perf(gpu): avoid temporary half-value staging in LogUp GKR#2806
Open
peter941221 wants to merge 2 commits into
Open
perf(gpu): avoid temporary half-value staging in LogUp GKR#2806peter941221 wants to merge 2 commits into
peter941221 wants to merge 2 commits into
Conversation
Author
|
f933bda to
2dc9248
Compare
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
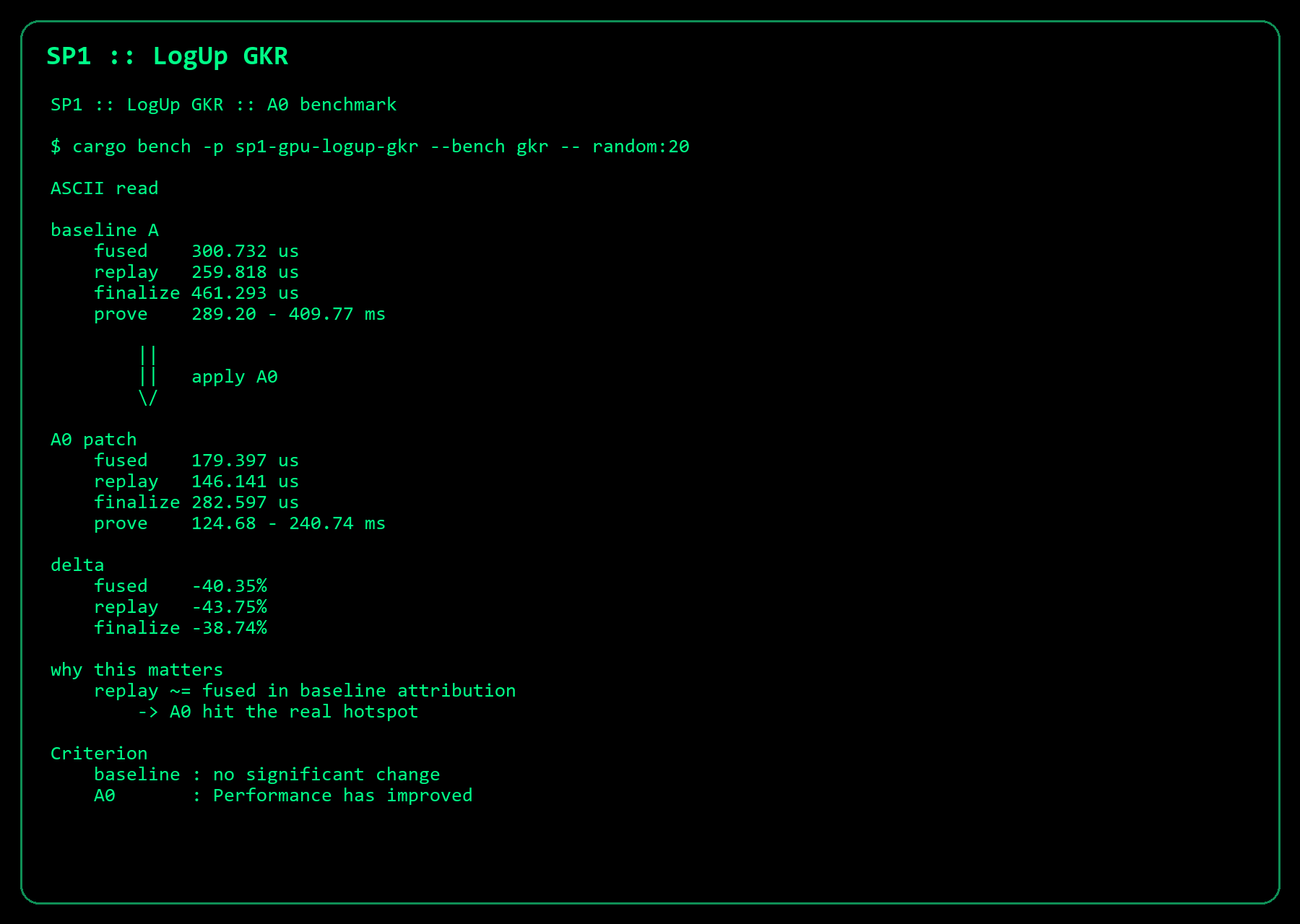
This PR removes temporary half-value struct materialization inside the measured LogUp GKR circuit-layer hotspot. In the strongest same-session local A/B,
fix_and_sum_circuit_layer.gpu_execmoved from300.732usto179.397us, replayedsum_as_polymoved from259.818usto146.141us, and the fused boundary timing moved from461.293usto282.597us.This is a narrow hot-path change in
sp1-gpu/crates/sys/include/logup_gkr/round.cuh.Inside
sumAsPolyCircuitLayerInner, the patch stops materializing a temporaryCircuitValues valuesHalfstruct just to evaluate the half-point. Instead, it computes the four half-point scalars directly and feeds them into a scalar helper that preserves the existingsumAsPolyarithmetic.The patch does not change transcript order, kernel topology, output layout, or finalize logic.
This patch came out of profiling, not blind arithmetic tuning.
2.1 Fine-grained timing first made
finalize_univariatelook hot.2.2 Forced-sync stage attribution then moved the remaining cost into the fused circuit-layer producer.
2.3 Safe replay attribution on the real fused output showed that replayed
sum_as_polyalone was almost as expensive as the whole fused producer.In the local baseline replay run:
fix_and_sum_circuit_layer.gpu_exec:220.702usfix_and_sum_circuit_layer.sum_as_poly_replay.gpu_exec:216.164usThat is why this PR targets
sumAsPolyCircuitLayerInnerinstead of another finalize-only rewrite or a broader transition rewrite.I restaged the winning
A0cut onto a clean branch frommain@98a376e87ec9dd5c3ae3495b98846bf921d6035band reran compile validation on the outgoing branch.Outgoing branch:
peter941221:perf/logup-gkr-a0Outgoing commit:
f933bda3810b2f0dfe0788175df9518f7e657956Command:
wsl.exe -d Ubuntu-24.04 -- bash -lc "cd <temporary WSL verification worktree> && cargo check -p sp1-gpu-logup-gkr"Result:
passed
The strongest evidence is a same-session baseline versus patched comparison on the same
mainbase.Baseline:
fix_and_sum_circuit_layer.gpu_exec:300.732usfix_and_sum_circuit_layer.sum_as_poly_replay.gpu_exec:259.818ussumcheck.finalize_univariate.total_after_explicit_sync:461.293usprove/random/core_2^20:289.20-409.77msPatched:
fix_and_sum_circuit_layer.gpu_exec:179.397usfix_and_sum_circuit_layer.sum_as_poly_replay.gpu_exec:146.141ussumcheck.finalize_univariate.total_after_explicit_sync:282.597usprove/random/core_2^20:124.68-240.74msCriterion reported
Performance has improvedon that patched run.A later patched confirmation kept the same stage-level direction:
fix_and_sum_circuit_layer.gpu_exec:177.666usfix_and_sum_circuit_layer.sum_as_poly_replay.gpu_exec:144.523ussumcheck.finalize_univariate.total_after_explicit_sync:307.568usI also tried a broader follow-up that removed the local
valuesZeroandvaluesOnestruct staging too, and it regressed clearly.Versus the stronger
A0run:fix_and_sum_circuit_layer.gpu_exec:179.397us -> 271.304usfix_and_sum_circuit_layer.sum_as_poly_replay.gpu_exec:146.141us -> 231.833ussumcheck.finalize_univariate.total_after_explicit_sync:282.597us -> 407.165usThe same end-to-end run also regressed to
prove/random/core_2^20 = 389.69-468.00ms.So the reviewer story here is intentionally narrow: removing the temporary half-value staging helped, while flattening the rest of the path did not.
The strongest claim here is stage-level first and end-to-end second.
The stage signal is repeatable locally. The end-to-end
prove/random/core_2^20result still has enough variance that I do not want to oversell it beyond the measured data above.