add extract_pii/deidentify to BatchProcessor via an operation parameter#61
Conversation
|
Thanks for opening this. I kept the operation= API direction from the draft and pushed a follow-up commit on this branch that fills out the production path for issue #33. What changed:
Validation run locally:
|
|
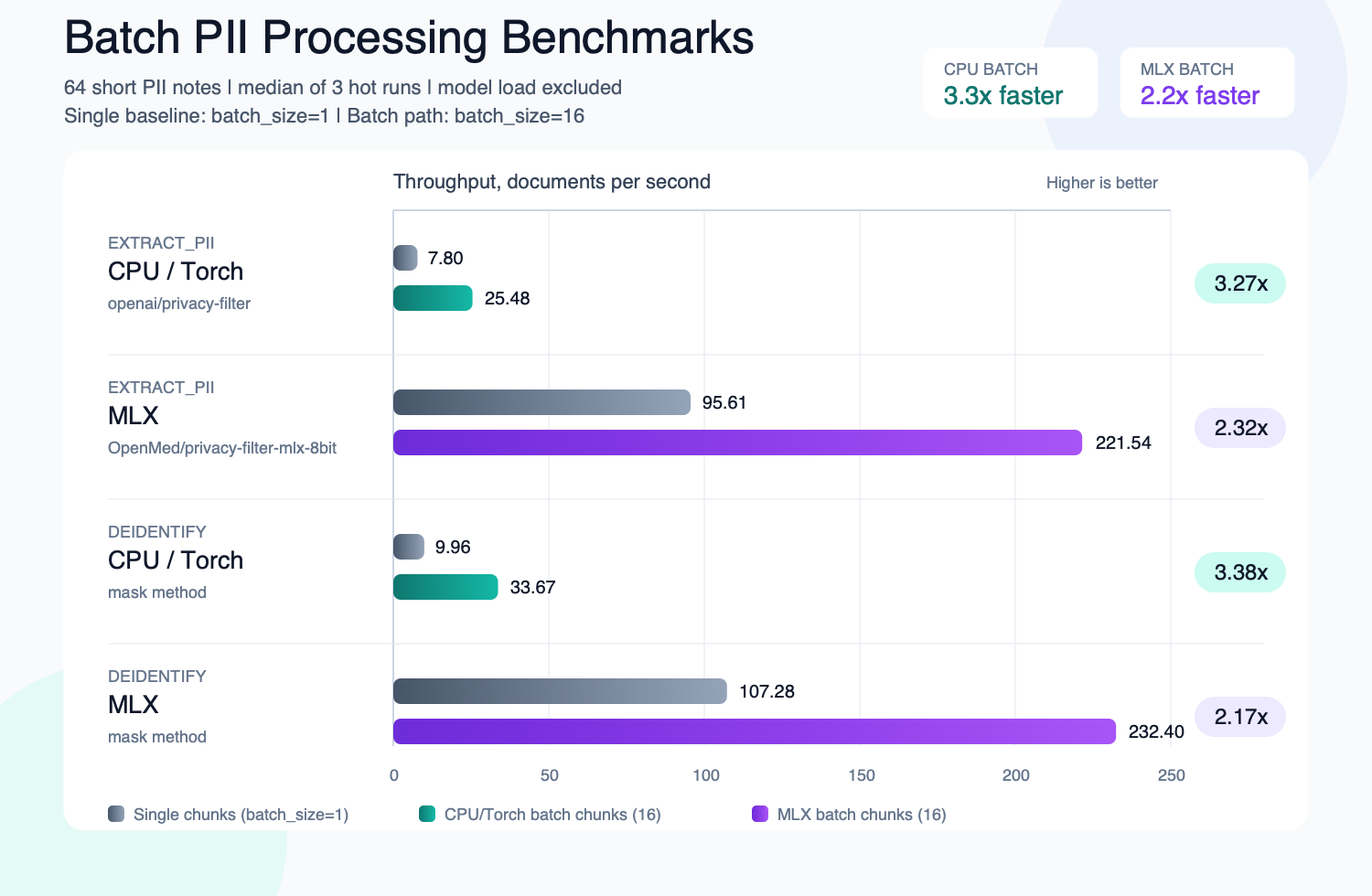
Follow-up benchmark after tightening the batch path in Setup: macOS arm64, 64 short clinical/PII notes, median of 3 hot runs after one warmup call. The single baseline is
CPU/Torch batch now forwards |
|
Added a visual summary for the hot-run benchmark numbers:
The source SVG and PNG are now on this branch under |
Summary
This PR adds real multi-document batch support for PII extraction and de-identification in
BatchProcessor, addressing #33 for larger record workloads.It keeps the useful
operation=API direction from the original draft and expands it beyond a per-item wrapper:What Changed
BatchProcessor(operation=...)values:"analyze_text"for existing clinical NER behavior"extract_pii"for batch PII extraction"deidentify"for batch redaction/anonymizationbatch_sizechunking for PII operations.ModelLoaderor privacy-filter pipeline across a batch job instead of rebuilding work per item/chunk.process_texts,process_files,process_directory,iter_process, and module-levelprocess_batch(...)surfaces.continue_on_error=Truefallback behavior andcontinue_on_error=Falseimmediate raise behavior.BatchItemResultcan carry eitherPredictionResultorDeidentificationResult.examples/pii_batch_processing.py.Performance
Hot-run benchmark on 64 short PII notes, median of 3 runs after one warmup call. Model load is excluded; the single baseline uses
BatchProcessor(..., batch_size=1)and the batch path usesbatch_size=16.extract_piiopenai/privacy-filterextract_piiOpenMed/privacy-filter-mlx-8bitdeidentifyopenai/privacy-filterdeidentifyOpenMed/privacy-filter-mlx-8bitBackend-specific performance work in this branch:
batch_sizeto the Transformers privacy-filter pipeline.BatchProcessorcaches the privacy-filter pipeline across chunks for the batch job.Tests And Docs
Validation run locally:
Results:
173 passed, 1 skipped1194 passed, 1 skippedRelated Issues
Closes #33