
The Context Operating System for AI Agents. Less noise. More signal. Cut token consumption by up to 90%.
🇺🇸 English | 🇯🇵 日本語 | 🇨🇳 简体中文 | 🇸🇦 العربية | 🇮🇩 Bahasa Indonesia | 🇻🇳 Tiếng Việt | 🇰🇷 한국어
![]()



OMNI is a high-performance Semantic Signal Engine and Context Operating System that intelligently intercepts, analyzes, and distills terminal outputs before they reach your AI Agent. It acts as a transparent signal optimization layer that sits between the shell and the AI, ensuring every token sent to the model is high-value, relevant, and noise-free. By preventing your AI from getting confused by noisy output, you get accurate answers faster while saving massive amounts of token costs.
Fully transparent. You're always in control.
- The Problem: Expensive Tokens & Noisy Outputs
- The Solution: Omni
- The Philosophy
- Real-World Use Cases
- Performance & Benchmarks
- Features Explained
- Under the Hood: How Omni Works
- Architecture
- Quick Start & Installation
- How to Use It
- Works Even Better with Heimsense
- Contributing & License
When you use autonomous AI agents (like Claude Code or Cursor) in your terminal, they read everything. A simple git diff, npm install, or cargo test command can easily dump 10,000 to 25,000 tokens of useless terminal noise into your AI's context.
This causes three huge problems:
- It's extremely expensive: You pay real money for every single token of that junk output.
- It makes the AI "dumb": Critical errors get buried under megabytes of warning logs and loading bars, confusing the AI and diluting its reasoning.
- Model Lock-in: Advanced agent frameworks force you to use their most expensive flagship models just to have a context window big enough to handle all that noise.
- Token-Aware Execution: Agents lack awareness of token costs and outputs, leading to unnecessary consumption.
- Context Bloat: The volume of terminal output clutters the AI's context, reducing focus and accuracy.
I built Omni because I wanted to run AI agents efficiently and cheaply every single day in my own workflow.
Omni acts as the perfect filter between your terminal and your AI.
The result? You can run your AI agent on a super-advanced framework and feed it zero noise. Because the AI is only fed highly focused, straight-to-the-point context, even affordable or ordinary models will perform on-par with expensive flagship models, since they are never distracted by junk data.
My ultimate passion isn't to monetize this—it's to build the ultimate open-source toolbelt for the Agentic AI era. By aggressively saving token costs, I can develop software robustly and cost-effectively today, and you can too.
Context is expensive and noisy, and Omni is here to fix that. By optimizing context, Omni makes AI agents more efficient, cost-effective, and easier to use. This is done by reducing the amount of context that is sent to the AI agent, which in turn reduces the amount of processing time and memory required to generate a response.
OMNI wasn't built just to "cut context" or "save tokens"—those are simply the happy side effects. The true philosophy behind OMNI is Context Quality.
AI agents like Claude are only as smart as the context you feed them. When you flood them with megabytes of dependency logs or loading bars, you force them to sift through garbage to find the actual problem. This dilutes their reasoning and leads to degraded or unhelpful responses.
OMNI's goal is to feed your AI pure, highly-dense signal. This means only grabbing the context that is actually important and meaningful for Claude. We clean up the noise the AI doesn't need, which means:
- Automatically, the tokens you use are drastically fewer.
- The AI's response is of significantly higher quality because its context window is laser-focused on the real problem.
Try it for a week. Feel the difference in the quality and speed of your AI's reasoning when it's fed on a diet of pure signal instead of raw terminal noise.
OMNI is designed to solve the daily frustrations of Agentic AI developers. Here is how it transforms your workflow:
-
The "Infinite Loop of Death" in Monorepos
- Scenario: You ask Claude to run
npm installandnpm run buildin a large monorepo. It outputs 20,000 lines of dependency warnings and a small build error at the end. The AI gets distracted by the warnings and tries to fix unrelated dependency issues, burning through your tokens and trapping you in an infinite loop. - OMNI's Fix: OMNI intercepts the build. It completely mutes the hundreds of
peer dependencywarnings and only surfaces the exactBuild Error: Cannot find module 'X'alongside the stack trace. The AI sees a 50-token output and fixes the code instantly.
- Scenario: You ask Claude to run
-
The "Silent Hallucination" on Large Files
- Scenario: The AI wants to understand a project and runs
cat src/utils.ts. The file is 3,000 lines long. The AI struggles to keep all of it in working memory and starts hallucinating function signatures. - OMNI's Fix: OMNI blocks the raw
catand replaces it with a Structured Outline. It shows the AI the imports, the public API (function names and types), and risk markers, reducing the output by 80%. OMNI then warns the AI:"This file has 12 dependents — use omni_context for full impact map."The AI is guided to make safer, factual edits.
- Scenario: The AI wants to understand a project and runs
-
Multi-Agent Collaboration
- Scenario: You are using Cursor IDE for quick edits and Claude Code CLI for heavy lifting. They both need to know what's happening without running redundant commands and wasting tokens.
- OMNI's Fix: OMNI acts as a shared memory layer. Using
omni_agentsand its local SQLiteStore, Cursor and Claude share the same filtered memory streams, active errors, and execution environments. They collaborate without clashing.
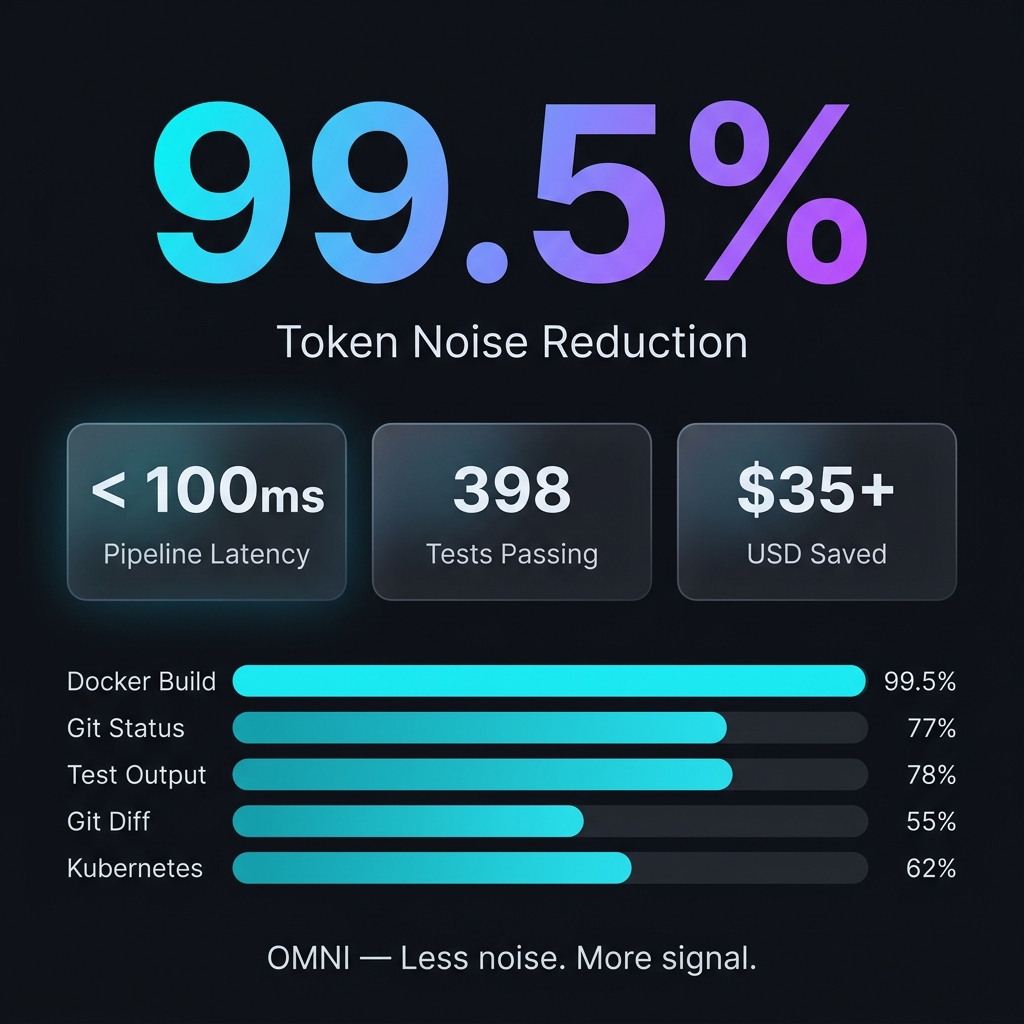
OMNI is built in Rust for zero-overhead execution and ruthless efficiency. Here are the actual benchmarks measured on the release binary:
| Command / Context | Input Size | Output Size | Token Savings | Impact on AI |
|---|---|---|---|---|
docker build (multi-stage) |
9.2 KB | 49 bytes | 99.5% | Eliminates caching noise; AI instantly sees the real build error. |
cargo test (large suite) |
16.5 KB | 4.3 KB | 78.0% | Strips hundreds of "ok" tests; AI focuses only on the failures and stack traces. |
git status (dirty) |
496 bytes | 113 bytes | 77.2% | Removes clean files and hints; keeps only modified/untracked files. |
kubectl get pods |
840 bytes | 762 bytes | 10.0% | Selectively surfaces CrashLoopBackOff/Error pods, skipping healthy ones. |
git diff (multi-file) |
397 bytes | 220 bytes | 50.0% | Preserves hunks with changes, dropping excessive context lines. |
- Pipeline Latency: < 100ms (end-to-end, including binary startup)
- All-Time Savings: 97.3% token reduction across average development sessions.
- ROI: $35+ USD saved per developer/month (measured against flagship models).
To see your own actual token savings, just run omni stats after a few days of usage.
- No More AI Confusion: Omni acts like a smart sieve. If a test fails, it shows the AI only the specific error line and stack trace, blocking noisy dependency logs and loading spinners.
- 90% Token Reduction: By eliminating useless terminal noise, you drastically cut your agentic API bills instantly.
- Adaptive Compression: OMNI tracks when agents retrieve omitted output. If a command family is frequently retrieved, OMNI automatically softens compression next time — self-tuning without configuration.
- Smart High-Speed Bypass: To ensure zero latency for small tasks, OMNI automatically bypasses distillation for outputs under a 2000-token threshold.
- Zero Information Loss: Worried Omni filtered something important? Don't be. Omni saves the raw output locally (
RewindStore). The AI can automatically request it usingomni_retrieve. - Factual Anti-Hallucination Guards: OMNI emits warnings only when it has hard facts. If output is heavily compressed or a file has massive dependencies, OMNI injects a system warning to keep your AI grounded in reality.
- Omission Visibility: OMNI explicitly labels removed content (e.g.,
[OMNI: omitted X lines of noise]) in the output, giving your AI agent perfect situational awareness.
- Native MCP Server (
omni mcp): OMNI operates as a high-performance Native Model Context Protocol (MCP) server. Agents can instantly query OMNI for active errors, historical engrams, token budgets, and contextual file insights via a directstdioconnection without any subprocess latency. - Multi-Agent Collaboration: Fully aware of its environment via
OMNI_AGENT_ID. If you have Cursor running alongside Claude CLI or Hermes, they seamlessly share the same filtered memory streams and active errors without clashing. - Session Intelligence: OMNI remembers what you are doing. It knows which files you are actively editing and stops feeding the AI redundant context. Fixes are preserved permanently via
omni_knowledge. - Structured ReadFile + Grep: Instead of raw file dumps, OMNI returns structured outlines (imports, public API) and grouped grep summaries (priority lines first).
- Lightweight Dependency Graph: OMNI builds a fast local file relationship graph at hook time (no daemon). If your AI reads a heavily-imported file, OMNI warns it of the impact map.
- Proactive Context Pressure: OMNI actively acts as a "Token Traffic Light." Via the
omni_insightMCP tool, OMNI pro-actively warns the agent when its context window hits "Warning" or "Critical" thresholds, triggering the agent to compress its memory before it crashes or hallucinates. - Engrams (Automatic Subtask Digests): OMNI automatically detects when a subtask is completed (e.g., resolving a compiler error, committing code, or fixing a broken test). It creates a highly compressed snapshot (an "Engram") without wasting tokens on LLM calls, so your agent never suffers from "context amnesia" during long sessions.
- Smart Context Compaction: When your context window gets full, OMNI doesn't blindly trim tokens. It uses a priority-aware algorithm to pack the most important data first (Pinned Files > Active Errors > Engrams > Tool Activity > Hot Files), saving massive overhead.
- Session Handoffs: Switching from Claude Code to Cursor or Hermes? Use the
omni_handofftool to instantly export the current session's memory (hot files, recent commands, active errors) into a portable summary that your new agent can instantly absorb.
- Session Health Dashboard: Run
omni session --healthfor a beautiful visual dashboard of your context pressure, active engrams, rolling tool activity, and token savings. - Distill Monitor: Track token savings over time. Use
omni_budgetandomni_historyright inside your LLM, or runomni statslocally to visualize money saved. - Visual Impact (
omni diff): Runomni diffto see the bulky raw output compared side-by-side to Omni's sleek, filtered version. - Debug Passthrough: Need the raw output? Set
OMNI_PASSTHROUGH=1to completely bypass the engine and see every character of the original output.
OMNI is more than just a regex script; it's a high-performance Semantic Signal Engine written in Rust. But how does it actually cut 90% of token consumption in under 100ms?
Here is the story of what happens inside the OMNI codebase when your AI Agent types a command like cargo test:
- The Interception (
src/hooks&src/main.rs): The moment the AI hits "Enter", OMNI intercepts the execution.main.rsdynamically detects the context (whether it's a pipe, a hook, or an MCP call). Thehooksmodule seamlessly wraps the command, allowing OMNI to capture the raw terminal output as a high-speed data stream without slowing down the actual execution. - The Streaming Pipeline (
src/pipeline): Instead of waiting for the command to finish and dumping megabytes of text into memory, OMNI processes the output line-by-line using a memory-efficient streaming pipeline. This ensures that even if a command spits out 10,000 lines of logs, OMNI's memory footprint remains nearly flat. - The Semantic Brain (
src/distillers&src/guard): As the text streams in, it passes through the Distillers. Powered by declarative TOML rules (signals/), the distillers analyze the semantic meaning of the output.- Is this a loading spinner? Drop it.
- Is this a list of 500 passing tests? Drop it.
- Is this a panic stack trace? Keep it.
Meanwhile, the
guardmodule ensures facts are preserved, guaranteeing that OMNI never silently alters critical diagnostic information.
- The Safety Net (
src/store): What if the AI actually needed to see the 500 passing tests? OMNI follows a strict "Zero Information Loss" policy. Before any noise is discarded, the raw, unedited output is safely tucked away in a local, lightning-fast SQLite database (Store). OMNI leaves a small breadcrumb in the AI's context:[OMNI: omitted 1,200 lines of noise. Use omni_retrieve to view]. - The Multi-Agent Interface (
src/mcp&src/session): Finally, the distilled, high-signal output is returned to the AI. Behind the scenes, thesessionmanager tracks the current token budget, while themcp(Model Context Protocol) server stands ready. If the AI wants to query historical errors, fetch the omitted raw logs, or check the dependency graph (src/graph), the MCP tools provide instant, structured access.
The Result: A bloated 25,000 token terminal dump becomes a concise 400 token error report. The AI understands the problem instantly, and you save real money.

Omni is incredibly easy to set up. It natively integrates into your terminal.
macOS / Linux:
# 1. Install via Homebrew
brew install fajarhide/tap/omni
# 2. Setup Omni (Interactive Menu for Claude, VS Code, OpenCode, Codex, Antigravity)
omni init
# 3. Verify it's working
omni doctor
# 4. Or auto-fix any issues
omni doctor --fix
# 5. Check Current Status
omni init --statusUniversal Installer (macOS / Linux / WSL):
curl -fsSL omni.weekndlabs.com/install | bashWindows (PowerShell):
irm omni.weekndlabs.com/install.ps1 | iexOnce installed via omni init, OMNI works invisibly in the background. Whether your AI Agent runs a terminal command via MCP or you manually pipe output (ls | omni), OMNI automatically jumps in as a transparent layer. It intelligently filters terminal output, removes the noisy logs, and hands the clean signal back to the AI.
For detailed breakdown by savings, command, period, and route:
omni statsTo diagnose your OMNI installation (hooks, MCP, filters, database):
omni doctorNeed to see the filters in action or add your own custom rules?
You can easily create your own rules using simple TOML files in ~/.omni/signals/.
By default, omni init --claude automatically hooks into Claude Code. However, OMNI works perfectly with any agentic AI through its built-in integrations! Run omni init to see the interactive menu.
- VS Code & Continue.dev: Use our MCP context provider (
integrations/continue-dev/). - OpenCode & Codex CLI: Built-in wrappers automatically pipe command output to OMNI.
- Antigravity IDE: OMNI registers as a native MCP server in Antigravity's config (
~/.gemini/antigravity/mcp_config.json). Runomni init --antigravityto set up automatically. - Pi Agent: Native OMNI package for Pi. Run
omni init --pito install the OMNI Pi package via Pi's package installer. Use Pi's slash commands to toggle the extension on or off.
Multi-Agent Tuning (~/.omni/config.toml)
Different agents have different pain points. Keep VS Code chat clean, whilst letting OpenCode read more data. Tune them individually:
[global]
aggressiveness = "balanced"
[agents.vscode_continue]
aggressiveness = "aggressive"
enable_readfile_distillation = true
[agents.opencode]
aggressiveness = "conservative"
enable_readfile_distillation = falseFor Users:
- The Ultimate Guide (HOW_TO_USE.md) — Everything you need: Installation,
omni learn, Custom TOML Filters, and CLI Commands. - OpenClaw Integration — Official OpenClaw plugin for native OMNI distillation. Install:
openclaw plugins install clawhub:@fajarhide/omni-signal-engine - Hermes Agent Integration — Community Hermes Agent plugin for native OMNI distillation. Install:
uv pip install --python ~/.hermes/hermes-agent/venv/bin/python git+https://github.com/wysie/hermes-omni-plugin.git
For Developers & System Integrators:
- Development Guide — How to build and contribute to the OMNI codebase.
- Testing Architecture — Quality assurance and context safety.
- Session Continuity — Deep dive into OMNI's working memory.
- Roadmap — Current development status and upcoming features.
- Migration Guide — Notes on upgrading from Node/Zig to the Rust version.
Omni is part of my personal AI toolbelt. If you use claude-code, I highly recommend pairing Omni with my other project: Heimsense.
Heimsense unlocks restricted environments like claude-code to run with any free or OpenAI-compatible model, rather than forcing you to use expensive Anthropic ones.
Omni + Heimsense = Run world-class agent frameworks using affordable models with zero noise and pinpoint accuracy.
This is a passion project built for the era of Agentic AI. Whether you're here to save money on tokens, test out free models, or help build the ultimate agentic toolbelt, contributions are always welcome!
- Development: Want to build from source? Run
make ciandcargo build. Read our CONTRIBUTING.md for details. - License: MIT License
Build with ❤️ by Fajar Hidayat