项目架构:
vae压缩至潜空间,unet预测噪声,ddpm思路处理前向加噪和生成去噪。
复现代码仓:hengzhl/diffusion-ddpm-tolearn
简单介绍:
基于原项目,修正了无法在gpu上运行的bug,增加了gen.py用于测试模型生成能力。
修改了原项目的config的cfg.py和data的loader.py,在data中新增loader_pc.py。
训练过程:
将python -m src.train修改如下,在服务器离线训练,
nohup python -m src.train > train.log 2>&1 &查看训练进度,在同一个目录下输入,
tail -f train.log由于UNIC服务器所分空间只有17GB,在79-epoch和139-epoch两次训练中断;原计划训练150轮,采用恢复训练的方式姑且先训练到139-epoch。
Epoch 79: 100%|██████████| 91/91 [00:58<00:00, 1.62it/s, loss=0.0222, lr=4.48e-5, step=7279]
......
Epoch 139: 100%|██████████| 91/91 [03:01<00:00, 2.00s/it, loss=0.0196, lr=1.09e-6, step=12739]
可以根据tensorboard保存的logs查看训练过程loss、lr、sample图的过程,
tensorboard --logdir=models/logs
训练过程的Loss变化图(光滑处理)如下,
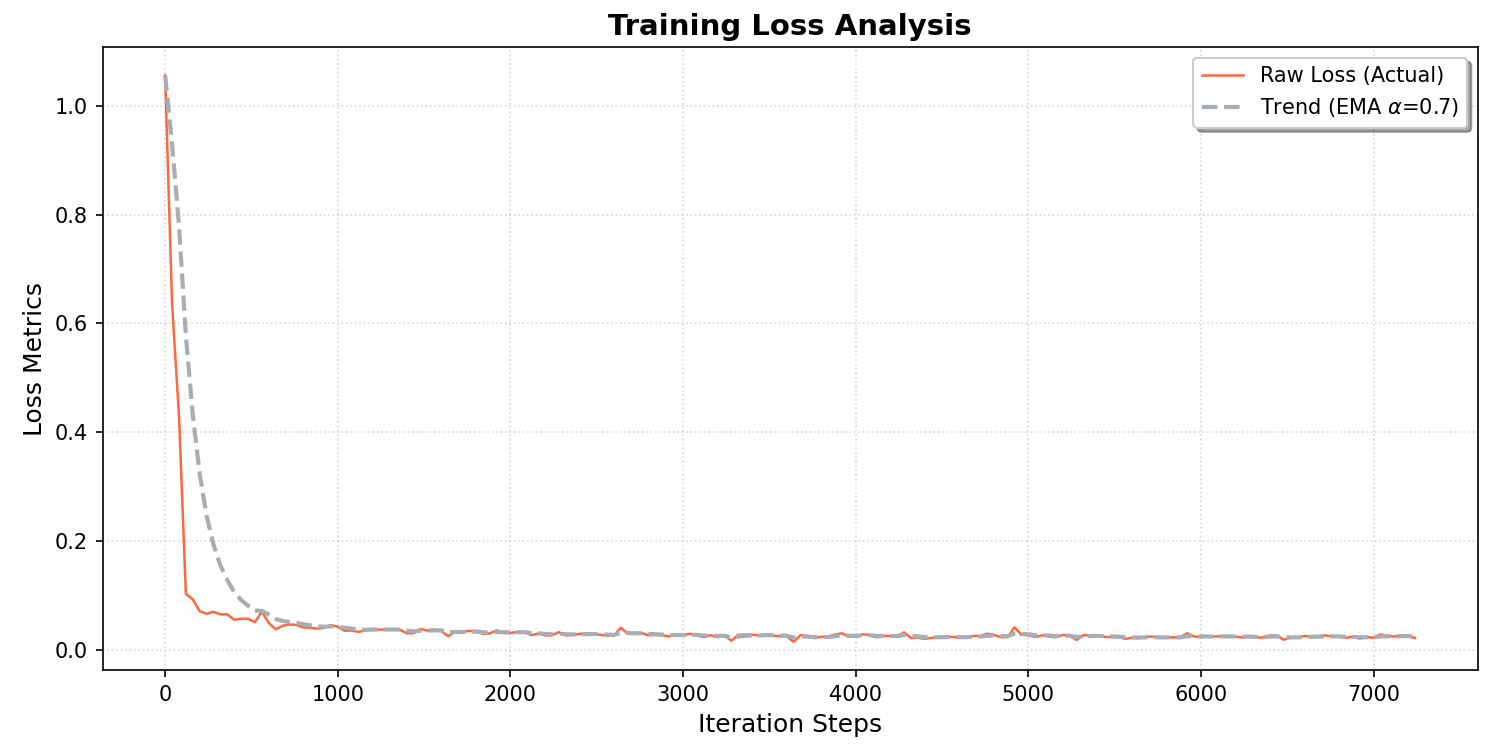
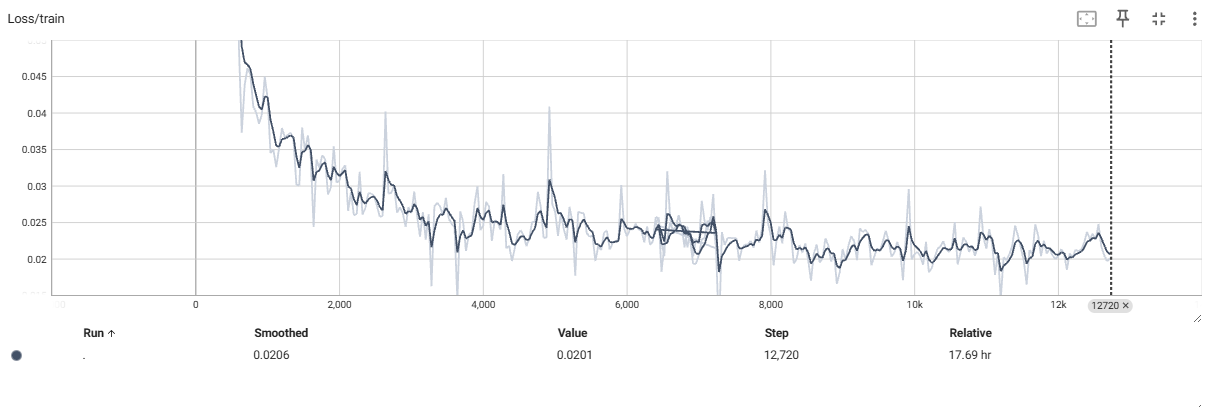
具体的loss震荡变化如下,大致收敛在0.02左右。
第139轮DDPM模型采样生成的图如下,

原项目作者在100轮和300轮训练的生成图如下,
.jpeg)
.jpeg)
alkzar90/croupier-mtg-dataset数据集中与其类似的图有,

虽然原数据集和项目生成图也不是很清晰,但是生成效果图更不清晰,在训练框架和DDPM过程一致的情况下,大概率是因为训练不理想导致的。
使用129轮的模型进行生成能力测试(139轮模型破损),得到GIF动图如下,
第一次,尝试用CPU训练,尝试如下,
(PytorchCPU) PS D:\AI_Project\fork-diffusion_ddpm_tolearn> python -m src.train
Resolving data files: 100%|█████████████████████████████████████████████████████| 1451/1451 [00:00<00:00, 43706.35it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████| 170/170 [00:00<00:00, 42508.15it/s]
Resolving data files: 100%|█████████████████████████████████████████████████████| 174/174 [00:00<00:00, 43291.55it/s]
Model size: 58661123
Epoch 0: 1%|▉ | 2/242 [00:23<46:10, 11.54s/it, loss=1.07, lr=2e-5, step=1]第二次,尝试在colab上训练,结果出现RuntimeError,本质原因是原作者在ddpm.py和layers.py中形如
alpha_hat = self.alphas_hat[timesteps].to(images.device)的代码,由于先执行索引,但是self.alphas_hat由torch函数产生,默认存储在CPU,而timesteps由cfg配置决定,存储在训练用的GPU中,产生冲突。
解决方法:在多个文件中查找to(,发现类型的代码就修改为alpha_hat = self.alphas_hat.to(images.device)[timesteps]即可。该问题已提交Issue(RuntimeError· Issue #5 ·)
增添了tensorboard用于分析训练过程。
colab命令:
!git clone https://github.com/hengzhl/diffusion-ddpm-tolearn.git
%cd diffusion-ddpm-tolearn
!python -m src.train
辅助colab命令:
%cd ..
!rm -rf ./diffusion-ddpm-tolearn
!pwd
colab训练过程:
Resolving data files: 100% 1451/1451 [00:00<00:00, 6678.04it/s]
Resolving data files: 100% 170/170 [00:00<00:00, 27544.01it/s]
Resolving data files: 100% 174/174 [00:00<00:00, 27126.41it/s]
Model size: 58661123
Epoch 0: 100% 182/182 [04:03<00:00, 1.24s/it, loss=0.27, lr=0.0001, step=181]
Epoch 1: 100% 182/182 [04:15<00:00, 1.40s/it, loss=0.0796, lr=0.0001, step=363]
Epoch 2: 32% 59/182 [01:23<02:54, 1.42s/it, loss=0.0638, lr=9.99e-5, step=422]