Locality Sensitive Hashing (LSH) is a technique used for approximate nearest neighbor search, especially effective in high-dimensional spaces. This project implements LSH specifically tailored for text data, particularly useful for tasks like document similarity, plagiarism detection, and recommendation systems.
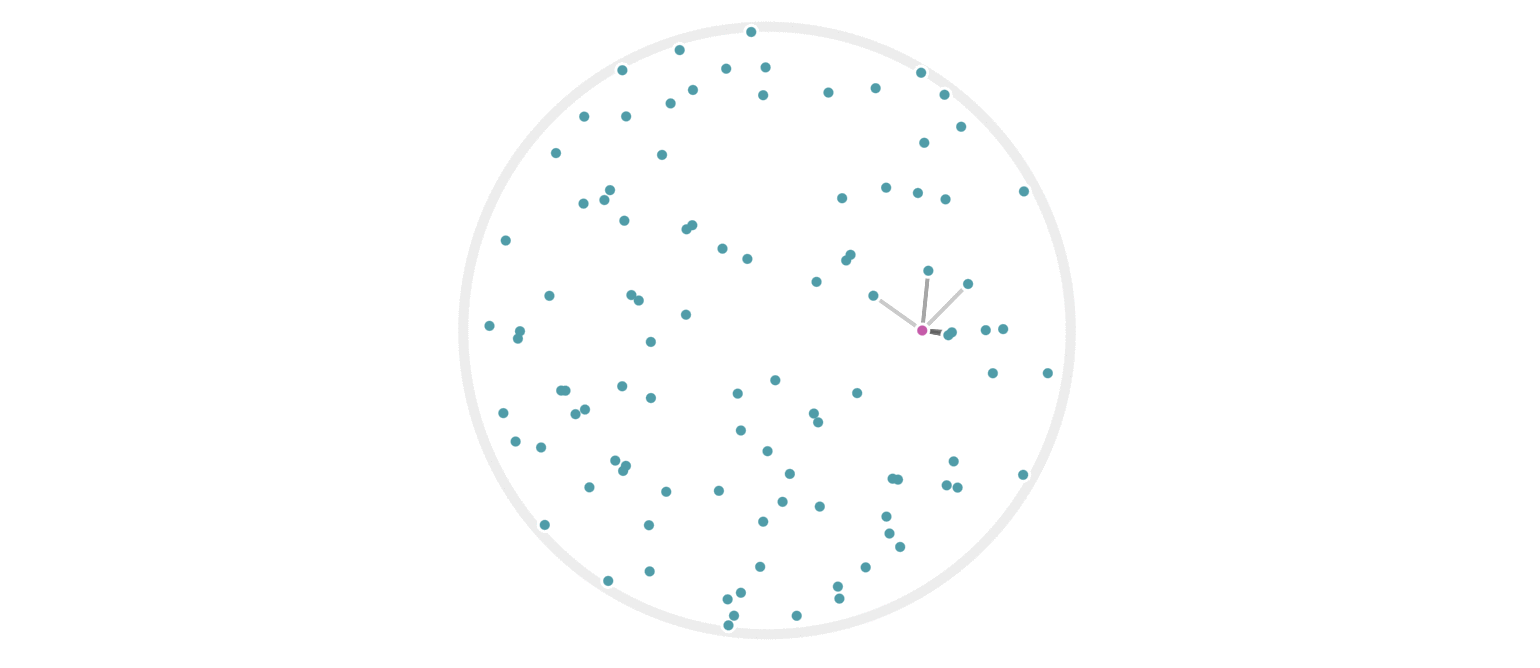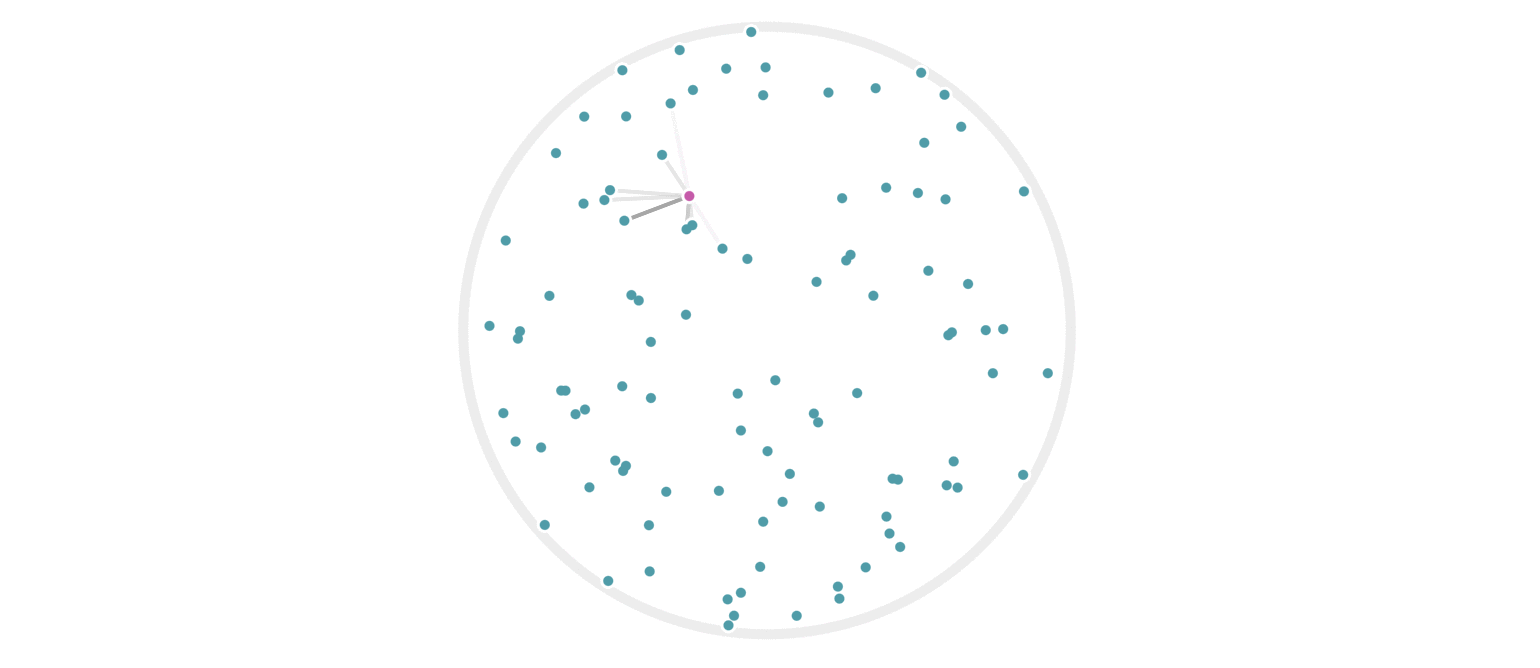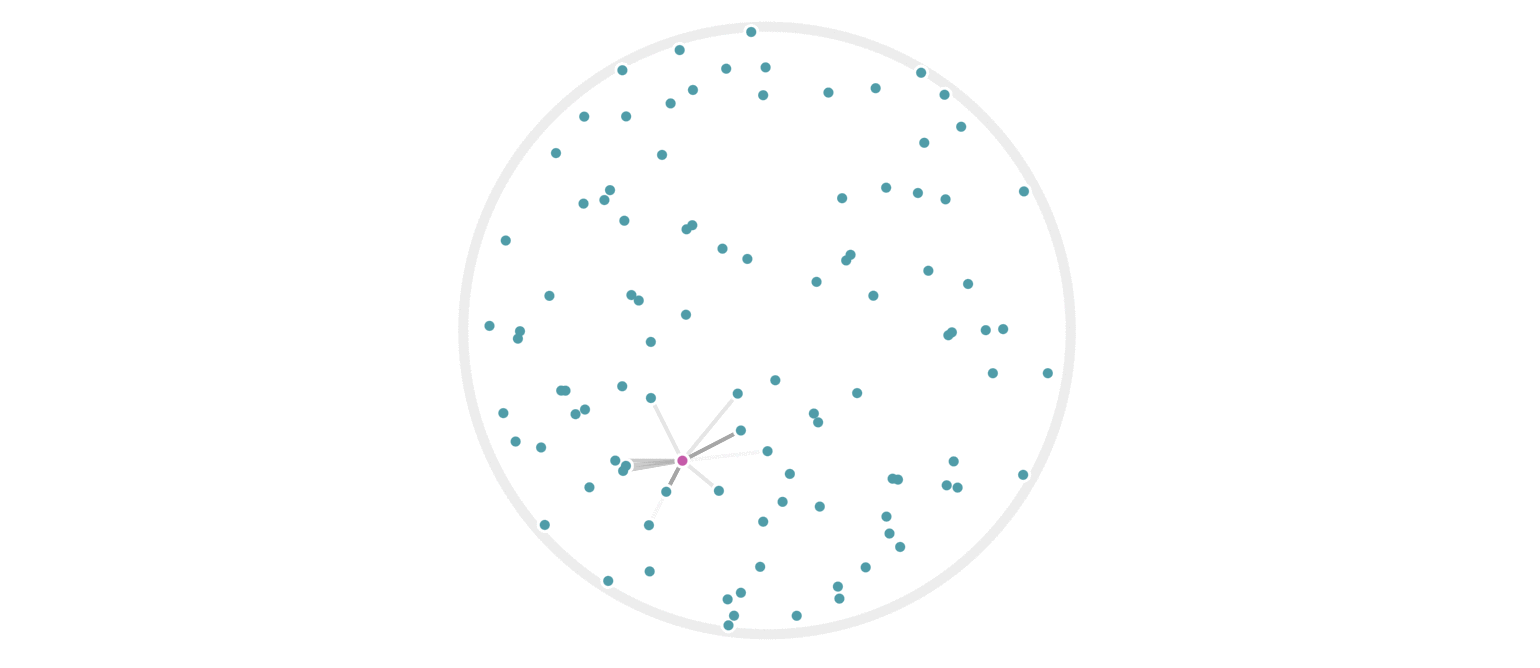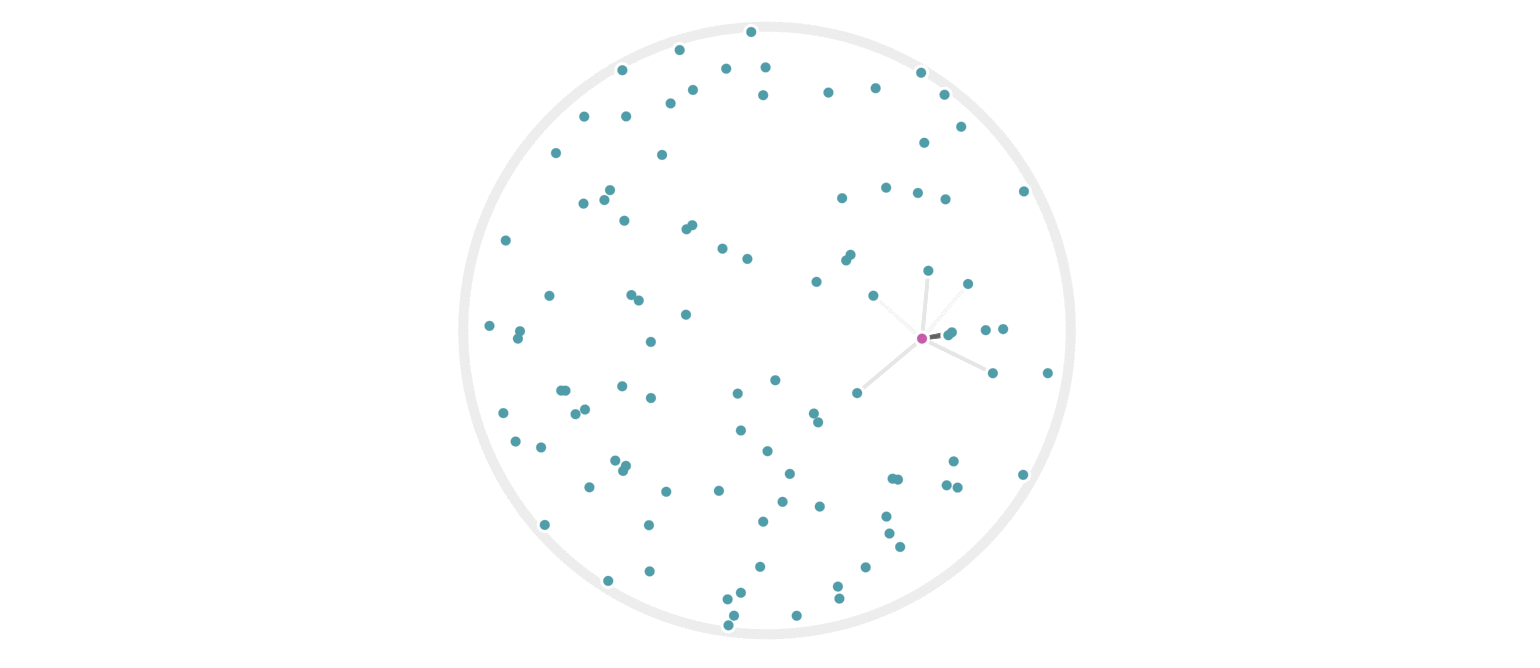
This Python project utilizes LSH to efficiently find similar items in a large collection of text data. It employs techniques to preprocess text, generate shingles (short overlapping substrings) from text documents, and then create hash signatures for these shingles. These hash signatures are further processed and compared to identify similar documents.
-
Text Preprocessing: Text data undergoes preprocessing steps including lowercasing, removal of special characters, and redundant spaces, ensuring consistency in representations.
-
Shingling: Shingles, contiguous substrings of fixed length from the text, are generated. These shingles provide a compact representation of the text content, enabling efficient comparison.
-
Minhashing: Minhashing is employed to create hash signatures for shingles. Multiple permutations of indices are generated, and for each permutation, the first index of the shingle present in the text determines the hash value.
-
Locality Sensitive Hashing (LSH): The hash signatures are partitioned into bands and rows, facilitating comparison between documents. Similarity between documents is determined by comparing bands of hash signatures.
-
Data Preprocessing: The text data is preprocessed to ensure uniform representation and remove noise.
-
Shingling and Minhashing: Shingles are generated from the text, and hash signatures are computed using minhashing techniques.
-
LSH Indexing: The hash signatures are stored for efficient retrieval during similarity search.
-
Similarity Search: Given an input text, similarity search is performed by comparing its hash signature with precomputed signatures, utilizing LSH to efficiently identify similar documents.
This project finds applications in various domains:
- Document Similarity: Identifying similar documents in a large corpus for plagiarism detection or document clustering.
- Recommendation Systems: Recommending similar items (e.g., games, movies) to users based on their preferences.
- Data Deduplication: Detecting and eliminating duplicate entries in databases or datasets.
- Python 3.12
- NumPy 1.24.4
- pandas 2.0.1
- tqdm 4.65.0
Contributions to this project are welcome. Feel free to fork the repository, make enhancements, and submit pull requests.