Goodreads is a website where readers can rate and review the books they read. My interest in reading is what motivated me to scrape Goodreads. The aim of this project was to scrape, clean and analyse data from the Top 1000 books of the Decade: 2010's. Data has been scraped from the ‘Best Books of the Decade: 2010's’ list using the python library BeautifulSoup.
- Data Collection : Building a scraper to collect and organize data from Reading Lists on Goodreads.
- Data Cleaning : Cleaning and organising the scraped data.
- Visualization and Analysis: Detailed visualization and analysis of the cleaned books data.
Libraries Used : pandas, numpy, matplotlib, seaborn, plotly, cufflinks, chart_studio, bs4, random, time
P.S - To access the interactive version of the plots, please checkout the link mentioned at the bottom of this page.
Data has been collected from the ‘Best Books of the Decade: 2010's’ list.
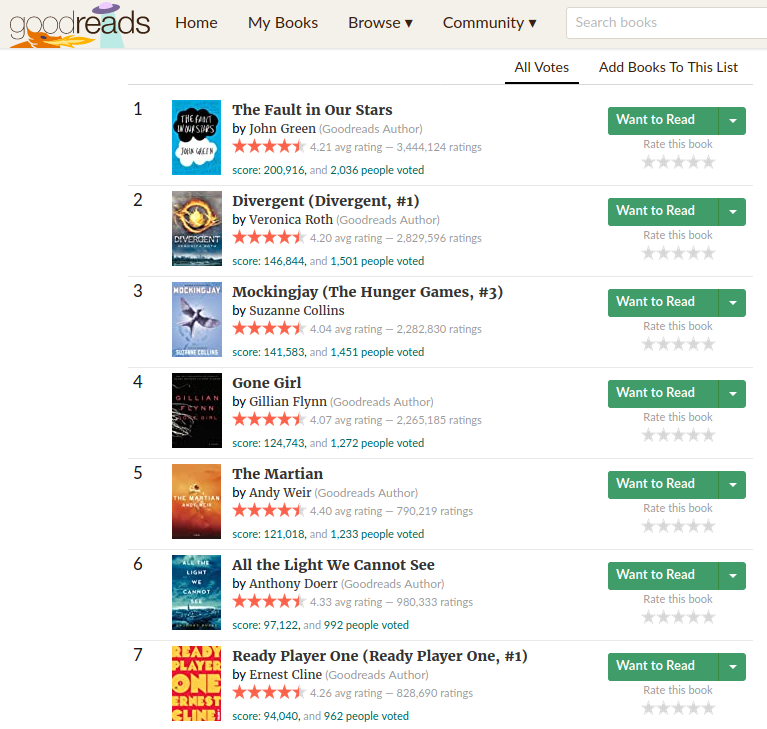
- Book Title
- Series Name
- Author Name
- Average Rating
In order to collect more detailed information about each book we access each individual book's url :
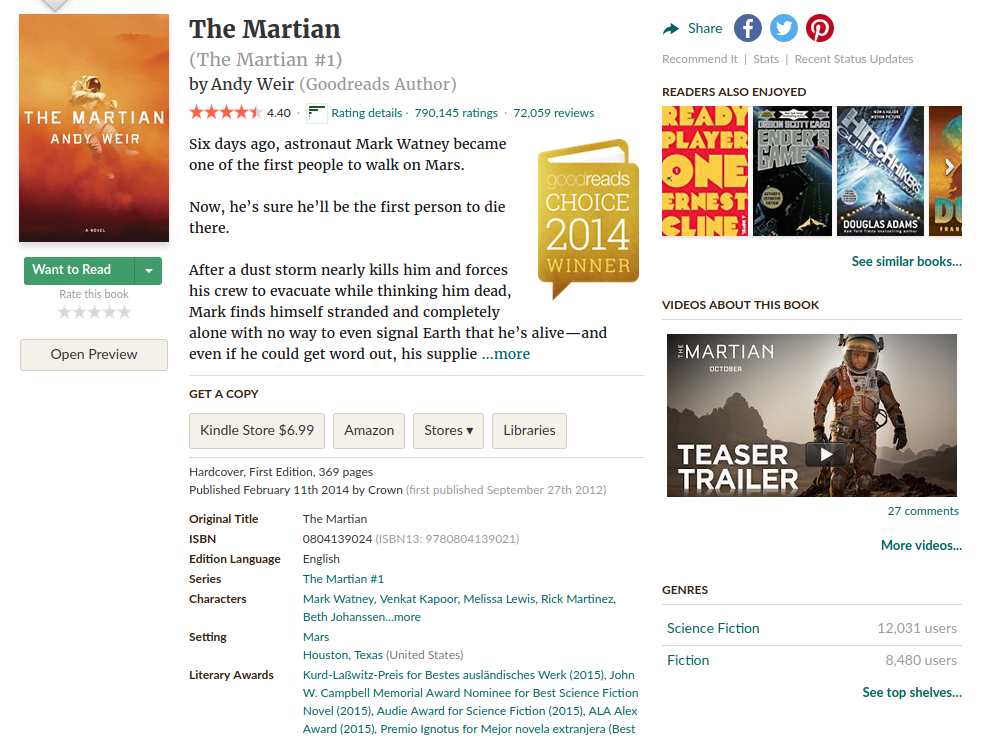
- Book Description
- Awards
- Genres
The collected data consisted of missing values and unclean data. Various cleaning operations were performed using pandas library such as :
- Average Ratings, Number of ratings, etc columns which were in string format were converted to int and float.
- Columns containing unwanted characters such as 'avg rating', 'really liked it', 'score: ' were removed.
- Titles column was separated into 'Book Title' and 'Series Title' columns.
- Awards column was converted to Number of Awards.
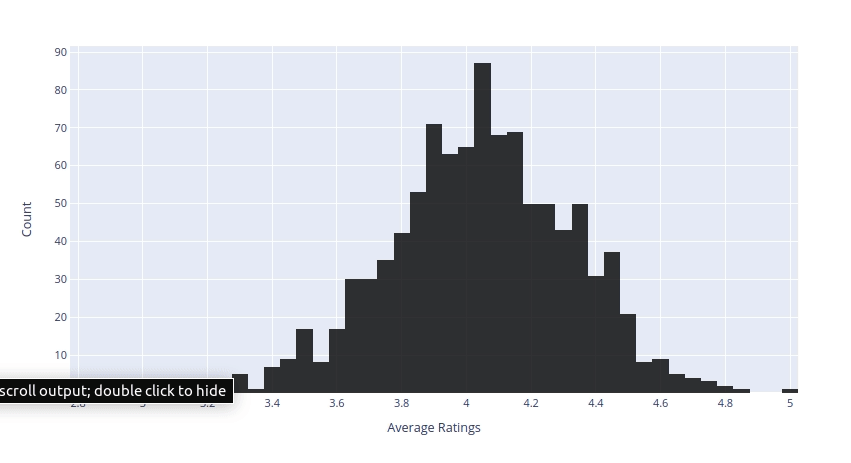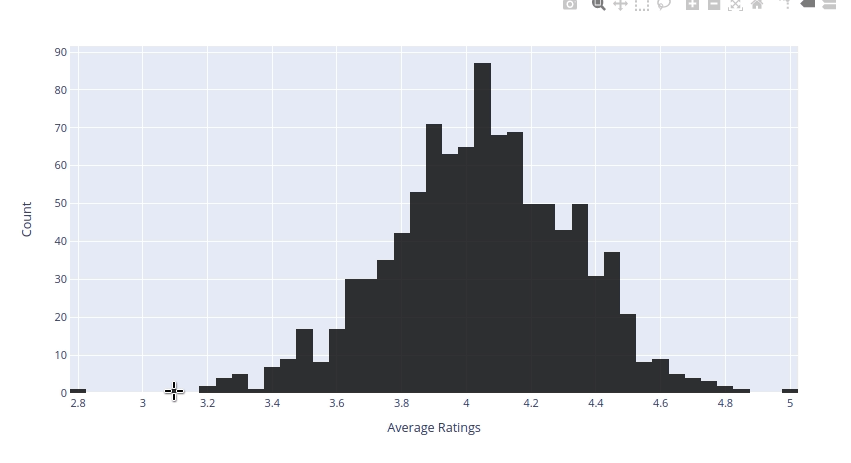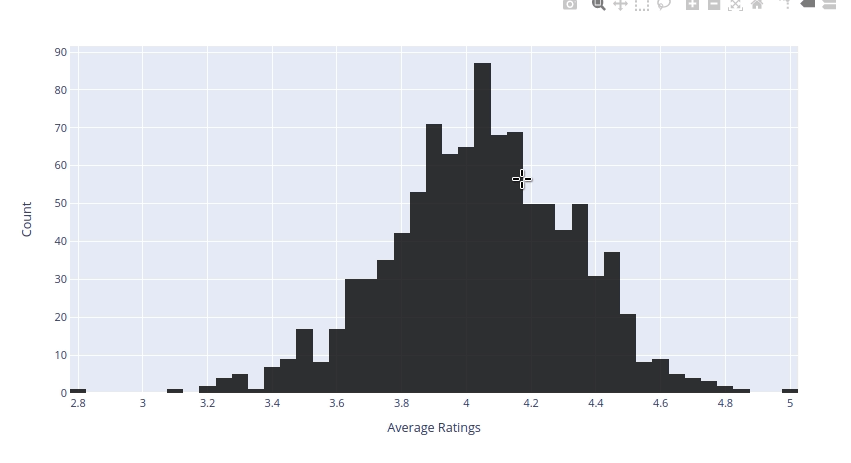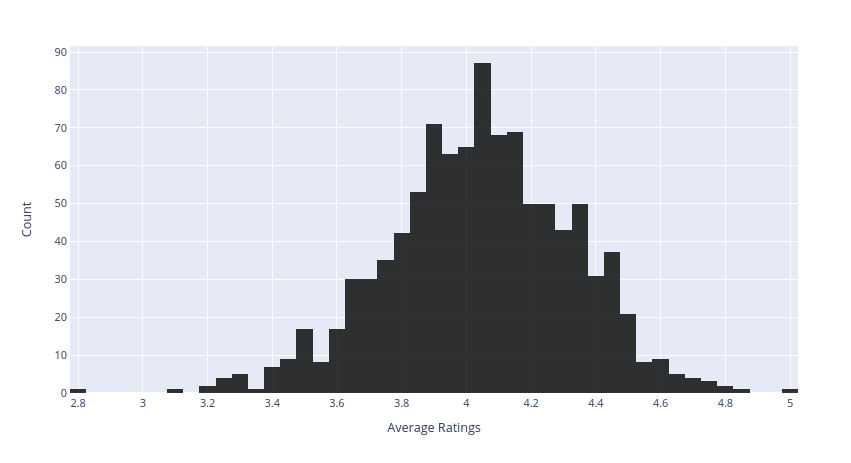
- Distribution of Average Rating
- Distribution of Genre
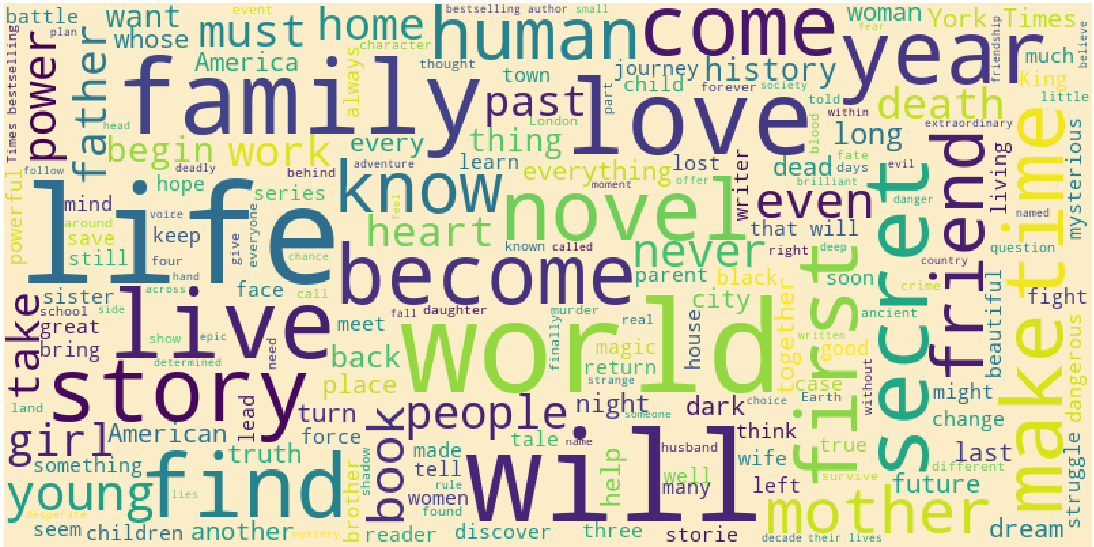
- Wordclouds for Book Titles, Author names and Description
- Distribution of Number of Pages and further analysis can be found in the jupyter notebook.
{kind=link}
We can see that the majority of the books have received a rating between 4.03 and 4.07. We can also see that the average ratings follow a normal distribution.
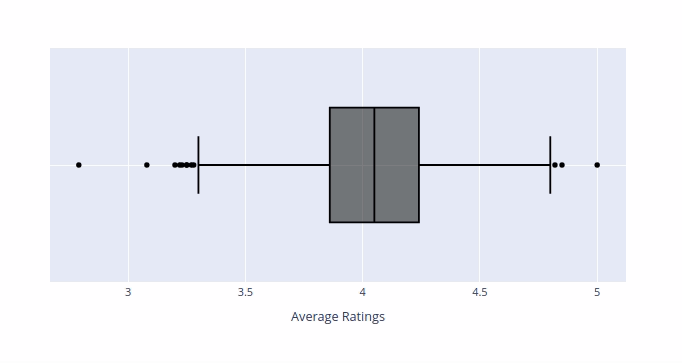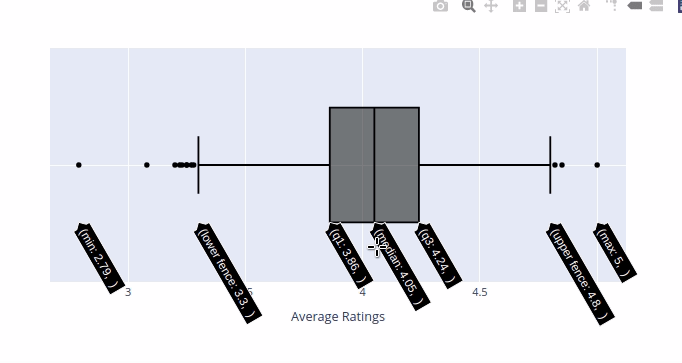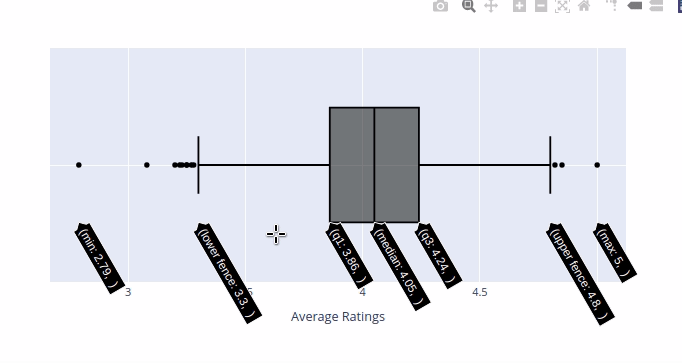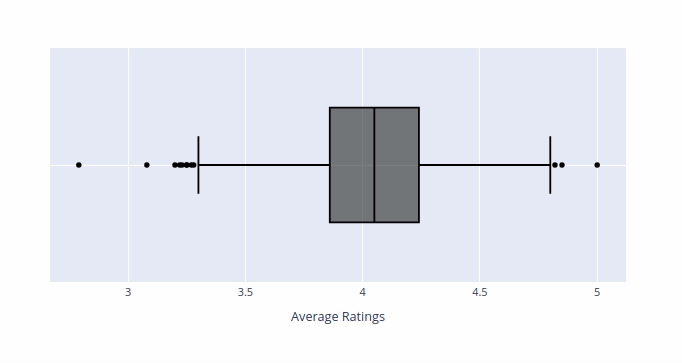
Above histogram give us a good indication of the distribution of the data but it don't give us much information about the outliers. We can use Boxplot to examine the outliers.
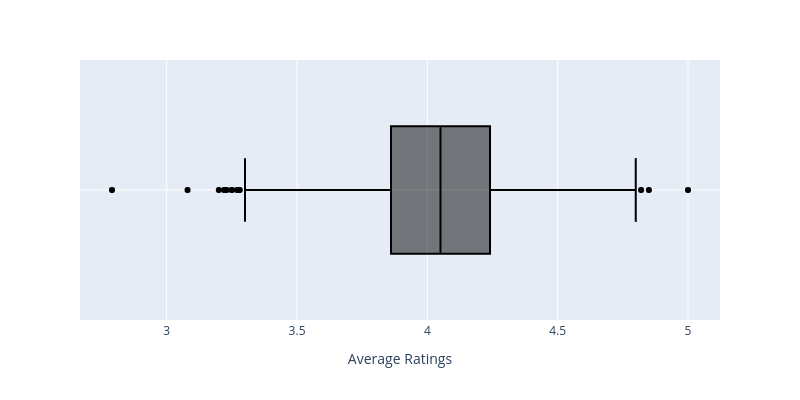{kind=link}
- Median Average Rating = 4.05
- IQR (Middle 50 percent) = 0.38
- White boy in Watts - 5.0
- Shadow Team GB - 4.85
- The Finkler Question - 2.79
- The Secret Lives of People - 3.08
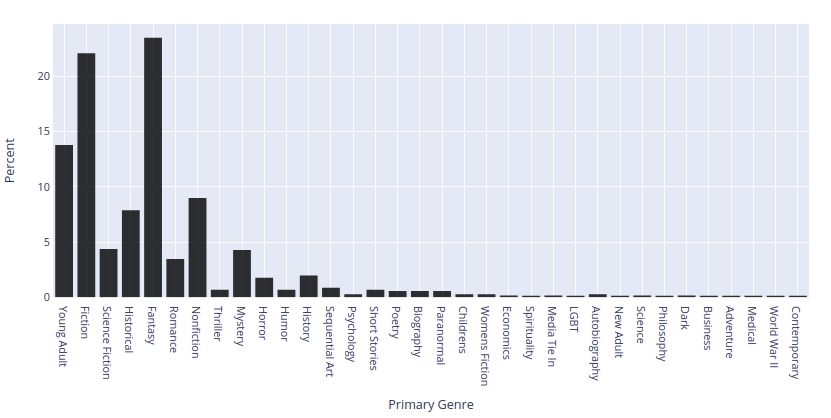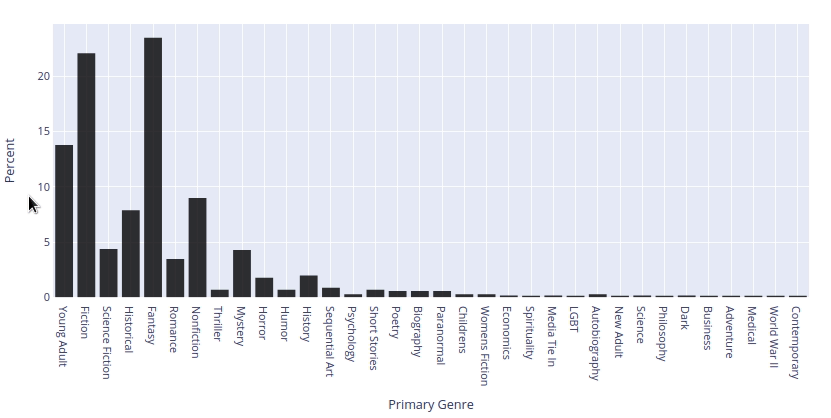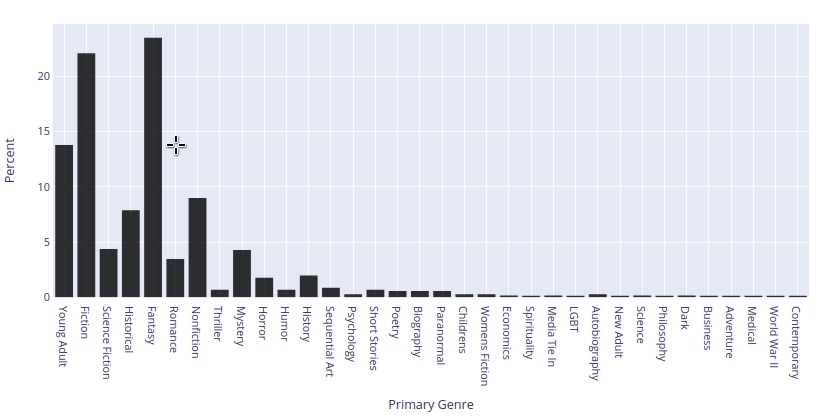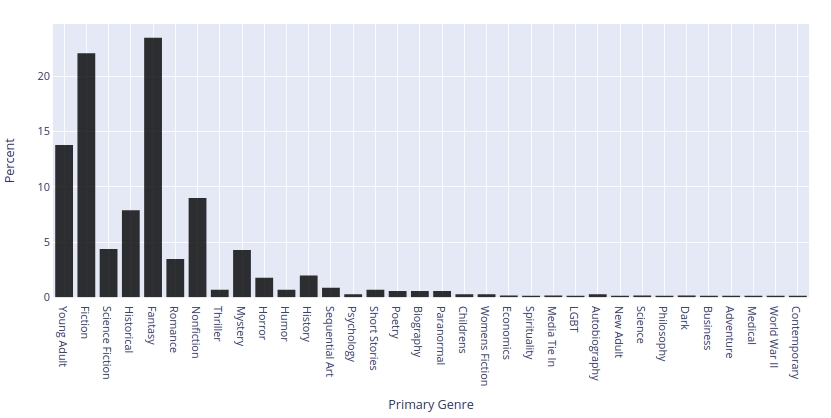
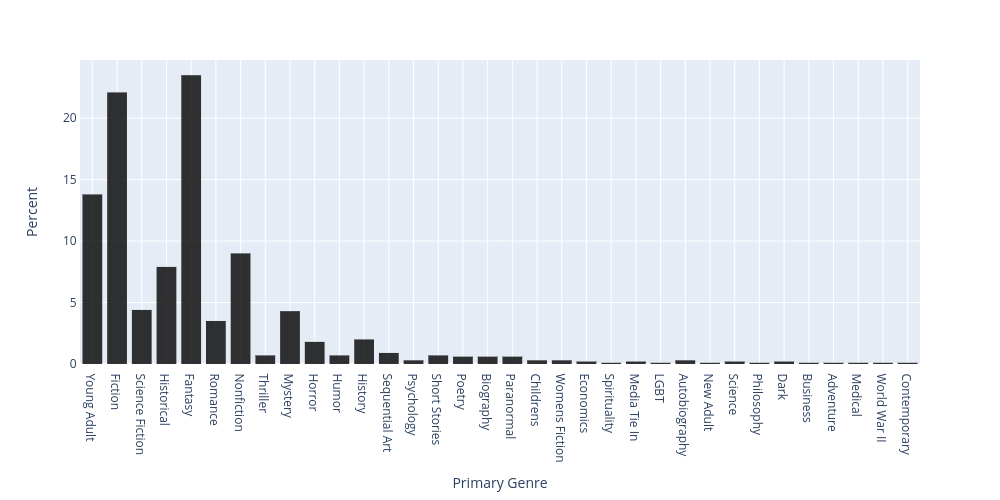{kind=link}
- Fantasy - 23.5%
- Fiction - 22.1%
- Young Adult - 13.8%
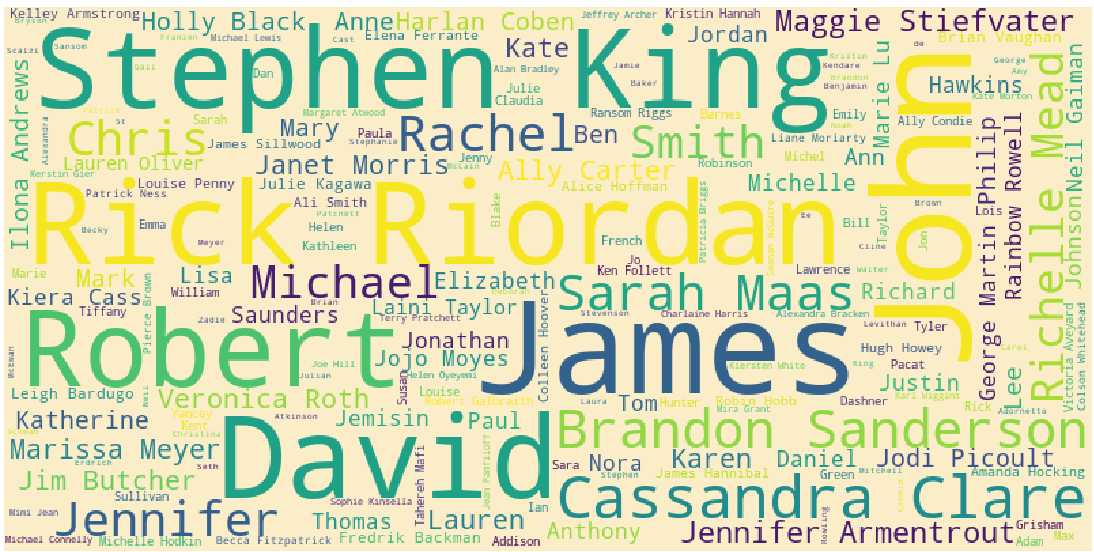
The abover wordcloud contains names of some legendary authors such as : Stephen King and Rick Riordan and certain generic names such as John, David, Robert and James.