GeCo I2b2 data source: implementation of steps 1 and 2 #6
Conversation
 f-marino
left a comment
f-marino
left a comment
There was a problem hiding this comment.
The core of what we agreed on has been implemented.
@mickmis I left just a few comments to address in the code. In addition to those, I think adding a (even small) description to the packages would be useful.
Next steps to have a fully working plugin:
- Implement search box and survival curves operations
- Factor out all GeCo dependencies
- Define how plugins are loaded in GeCo
| @@ -0,0 +1,3 @@ | |||
| [submodule "third_party/geco"] | |||
| path = third_party/geco | |||
| url = [email protected]:ldsec/geco.git | |||
There was a problem hiding this comment.
to be deleted by extracting to a public repo the geco parts used by this plugin (i.e., as far as I understand, the dev deployment)
| @@ -0,0 +1,35 @@ | |||
| -- pl/pgsql function that returns (maximum lim) ontology elements whose paths contain the given search_string. | |||
|
|
|||
| CREATE OR REPLACE FUNCTION i2b2metadata.get_ontology_elements(search_string varchar, lim integer DEFAULT 10) | |||
There was a problem hiding this comment.
Indeed, actually none of the functions in 50-stored-procedures are used or up to date at the moment. I've included them though in anticipation to the next implementations, but it is likely that it will be needed for them to be modified.
I can remove for clarity if you prefer, or leave them here, maybe with a readme saying what I just wrote.
There was a problem hiding this comment.
Fine, don't touch them, I'll take care of it.
|
|
||
| const ddlLoaded = `SELECT EXISTS (SELECT 1 FROM pg_namespace WHERE nspname = $1);` | ||
|
|
||
| const createDeleteSchemaFunctions = ` |
There was a problem hiding this comment.
I guess you want to create a schema every time you create a datasource to support the test case where multiple datasources' info are stored on the same DB. If this is the case, why aren't you creating the explore query and saved cohorts table in the correspondent schema. And if it is not the case, why you are doing it?
There was a problem hiding this comment.
The intention was more to move the database structure creation logic into the code, rather than rely on the deployment to do so. I find this simplifies the deployment since:
- in test deployment we have less control over the database since its deployment is done through geco
- in production deployment the plugin is loaded by geco and not as an independent runtime, and I wanted to avoid the need of having to run devops stuff from geco
And yes one of the other objective was to support multiple data sources of the same type.
why aren't you creating the explore query and saved cohorts table in the correspondent schema
It is, through a separate statement ddlStatement.
There was a problem hiding this comment.
Probably it's because of my not great proficiency in sql, but in the ddlstatement I don't see specified the schema in which the two tables are created. Aren't the table created in the default schema (i.e., public) in this case?
There was a problem hiding this comment.
So for this, the connection string passed to the postgresql driver contains the schema (here), i.e. if the schema is not specified in the SQL query, it will default to the one passed to the driver. In this case, the name of the schema is configurable.
| go-build-plugin: | ||
| go build -buildmode=plugin -v -o ./build/ ./cmd/... |
There was a problem hiding this comment.
| go-build-plugin: | |
| go build -buildmode=plugin -v -o ./build/ ./cmd/... | |
| go-build-plugin: export GOOS=linux | |
| go-build-plugin: | |
| go build -buildmode=plugin -v -o ./build/ ./cmd/... |
I guess here we should always cross compile
There was a problem hiding this comment.
I would say it depends on what is done on the geco side, as the produced binary for the plugin should be compatible with the geco binary.
There was a problem hiding this comment.
Nevermind, actually I had to work a lot to make it work with the dockerized geco, I'll take care of it
Co-authored-by: Francesco Marino <[email protected]>
Co-authored-by: Francesco Marino <[email protected]>
|
@f-marino @romainbou FYI I have about 1 hour left to spend. I don't know how you would like me to spend it, for additional fixes, a meeting for a debrief/walk-through the code, or anything else. |
|
There is only one last comment to address. |
|
@mickmis everything went smoothly enough with the integration, so I didn't need your help. Last thing you can do for the remaining hour is add some comments/documentation about the i2b2 image (everything under /build/i2b2), like a small comment for the most relevant files describing what they do, with the most important parameters to take into account in case we want to modify something, if any. In particular I noticed that in the i2b2 logs there is not anymore the dump of the xml requests addressed to i2b2, could you tell us which parameter we have to tweak to have them back? |
Great news!
OK this should be done now, I've added several READMEs which should contain all the information needed.
If you mean the dump by i2b2 itself it should be controlled the environment variable of the i2b2 docker image If you mean the dump by the data source (which I recommend), it is logged at the debug level. |
|
In MedCo in the logs we were able to see the xml requests when browsing the ontologies or performing queries (like the one in the picture), it is not the case here. |
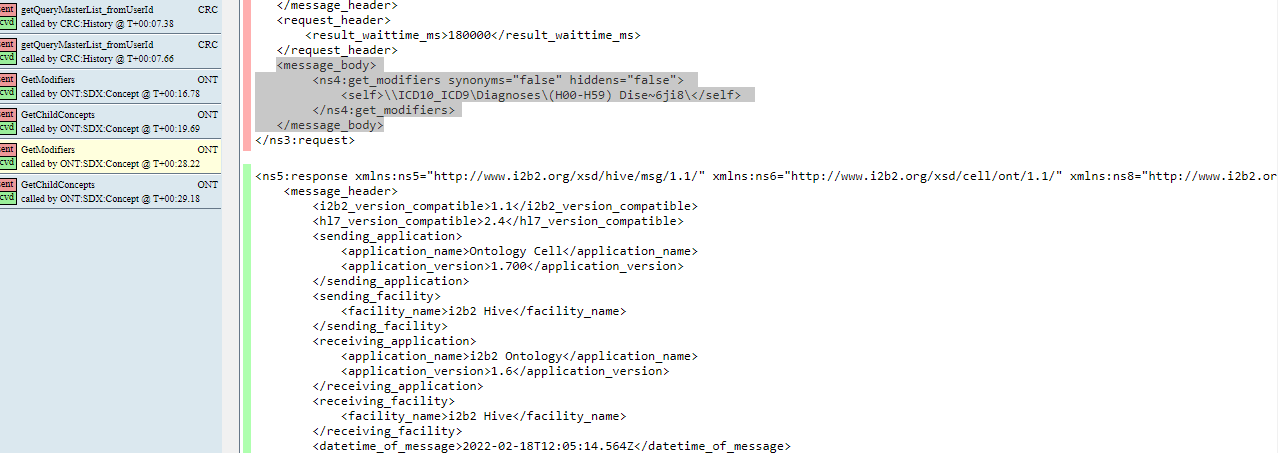
Yes however it is pretty unreadable, so I suggest to log it at the datasource level, c.f. my previous response. |
Here is a working implementation of the i2b2-medco data source plugin for GeCo.
Summary:
internal: test of the plugin through GeCo's data manager