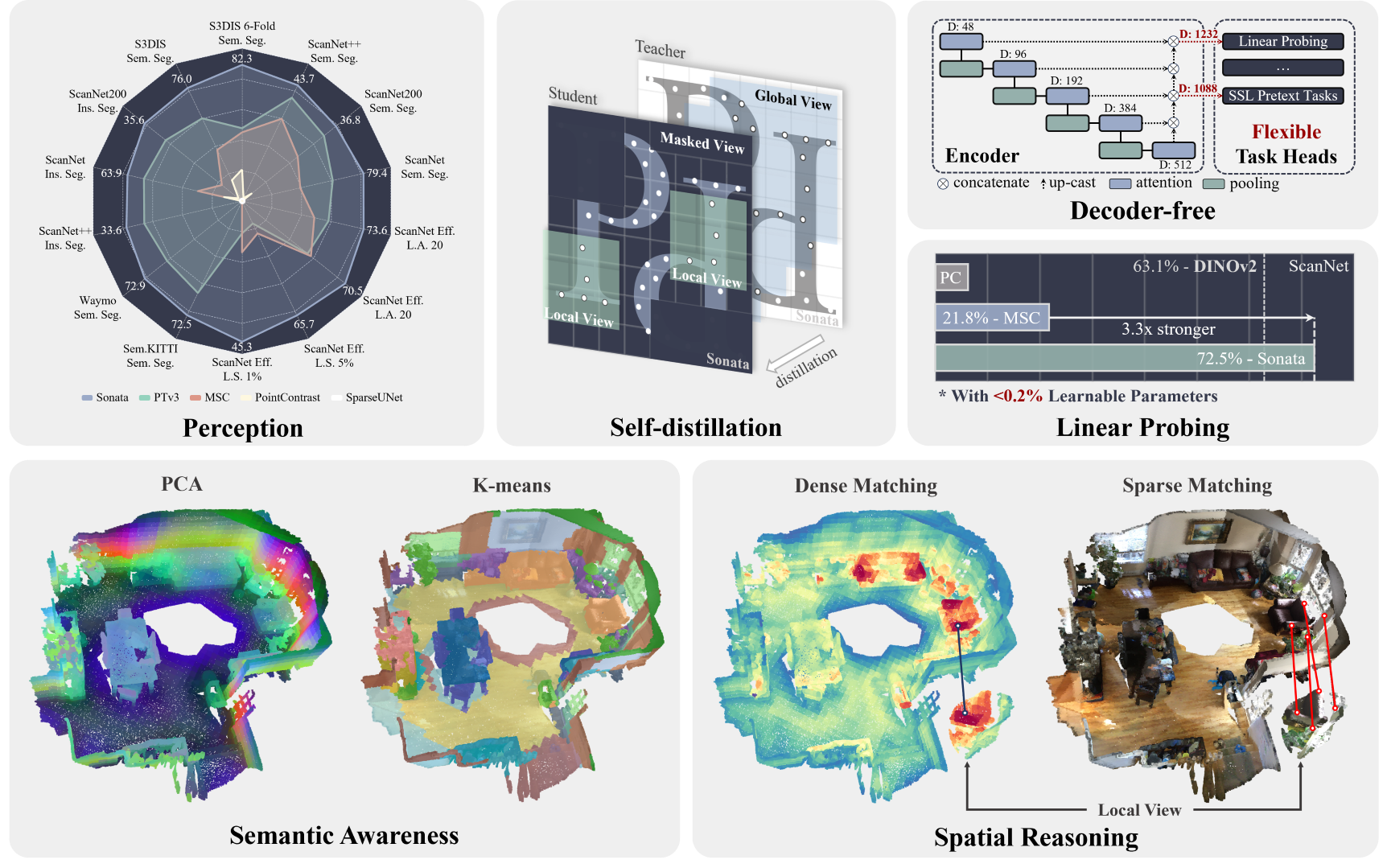
- Mar, 2025 🚀: Sonata is accepted by CVPR 2025! We release the pre-training code along with Pointcept v1.6.0 and provide an easy-to-use inference demo and visualization with our pre-trained model weight in this repo. We highly recommend user begin with is repo for quick start.
This repo provide two ways of installation: standalone mode and package mode.
-
The standalone mode is recommended for users who want to use the code for quick inference and visualization. We provide a most easy way to install the environment by using
condaenvironment file. The whole environment includingcudaandpytorchcan be easily installed by running the following command:# Create and activate conda environment named as 'sonata' # cuda: 12.4, pytorch: 2.5.0 # run `unset CUDA_PATH` if you have installed cuda in your local environment conda env create -f environment.yml --verbose conda activate sonata
We install FlashAttention by default, yet not necessary. If FlashAttention is not available in your local environment, it's okay, check Model section in Quick Start for solution.
-
The package mode is recommended for users who want to inject our model into their own codebase. We provide a
setup.pyfile for installation. You can install the package by running the following command:# Ensure Cuda and Pytorch are already installed in your local environment # CUDA_VERSION: cuda version of local environment (e.g., 124), check by running 'nvcc --version' # TORCH_VERSION: torch version of local environment (e.g., 2.5.0), check by running 'python -c "import torch; print(torch.__version__)"' pip install spconv-cu${CUDA_VERSION} pip install torch-scatter -f https://data.pyg.org/whl/torch-{TORCH_VERSION}+cu${CUDA_VERSION}.html pip install git+https://github.com/Dao-AILab/flash-attention.git pip install huggingface_hub timm # (optional, or directly copy the sonata folder to your project) python setup.py install
Additionally, for running our demo code, the following packages are also required:
pip install open3d fast_pytorch_kmeans psutil numpy==1.26.4 # currently, open3d does not support numpy 2.x
Let's first begin with some simple visualization demo with Sonata, our pre-trained PTv3 model:
- Visualization. We provide the similarity heatmap and PCA visualization demo in the
demofolder. You can run the following command to visualize the result:export PYTHONPATH=./ python demo/0_pca.py python demo/1_similarity.py
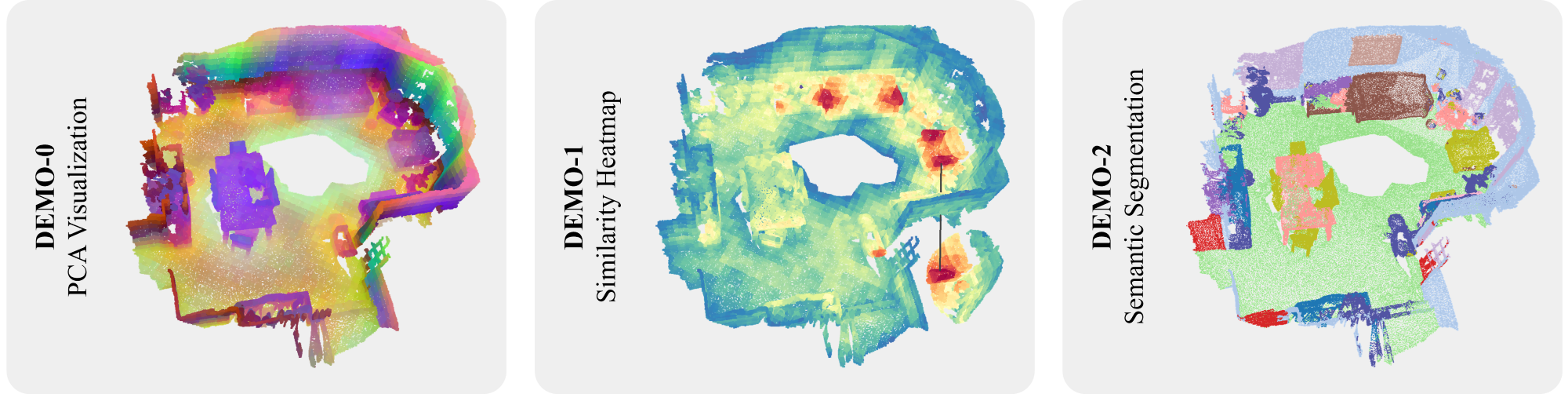
Then, here are the instruction to run inference on custom data with our Sonata:
- Data. Organize your data in a dictionary with the following format:
One example of the data can be loaded by running the following command:
# single point cloud point = { "coord": numpy.array, # (N, 3) "color": numpy.array, # (N, 3) "normal": numpy.array, # (N, 3) "segment": numpy.array, # (N,) optional } # batched point clouds # check the data structure of batched point clouds from here: # https://github.com/Pointcept/Pointcept#offset point = { "coord": numpy.array, # (N, 3) "color": numpy.array, # (N, 3) "normal": numpy.array, # (N, 3) "batch": numpy.array, # (N,) optional "segment": numpy.array, # (N,) optional }
point = sonata.data.load("example1")
- Transform. The data transform pipeline is shared as the one used in Pointcept codebase. You can use the following code to construct the transform pipeline:
The above default inference augmentation pipeline can also be acquired by running the following command:
config = [ dict(type="CenterShift", apply_z=True), dict( type="GridSample", grid_size=0.02, hash_type="fnv", mode="train", return_grid_coord=True, ), dict(type="NormalizeColor"), dict(type="ToTensor"), dict( type="Collect", keys=("coord", "grid_coord", "color"), feat_keys=("coord", "color", "normal"), ), ] transform = sonata.transform.Compose(config)
transform = sonata.transform.default()
- Model. Load the pre-trained model by running the following command:
If FlashAttention is not available, load the pre-trained model with the following code:
# Load the pre-trained model from Huggingface # supported models: "sonata" # ckpt is cached in ~/.cache/sonata/ckpt, and the path can be customized by setting 'download_root' model = sonata.model.load("sonata").cuda() # Load the pre-trained model from local path # assume the ckpt file is stored in the 'ckpt' folder model = sonata.model.load("ckpt/sonata.pth").cuda() # the ckpt file store the config and state_dict of pretrained model
custom_config = dict( enc_patch_size=[1024 for _ in range(5)], enable_flash=False, # reduce patch size if necessary ) model = sonata.load("sonata", custom_config=custom_config).cuda()
- Inference. Run the inference by running the following command:
As Sonata is a pre-trained encoder-only PTv3, the default output of the model is point cloud after hieratical encoding. The encoded point feature can be mapping back to original scale with the following code:
point = transform(point) if isinstance(data[key], torch.Tensor): data[key] = data[key].cuda(non_blocking=True) point = model(point)
Yet during data transformation, we operatefor _ in range(2): assert "pooling_parent" in point.keys() assert "pooling_inverse" in point.keys() parent = point.pop("pooling_parent") inverse = point.pop("pooling_inverse") parent.feat = torch.cat([parent.feat, point.feat[inverse]], dim=-1) point = parent while "pooling_parent" in point.keys(): assert "pooling_inverse" in point.keys() parent = point.pop("pooling_parent") inverse = point.pop("pooling_inverse") parent.feat = point.feat[inverse] point = parent
GridSamplingwhich makes the number of points feed into the network mismatch with the original point cloud. Using the following code to further map the feature back to the original point cloud:feat = point.feat[point.inverse]
If you find Sonata useful to your research, please consider citing our works as an acknowledgment. (੭ˊ꒳ˋ)੭✧
@inproceedings{wu2025sonata,
title={Sonata: Self-Supervised Learning of Reliable Point Representations},
author={Wu, Xiaoyang and DeTone, Daniel and Frost, Duncan and Shen, Tianwei and Xie, Chris and Yang, Nan and Engel, Jakob and Newcombe, Richard and Zhao, Hengshuang and Straub, Julian},
booktitle={CVPR},
year={2025}
}@inproceedings{wu2024ptv3,
title={Point Transformer V3: Simpler, Faster, Stronger},
author={Wu, Xiaoyang and Jiang, Li and Wang, Peng-Shuai and Liu, Zhijian and Liu, Xihui and Qiao, Yu and Ouyang, Wanli and He, Tong and Zhao, Hengshuang},
booktitle={CVPR},
year={2024}
}@inproceedings{wu2024ppt,
title={Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training},
author={Wu, Xiaoyang and Tian, Zhuotao and Wen, Xin and Peng, Bohao and Liu, Xihui and Yu, Kaicheng and Zhao, Hengshuang},
booktitle={CVPR},
year={2024}
}@inproceedings{wu2023masked,
title={Masked Scene Contrast: A Scalable Framework for Unsupervised 3D Representation Learning},
author={Wu, Xiaoyang and Wen, Xin and Liu, Xihui and Zhao, Hengshuang},
journal={CVPR},
year={2023}
}@inproceedings{wu2022ptv2,
title={Point transformer V2: Grouped Vector Attention and Partition-based Pooling},
author={Wu, Xiaoyang and Lao, Yixing and Jiang, Li and Liu, Xihui and Zhao, Hengshuang},
booktitle={NeurIPS},
year={2022}
}@misc{pointcept2023,
title={Pointcept: A Codebase for Point Cloud Perception Research},
author={Pointcept Contributors},
howpublished={\url{https://github.com/Pointcept/Pointcept}},
year={2023}
}We welcome contributions! Go to CONTRIBUTING and our CODE OF CONDUCT for how to get started.
- Sonata code is released by Meta under the Apache 2.0 license;
- Sonata weight is released under the CC-BY-NC 4.0 license (restricted by NC of datasets like HM3D, ArkitScenes).