![]()
Quickly find the smollest viable language model for your task, for faster and cheaper intelligence
The basic idea is to run your OpenAI/Anthropic API queries to other, smaller models on Hugging Face API (or local), allowing you to quickly find the smollest/cheapest/fastest model that would work for your use case.
pip install smollest[openai] # for OpenAI
pip install smollest[anthropic] # for Anthropic
pip install smollest[all] # bothInstall openai from smollest and then write your code as normal!
from smollest import openai
client = openai.OpenAI(
api_key="sk-...",
project="my-classifier", # organizes results by project
)
# By default, replays to 3 models of different sizes on HF Inference API
result = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Classify as positive/negative: I love this!"}],
)Override candidates per-client or per-call:
# Per-client
client = openai.OpenAI(
candidates=["mistralai/Mistral-7B-Instruct-v0.3", "http://localhost:1234/v1"],
)
# Per-call
result = client.chat.completions.create(
model="gpt-4o",
messages=[...],
candidates=["microsoft/Phi-3.5-mini-instruct"],
)Works the same way with Anthropic:
from smollest import anthropic
client = anthropic.Anthropic(project="my-classifier")
result = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": "Classify: I love this!"}],
)- Your API call goes to the baseline model as normal
- The same prompt is replayed to each candidate (HuggingFace serverless or local OpenAI-compatible server)
- Structured outputs (JSON) are compared field-by-field via exact match
- Results are printed to console and logged to
~/.smollest/
Remote candidates run in parallel; local candidates run sequentially.
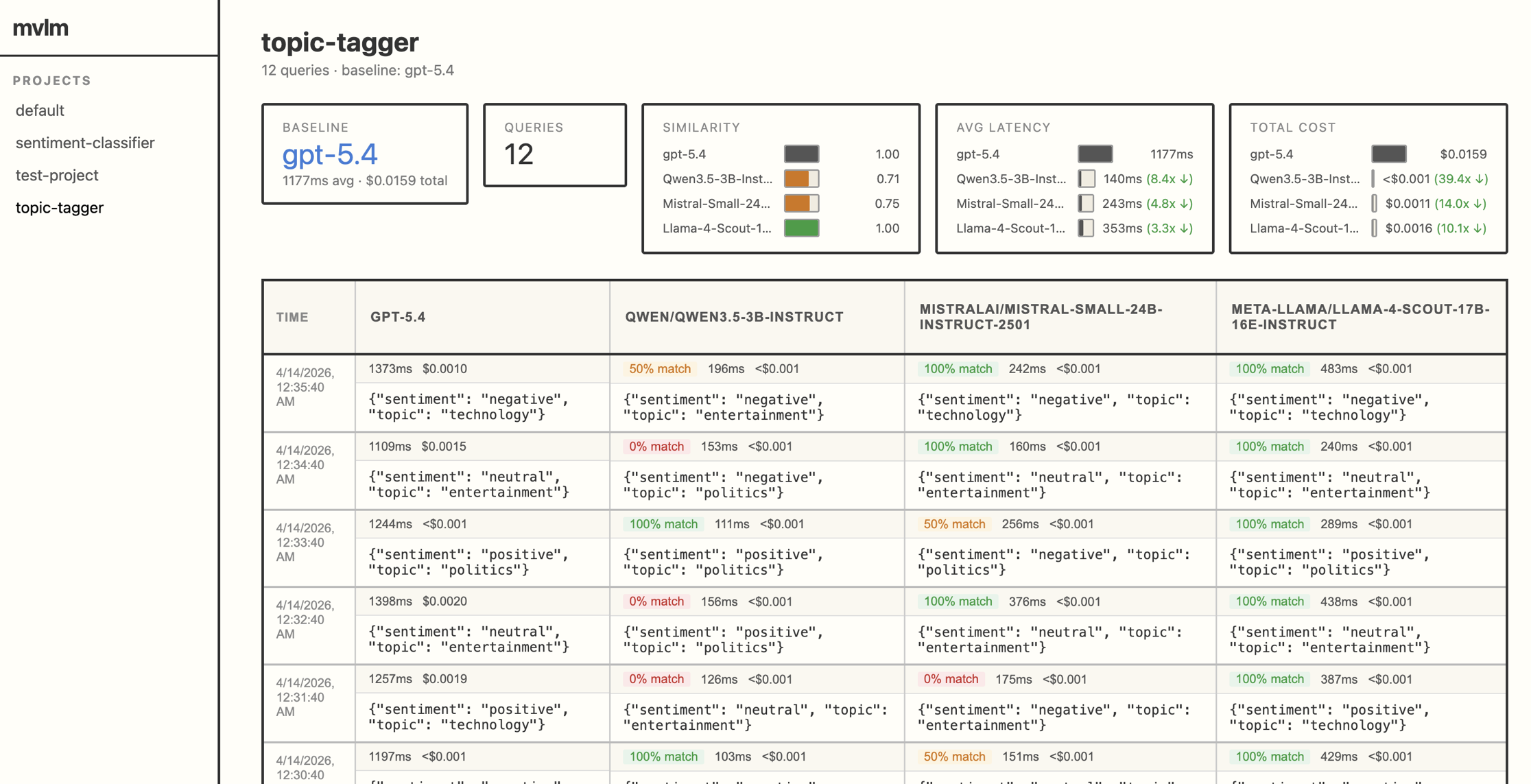
smollest showOpens a web dashboard with projects in the sidebar, a results table with truncation for long outputs, latency and cost per model, and aggregate match rates. The image above shows the UI, which you can reproduce by cloning this repo and running: python examples/demo_dashboard.py
- Allow adding additional models directly through the UI
- Add LLM as judge to score outputs that are not structured
- Let developers eaisly fine tune models on outputs
MIT