卡卡字幕助手
一款基於大語言模型(LLM)的視頻字幕處理助手,支持語音識別、字幕斷句、優化、翻譯全流程處理
卡卡字幕助手(VideoCaptioner)操作簡單且無需高配置,支持 API 和本地離線兩種方式進行語音識別,利用大語言模型進行字幕智能斷句、校正、翻譯,字幕視頻全流程一鍵處理。為視頻配上效果驚艷的字幕。
- 支持詞級時間戳與 VAD 語音活動檢測,識別準確率高
- 基於 LLM 的語義理解,自動將逐字字幕重組為自然流暢的句子段落
- 結合上下文的 AI 翻譯,支持反思優化機制,譯文地道專業
- 支持批量視頻字幕合成,提升處理效率
- 直觀的字幕編輯查看介面,支持即時預覽和快捷編輯

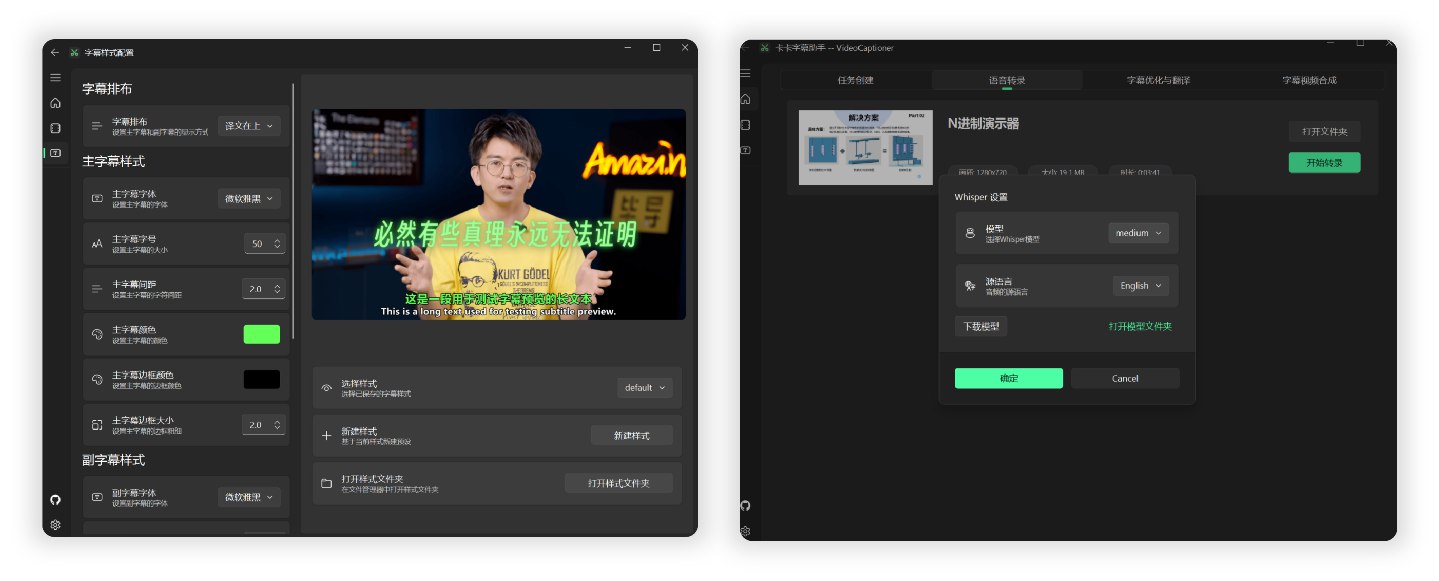
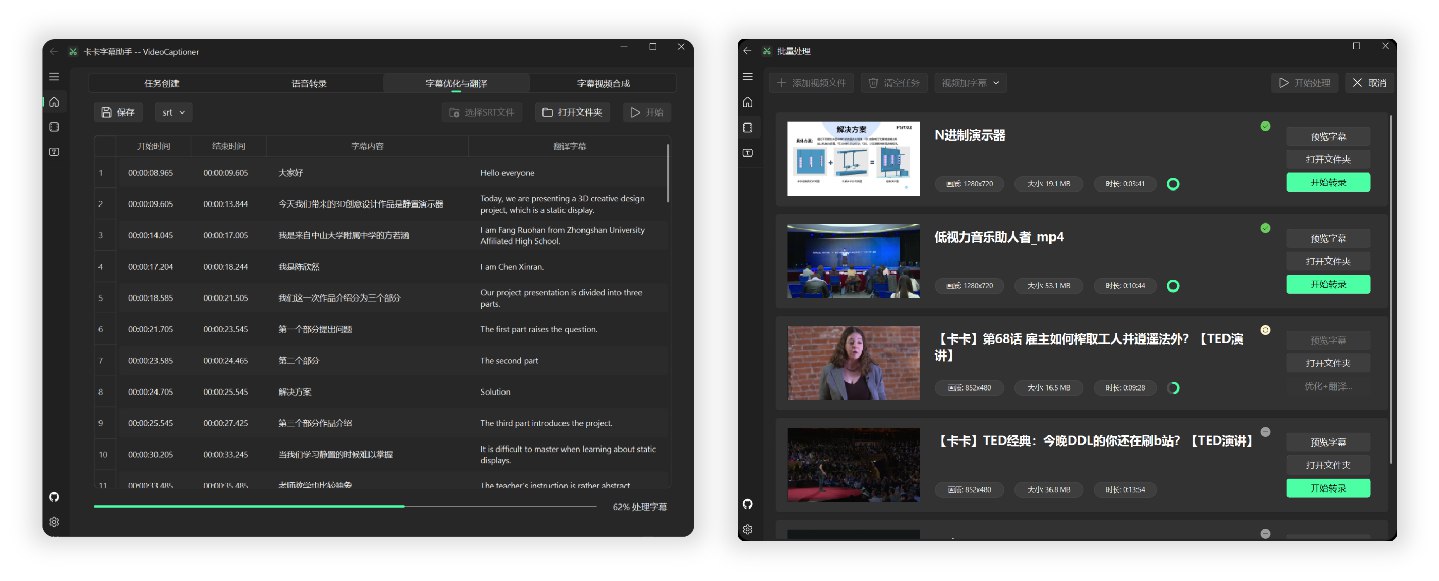
全流程處理一個 14 分鐘 1080P 的 B站英文 TED 視頻,調用本地 Whisper 模型進行語音識別,使用 gpt-5-mini 模型優化和翻譯為中文,總共消耗時間約 4 分鐘。
根據後台計算,模型優化和翻譯消耗費用不足 ¥0.01(以 OpenAI 官方價格計算)
具體字幕和視頻合成效果的測試結果圖片,請參考 TED 視頻測試
軟體較為輕量,打包大小不足 60M,已集成所有必要環境,下載後可直接運行。
-
打開安裝包進行安裝
-
LLM API 配置(用於字幕斷句、校正),可使用本項目的中轉站
-
翻譯配置,選擇是否啟用翻譯,翻譯服務(預設使用微軟翻譯,質量一般,推薦配置自己的 API KEY 使用大模型翻譯)
-
語音識別配置(預設使用B介面網路調用語音識別服務,中英以外的語言請使用本地轉錄)
# 方式一:直接運行(自動安裝 uv、克隆項目、安裝相關依賴)
curl -fsSL https://raw.githubusercontent.com/WEIFENG2333/VideoCaptioner/main/scripts/run.sh | bash
# 方式二:先克隆再運行
git clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner
./scripts/run.sh腳本會自動:
- 安裝 uv 套件管理器(如果未安裝)
- 克隆項目到
~/VideoCaptioner(如果不在項目目錄中運行) - 安裝所有 Python 依賴
- 啟動應用
手動安裝步驟
curl -LsSf https://astral.sh/uv/install.sh | shbrew install ffmpeggit clone https://github.com/WEIFENG2333/VideoCaptioner.git
cd VideoCaptioner
uv sync # 安裝依賴
uv run python main.py # 運行# 安裝依賴(包括開發依賴)
uv sync
# 運行應用
uv run python main.py
# 類型檢查
uv run pyright
# 代碼檢查
uv run ruff check .LLM 大模型是用來字幕斷句、字幕優化、以及字幕翻譯(如果選擇了LLM 大模型翻譯)。
| 配置項 | 說明 |
|---|---|
| SiliconCloud | SiliconCloud 官網配置方法請參考配置文檔 該並發較低,建議把線程設置為5以下。 |
| DeepSeek | DeepSeek 官網,建議使用 deepseek-v3 模型。 |
| OpenAI兼容介面 | 如果有其他服務商的API,可直接在軟體中填寫。base_url 和api_key VideoCaptioner API |
注:如果用的 API 服務商不支持高並發,請在軟體設置中將「線程數」調低,避免請求錯誤。
如果希望高並發,或者希望在軟體內使用 OpenAI 或者 Claude 等優質大模型進行字幕校正和翻譯。
可使用本項目的✨LLM API中轉站✨: https://api.videocaptioner.cn
其支持高並發,性價比極高,且有國內外大量模型可挑選。
註冊獲取key之後,設置中按照下面配置:
BaseURL: https://api.videocaptioner.cn/v1
API-key: 個人中心-API 令牌頁面自行獲取。
💡 模型選擇建議 (本人在各質量層級中精選出的高性價比模型):
-
高質量之選:
gemini-3-pro、claude-sonnet-4-5-20250929(耗費比例:3) -
較高質量之選:
gpt-5-2025-08-07、claude-haiku-4-5-20251001(耗費比例:1.2) -
中質量之選:
gpt-5-mini、gemini-3-flash(耗費比例:0.3)
本站支持超高並發,軟體中線程數直接拉滿即可~ 處理速度非常快~
更詳細的API配置教程:中轉站配置
| 配置項 | 說明 |
|---|---|
| LLM 大模型翻譯 | 🌟 翻譯質量最好的選擇。使用 AI 大模型進行翻譯,能更好理解上下文,翻譯更自然。需要在設置中配置 LLM API(比如 OpenAI、DeepSeek 等) |
| 微軟翻譯 | 使用微軟的翻譯服務,速度非常快 |
| 谷歌翻譯 | 谷歌的翻譯服務,速度快,但需要能訪問谷歌的網路環境 |
推薦使用 LLM 大模型翻譯 ,翻譯質量最好。
| 介面名稱 | 支持語言 | 運行方式 | 說明 |
|---|---|---|---|
| B介面 | 僅支持中文、英文 | 線上 | 免費、速度較快 |
| J介面 | 僅支持中文、英文 | 線上 | 免費、速度較快 |
| WhisperCpp | 中文、日語、韓語、英文等 99 種語言,外語效果較好 | 本地 | (實際使用不穩定)需要下載轉錄模型 中文建議medium以上模型 英文等使用較小模型即可達到不錯效果。 |
| fasterWhisper 👍 | 中文、英文等多99種語言,外語效果優秀,時間軸更準確 | 本地 | (🌟推薦🌟)需要下載程式和轉錄模型 支持CUDA,速度更快,轉錄準確。 超級準確的時間戳字幕。 僅支持 Windows |
Whisper 版本有 WhisperCpp 和 fasterWhisper(推薦) 兩種,後者效果更好,都需要自行在軟體內下載模型。
| 模型 | 磁碟空間 | 記憶體佔用 | 說明 |
|---|---|---|---|
| Tiny | 75 MiB | ~273 MB | 轉錄很一般,僅用於測試 |
| Small | 466 MiB | ~852 MB | 英文識別效果已經不錯 |
| Medium | 1.5 GiB | ~2.1 GB | 中文識別建議至少使用此版本 |
| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允許情況推薦使用 |
| Large-v3 | 2.9 GiB | ~3.9 GB | 社區反饋可能會出現幻覺/字幕重複問題 |
推薦模型: Large-v2 穩定且質量較好。
- 在「字幕優化與翻譯」頁面,包含「文稿匹配」選項,支持以下一種或者多種內容,輔助校正字幕和翻譯:
| 類型 | 說明 | 填寫示例 |
|---|---|---|
| 術語表 | 專業術語、人名、特定詞語的修正對照表 | 機器學習->Machine Learning 馬斯克->Elon Musk 打call -> 應援 圖靈斑圖 公車悖論 |
| 原字幕文稿 | 視頻的原有文稿或相關內容 | 完整的演講稿、課程講義等 |
| 修正要求 | 內容相關的具體修正要求 | 統一人稱代詞、規範專業術語等 填寫內容相關的要求即可,示例參考 |
- 如果需要文稿進行字幕優化輔助,全流程處理時,先填寫文稿資訊,再進行開始任務處理
- 注意: 使用上下文參數量不高的小型LLM模型時,建議控制文稿內容在1千字內,如果使用上下文較大的模型,則可以適當增加文稿內容。
無特殊需求,可不填寫。
如果使用URL下載功能時,如果遇到以下情況:
- 下載視頻網站需要登入資訊才可以下載;
- 只能下載較低解析度的視頻;
- 網路條件較差時需要驗證;
- 請參考 Cookie 配置說明 獲取Cookie資訊,並將cookies.txt檔案放置到軟體安裝目錄的
AppData目錄下,即可正常下載高質量視頻。
程式簡單的處理流程如下:
語音識別轉錄 -> 字幕斷句(可選) -> 字幕優化翻譯(可選) -> 字幕視頻合成
軟體利用大語言模型(LLM)在理解上下文方面的優勢,對語音識別生成的字幕進一步處理。有效修正錯別字、統一專業術語,讓字幕內容更加準確連貫,為用戶帶來出色的觀看體驗!
- 支持國內外主流視頻平台(B站、Youtube、小紅書、TikTok、X、西瓜視頻、抖音等)
- 自動提取視頻原有字幕處理
- 提供多種介面線上識別,效果媲美剪映(免費、高速)
- 支持本地Whisper模型(保護隱私、可離線)
- 自動優化專業術語、代碼片段和數學公式格式
- 上下文進行斷句優化,提升閱讀體驗
- 支持文稿提示,使用原有文稿或者相關提示優化字幕斷句
- 結合上下文的智能翻譯,確保譯文兼顧全文
- 透過Prompt指導大模型反思翻譯,提升翻譯質量
- 使用序列模糊匹配算法、保證時間軸完全一致
- 豐富的字幕樣式模板(科普風、新聞風、番劇風等等)
- 多種格式字幕視頻(SRT、ASS、VTT、TXT)
項目主要目錄結構說明如下:
VideoCaptioner/
├── app/ # 應用源代碼目錄
│ ├── common/ # 公共模組(配置、信號匯流排)
│ ├── components/ # UI 元件
│ ├── core/ # 核心業務邏輯(ASR、翻譯、優化等)
│ ├── thread/ # 異步線程
│ └── view/ # 介面視圖
├── resource/ # 資源檔案目錄
│ ├── assets/ # 圖示、Logo 等
│ ├── bin/ # 二進制程式(FFmpeg、Whisper 等)
│ ├── fonts/ # 字體檔案
│ ├── subtitle_style/ # 字幕樣式模板
│ └── translations/ # 多語言翻譯檔案
├── work-dir/ # 工作目錄(處理完成的視頻和字幕)
├── AppData/ # 應用資料目錄
│ ├── cache/ # 快取目錄(轉錄、LLM 請求)
│ ├── models/ # Whisper 模型檔案
│ ├── logs/ # 日誌檔案
│ └── settings.json # 用戶設置
├── scripts/ # 安裝和運行腳本
├── main.py # 程式入口
└── pyproject.toml # 項目配置和依賴
-
字幕斷句的質量對觀看體驗至關重要。軟體能將逐字字幕智能重組為符合自然語言習慣的段落,並與視頻畫面完美同步。
-
在處理過程中,僅向大語言模型發送文本內容,不包含時間軸資訊,這大大降低了處理開銷。
-
在翻譯環節,我們採用吳恩達提出的「翻譯-反思-翻譯」方法論。這種迭代優化的方式確保了翻譯的準確性。
-
填入 YouTube 連結時進行處理時,會自動下載視頻的字幕,從而省去轉錄步驟,極大地節省操作時間。
項目在不斷完善中,如果在使用過程遇到的Bug,歡迎提交 Issue 和 Pull Request 幫助改進項目。
查看完整的更新歷史,請訪問 CHANGELOG.md
如果覺得項目對你有幫助,可以給項目點個Star!
捐助支持

