Releases: jundot/omlx
v0.3.0rc1
This is a pre-release of oMLX 0.3.0. It will go through 1 day of testing before the official release. If you find any bugs, please report them on the issues page!
Highlights
Audio support — STT, TTS, STS
mlx-audio integration brings three new engine types for audio models on Apple Silicon. by @ethannortharc
- STT (Speech-to-Text): Whisper, Qwen3-ASR, Parakeet, Voxtral
- TTS (Text-to-Speech): Qwen3-TTS, Kokoro, F5-TTS, Sesame CSM, Dia, Spark, CosyVoice
- STS (Speech-to-Speech): DeepFilterNet, MossFormer2, SAMAudio, LFM2.5-Audio
Three new OpenAI-compatible endpoints: /v1/audio/transcriptions, /v1/audio/speech, /v1/audio/process (oMLX-specific). Audio models are automatically detected from the mlx-audio registry and show up in the admin dashboard alongside LLM/VLM models.

Optional dependency — pip install 'omlx[audio]'. Homebrew and DMG builds include mlx-audio by default. (#365)
XGrammar constrained decoding
xgrammar-based structured output generation by @leuski. Enforces grammar constraints at the logit level using bitmasks, running in parallel with the model forward pass via mx.async_eval.
Supported grammar types:
json— JSON schema validationregex— regular expression patternsgrammar— EBNF/GBNF grammarschoice— allowed string lists
Uses vLLM-compatible structured_outputs field (in extra_body). Per-model reasoning_parser config maps xgrammar's structural tags to model protocols (Qwen, Harmony, DeepSeek, Llama, etc.). Performance overhead is 9–24% on decode (no TTFT impact), decreasing with larger models.
Optional dependency — pip install 'omlx[grammar]'. Homebrew and DMG builds include xgrammar by default. Without it, response_format falls back to prompt injection and structured_outputs returns a 400 with install instructions. (#335)
New Features
- XTC sampler — XTC (eXclude Top Choices) sampling support. Pass
xtc_probabilityandxtc_thresholdthrough any API endpoint. Defaults to 0.0 (disabled) (#337 by @blightbow) - MCP Streamable HTTP — MCP now supports Streamable HTTP transport in addition to stdio (#286 by @tianfeng98)
- Multimodal embedding items —
/v1/embeddingsaccepts structureditemswith text + image input. Tested withQwen3-VL-Embedding-2B-mxfp8(#373 by @MasakiMu319) - Custom processor embedding support — Embedding requests route through custom processor hooks when available, fixing models like Qwen3-VL-Embedding that broke on the generic tokenizer path (#369 by @MasakiMu319)
- System prompt support in chat UI — Chat interface now accepts system prompts
- Clear all SSD cache button — Admin dashboard has a new button to clear all SSD cache blocks
- SSD cache size display — Shows SSD cache size even when no models are loaded
- Responsive admin dashboard — Admin dashboard now works on mobile devices
- Real-time menubar updates — macOS menubar status (Stopped → Starting → Running) and button states now update in real time while the menu is open, without needing to close and reopen (#426 by @EmotionalAmo)
- App bundle size reduction — Stripped torch, cv2, pyarrow, pandas, sympy from the app bundle (~780MB saved)
- mlx-vlm bump — Updated to v0.4.2 (7f7a04c)
- mlx-embeddings bump — Updated to v0.1.0 (32981fa)
Bug Fixes
- Fix
ContentPartlist content causing 500 error when Qwen Code CLI sends[{"type": "text", ...}]instead of string (#433 by @mbauer) - Fix prefix index storing mutable reference to
block_ids, causing cache corruption on CoW block changes (#391 by @andafterall) - Fix Anthropic
documentcontent blocks (base64 PDF) rejected by Pydantic validation (#434) - Fix "Total Tokens Processed" metric ignoring reasoning/thinking tokens — renamed to "Total Prefill Tokens" for clarity (#430)
- Fix MCP client resource leak on partial connect failure
- Fix
ValueErrorfromprocessor.apply_chat_templatein VLM engine - Fix fake
<think>tag prepended in TRACE log output - Fix VLM cache proxy using wrong offset for batched mask sizing
- Fix
specprefill_thresholdnot propagating from model_settings to scheduler - Fix
max_position_embeddingsnot detected in nestedtext_config - Fix
voiceparam not mapped toinstructfor VoiceDesign TTS models - Fix 8-bit quantization inconsistency — unified to affine/gs64 (removed mxfp8/gs32)
- Fix admin dashboard polling continuing when browser tab is hidden (#352)
- Fix
_prefix_indextype annotations to match tuple storage - Fix menubar menu status duplication and
_build_menuguard during menu open - Fix mlx-audio dependency conflicts with mlx-lm version pinning
- Fix auto-generate README when frontmatter-only stub exists
- Sync 25 stale tests with current implementation
New Contributors
- @ethannortharc — Audio integration (STT/TTS/STS) (#365)
- @leuski — XGrammar constrained decoding (#335)
- @tianfeng98 — MCP Streamable HTTP (#286)
- @MasakiMu319 — Multimodal embedding items (#373, #369)
- @mbauer — ContentPart list type error fix (#433)
- @andafterall — Prefix index mutable reference fix (#391)
- @EmotionalAmo — Menubar real-time update (#426)
Full changelog: v0.2.24...v0.3.0rc1
Contributors
Assets 4
v0.2.24
v0.2.24 Release Notes
Critical Bug Fixes
- Fix VLM loading failure on all Qwen3.5 models —
transformers5.4.0 (released March 27) rewroteQwen2VLImageProcessorfrom numpy/PIL to torch/torchvision backend, breaking VLM loading in environments without torch. Every Qwen3.5 model failed VLM init and fell back to LLM, causing double model loading and ~2x peak memory usage. Pinnedtransformers>=5.0.0,<5.4.0. (#431) - Fix IOKit kernel panic (completeMemory prepare count underflow) — Immediate
mx.clear_cache()after request completion raced with IOKit's asynchronous reference count cleanup, causing kernel panics on M1/M2/M3 devices. Deferred Metal buffer clearing by 8 generation steps to allow IOKit callbacks to complete. (#435) - Fix swap during model load with memory guard enabled —
mx.set_memory_limit()caused MLX to aggressively reclaim cached buffers during model loading, creating alloc/free churn that pushed the system into swap. Removed Metal-level memory limits entirely since all memory protection usesmx.get_active_memory()polling instead. (#429)
Bug Fixes
v0.2.23
Updating to 0.2.23 is strongly recommended. 0.2.22 contains critical bugs that cause crashes and memory issues on long context and concurrent requests. Sorry for the trouble.
v0.2.23 Release Notes
Critical Bug Fixes
- Fix Metal buffer accumulation during prefill causing crashes — 0.2.22 disabled buffer clearing between prefill chunks, causing GPU memory to build up across chunks until the Metal driver crashes. This affected all devices but was especially severe on machines with less memory. (#410, #412, #421)
- Fix TTFT spikes from stale Metal buffers between requests — Freed buffers accumulated in the Metal buffer pool across requests, forcing expensive emergency GC during the next prefill. (#411)
- Fix KVCache offset mismatch in cache reconstruction — Stored meta_state offset could exceed actual tensor length after partial prefix match, causing
broadcast_shapeserrors on hybrid attention models (Qwen3.5) at concurrency > 1. (#409)
Bug Fixes
- Fix MoE router gate quantization causing model load failure
- Fix TurboQuant KV cache conversion missing in cache-merge prefill path (#422)
- Disable experimental TurboQuant feature pending further optimization
Improvements
- oQ: Enhance bit allocation strategy
- oQ: Enable enhanced quantization for Nemotron-H models
v0.2.22
v0.2.22 Release Notes
Bug Fixes
- Fix GPU synchronization before
batch_generator.remove()in request abort path - Fix prefill performance regression from unnecessary per-chunk
_sync_and_clear_cache()calls (#396) - Fix images being stripped from Anthropic
tool_resultcontent for VLM models (#393) - Fix GPTQ axis mismatch — align dequantize-quantize grouping with
mx.quantize - Fix GPTQ
group_sizefallback crash on non-power-of-2 output dimensions - Fix accuracy benchmark forcing LM engine to avoid VLM empty responses
Improvements
- Support
x-api-keyheader for Anthropic SDK compatibility (#379) - oQ: MLP asymmetry for dense models — reduce
up_projbits while protectinggate_proj/down_proj - oQ: GPTQ performance and stability improvements, rename enhanced suffix to
e
v0.2.21
v0.2.21 Release Notes
Highlights
TurboQuant KV cache (experimental)
This is an experimental feature and may not work correctly in all scenarios.

Codebook-quantized KV cache that compresses key-value states during generation. Based on TurboQuant — random orthogonal rotation + Beta distribution codebook + boundary-based scalar quantization.
How it works: Prefill runs at full fp16 speed (no quality loss). At the first decode token, the accumulated KV cache is quantized to 3-bit or 4-bit codebook indices. Decode attention uses a fused 2-pass Flash Attention Metal kernel that reads directly from packed indices — no dequantization, no fp16 intermediate tensors.
Needle-in-Haystack (Qwen3.5-35B-A3B, 3-bit TurboQuant)
| Context | Baseline | TurboQuant | KV Memory |
|---|---|---|---|
| 32K | ✅ | ✅ | 735MB → 195MB (73%) |
| 64K | ✅ | ✅ | 1407MB → 327MB (77%) |
| 128K | ✅ | ✅ | 2749MB → 589MB (79%) |
Performance
| Model | Prefill Speed | Decode Speed |
|---|---|---|
| Qwen3.5-35B-A3B | 95% | 87% |
| Qwen3.5-27B | 97% | 95% |
Speed values are percentage of fp16 baseline performance.
Enable from admin UI → model settings → experimental features → TurboQuant KV Cache toggle.
oQe — enhanced quantization with GPTQ weight optimization
oQe adds Hessian-based GPTQ error compensation on top of oQ's sensitivity-driven mixed-precision system. Standard quantization rounds each weight independently. GPTQ processes columns sequentially and adjusts remaining weights to compensate for rounding error, guided by the inverse Hessian of calibration inputs. The result is the same mlx-lm compatible format — identical structure, identical inference speed — but with substantially lower output error.
For MoE models, routed experts (90%+ of total parameters) are processed using a batched algorithm: all experts in a layer share the same Hessian, so column-by-column optimization runs on all experts simultaneously. Qwen3.5-35B-A3B (256 experts × 40 layers): ~6 minutes vs ~90 minutes sequential (15x speedup, identical results).
Supported architectures: Qwen3.5 MoE/dense, MiniMax-M2.5, GLM, Step-3.5, Nemotron-Cascade, Llama/Mistral, VLM (vision weights kept fp16). See the oQ documentation for details.
Bug Fixes
- Fix VLM cache proxy using authoritative mx.array offset instead of unreliable _offset shortcut
- Fix monotonic _offset for BatchRotatingKVCache in VLM proxy
- Fix disk-full logging for SSD cache writes (#342)
- Fix LoRA adapter directories appearing in model discovery and admin downloads (#356)
- Fix generation memory guard with Metal cache cleanup on OOM failure (#372)
- Fix function_call_output accepting list/dict and serializing to JSON string (#367)
- Fix download popup menu z-index in accuracy benchmark UI (#370)
- Fix oq_calibration_data.json missing from package data (#374)
- Fix merge chat_template_kwargs in eval to prevent duplicate kwarg error
- Fix TemplateResponse calls for Starlette 1.0 compatibility (#351)
- Fix homebrew formula HEAD install support
Full changelog: v0.2.20...v0.2.21
v0.2.20
Highlights
oQ — oMLX universal dynamic quantization
Quantization should not be exclusive to any particular inference server. oQ produces standard mlx-lm compatible models that work everywhere — oMLX, mlx-lm, and any app that supports MLX safetensors. No custom loader required.
oQ is a data-driven mixed-precision quantization system for Apple Silicon. Instead of assigning bits by fixed rules or tensor type, oQ measures each layer's actual quantization sensitivity through calibration and allocates bits where the data says they matter most. See the oQ documentation for details.
Benchmarks (Qwen3.5-35B-A3B)
| Benchmark | Samples | 2-bit mlx-lm | 2-bit oQ | 3-bit mlx-lm | 3-bit oQ | 4-bit mlx-lm | 4-bit oQ |
|---|---|---|---|---|---|---|---|
| MMLU | 300 | 14.0% | 64.0% | 76.3% | 85.0% | 79.7% | 83.3% |
| TRUTHFULQA | 300 | 17.0% | 80.0% | 81.7% | 86.7% | 87.7% | 88.0% |
| HUMANEVAL | 164 (full) | 0.0% | 78.0% | 84.8% | 86.6% | 87.2% | 85.4% |
| MBPP | 300 | 0.3% | 63.3% | 69.0% | 72.0% | 71.7% | 74.3% |
- oQ2-oQ8 levels with sensitivity-driven mixed-precision bit allocation
- oQ3.5 base 3-bit + routed expert down_proj 4-bit (Super Weights protection)
- AWQ weight equalization rewritten from scratch following the llm-compressor reference implementation. fixed critical double-scaling bug on hybrid attention models (Qwen3.5) and added per-layer mask-aware calibration
- Sensitivity-driven budget plan. mandatory lm_head 8-bit protection, then data-driven tier allocation (+4/+2/+1 bits) with greedy fallback. no hardcoded tensor-type priorities — calibration data decides which layers matter
- Proxy sensitivity model. select a quantized version of the source model for layer sensitivity analysis with ~4x less memory. 90% top-10 overlap with full-precision measurement validated on Qwen3.5-35B
- New calibration dataset. 600 samples from codeparrot/self-instruct-starcoder (real code), allenai/c4 (web text), Open-Orca (conversation), gsm8k (reasoning), and wikipedia multilingual. replaces the old HumanEval/MBPP-only code samples
- VLM support. quantize vision-language models with vision weight preservation (fp16)
- FP8 model support. use native FP8 models (MiniMax, DeepSeek) as quantization source
- MiniMax M2.5 support. block_sparse_moe architecture with SwitchGLU fused experts
- DeepSeek V3.2 support. shared_experts (plural) + MLA projections. MLP AWQ works, MLA attention AWQ planned
- Nemotron support. backbone.embeddings path detection for sensitivity measurement on hybrid Mamba+MoE+Attention architecture
- AWQ grid size setting. configurable n_grid (10 fast / 20 recommended) from the web UI
- HuggingFace Hub uploader. upload quantized models directly from the dashboard
- blocks inference requests during quantization to prevent conflicts
Intelligence benchmark suite
Evaluate model intelligence across knowledge, reasoning, math, and coding benchmarks. All datasets bundled locally for offline use.
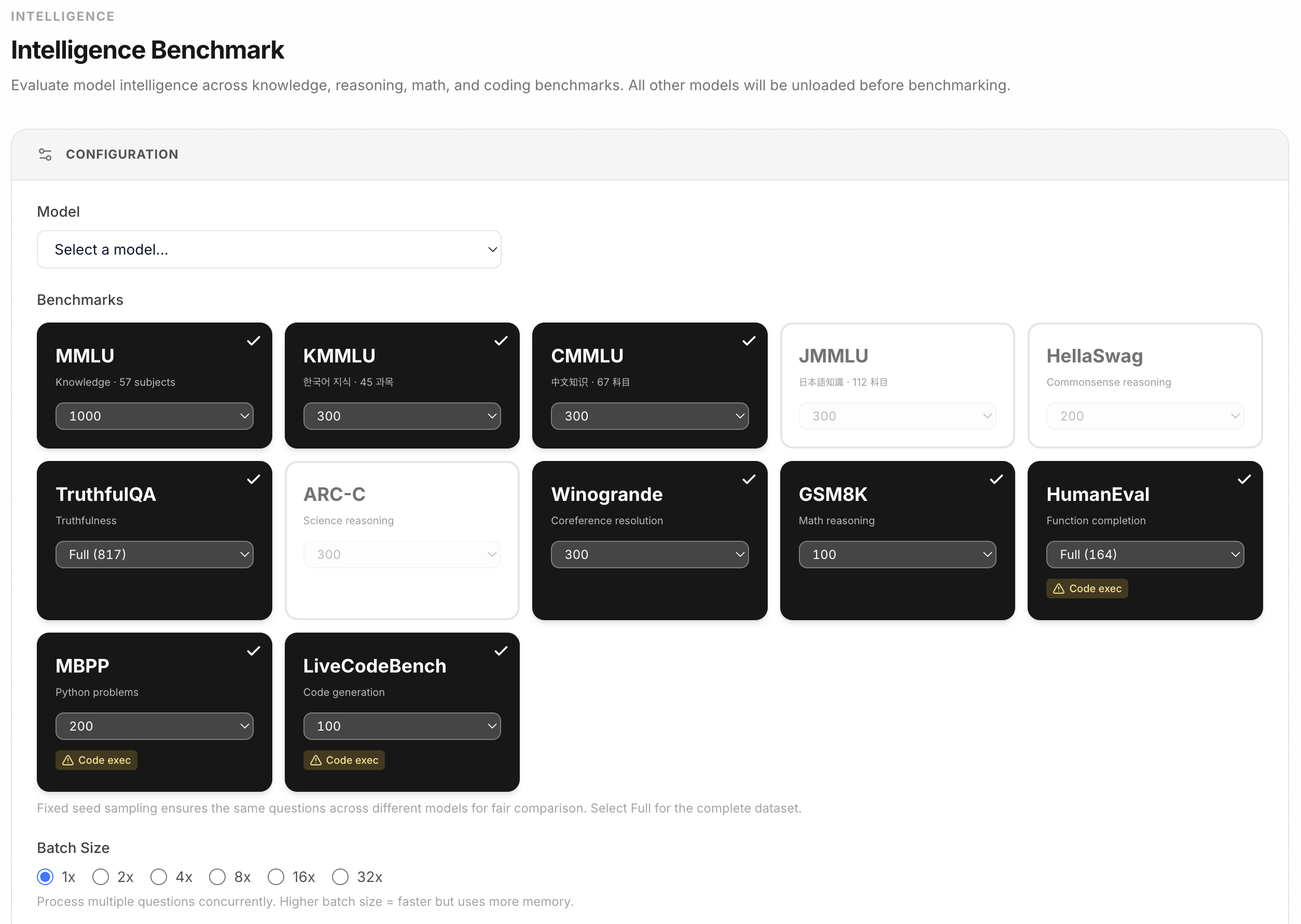
- Knowledge: MMLU, ARC-Challenge, KMMLU (Korean), CMMLU (Chinese), JMMLU (Japanese)
- Reasoning: HellaSwag, Winogrande, TruthfulQA, GSM8K
- Coding: HumanEval (164 function completions, pass@1), MBPP
- benchmark queue for sequential multi-model evaluation with persistent results
- comparison table with mode/sample columns and text export
- sample size options: 30/50/100/200/300/500/1000/2000/Full
- batch processing: 1x/2x/4x/8x/16x/32x
- download raw results as JSON
New Features
- Prefill memory guard. prevents kernel panics on large context by detecting head_dim>128 O(n^2) SDPA fallback and enforcing safe prefill chunk sizes
- Native BERT/XLMRoBERTa embedding. load BERT-family embedding models (bge-m3, mxbai-embed) without mlx-embeddings fallback (#330 by @yes999zc)
- Jina v3 reranker. reranking via
<|score_token|>logits for jinaai/jina-reranker-v3-mlx (#331 by @yes999zc) - Partial mode. assistant message prefill support for Moonshot/Kimi K2 models (
partialfield +namefield passthrough) (#306 by @blightbow) - Codex smart config merging. non-destructive config merge with reasoning model auto-detection (#249 by @JasonYeYuhe)
- i18n normalization. normalize translation files against en.json with missing key detection (#247 by @xiaoran007)
- Web dashboard generating status. show generating status for active requests after prefill completes
Experimental Features
- SpecPrefill. attention-based sparse prefill for MoE models. reduces prefill compute by skipping low-attention tokens. system prompt is protected from token dropping to preserve instruction following.
Bug Fixes
- Fix lucide icon rendering race condition with Alpine.js microtask
- Fix chat streaming failure not sending error message to client (#342)
- Fix TTL auto-unload during benchmark causing Metal GPU crash
- Fix MC benchmarks (MMLU, HellaSwag, TruthfulQA) always scoring 0% due to max_tokens=1
- Fix HumanEval scoring. prepend prompt imports when model returns function only
- Fix MBPP scoring. include test cases in prompt so model uses correct function name
- Fix benchmark code extraction. extract last answer/code block instead of first
- Fix benchmark penalties. force neutral presence_penalty=0 and repetition_penalty=1
- Fix think prefix false positive for disabled thinking patterns (
<think></think>) - Fix responses API image support for VLM + missing prompt_tokens in completions usage
- Fix SSE streaming behind nginx reverse proxy (X-Accel-Buffering header) (#309)
- Fix CausalLM-based embedding model detection (Qwen3-Embedding) (#327)
- Fix web dashboard unload tooltip clipping in active models box (#314)
- Fix web dashboard 401 warning log spam from dashboard polling
- Fix web dashboard model settings not showing for embedding/reranker models
- Fix PEP 735 dependency-groups for
uv sync --dev(#305 by @blightbow)
New Contributors
- @blightbow made their first contribution in #305
- @yes999zc made their first contribution in #330
- @JasonYeYuhe made their first contribution in #249
- @xiaoran007 made their first contribution in #247
Full changelog: v0.2.19...v0.2.20
Contributors
Assets 4
v0.2.20rc1
This is a release candidate for v0.2.20. Please test and report any issues before the final release.
Highlights
oQ — oMLX universal dynamic quantization
Quantize any model directly from the web dashboard. oQ produces standard mlx-lm compatible models that work everywhere, no custom loader required. oMLX, mlx-lm, and any app that supports MLX safetensors format.
oQ analyzes weight distributions per-layer and applies the optimal quantization format (mxfp4, mxfp8, affine) automatically. See the oQ documentation for details.
- oQ2-oQ8 levels with calibration datasets and CLIP-based evaluation
- oQ3.5 base 3-bit + expert down_proj 4-bit (~3.9 bpw)
- Hybrid quantization per-layer mxfp4/mxfp8/affine format selection for better quality-size tradeoffs
- AutoAWQ weight equalization with per-expert scaling and data-driven sensitivity analysis for improved accuracy
- VLM support. Quantize vision-language models with vision weight preservation
- FP8 model support. Use native FP8 models (MiniMax, DeepSeek) as quantization source
- Clip optimization speedup with GPU batch size setting for faster AWQ-style clipping
- Blocks inference requests during quantization to prevent conflicts
Intelligence benchmark suite
Evaluate model intelligence across knowledge, reasoning, math, and coding benchmarks. All datasets bundled locally for offline use.
- Knowledge: MMLU, ARC-Challenge, KMMLU (Korean), CMMLU (Chinese), JMMLU (Japanese)
- Reasoning: HellaSwag, Winogrande, TruthfulQA, GSM8K
- Coding: HumanEval (164 function completions, pass@1), MBPP
- Benchmark queue for sequential multi-model evaluation with persistent results
- Comparison table with mode/sample columns and text export
- Sample size options: 30/50/100/200/300/500/1000/2000/Full
- Batch processing: 1x/2x/4x/8x/16x/32x
- Download raw results as JSON
New Features
- Prefill memory guard. Prevents kernel panics on large context by detecting head_dim>128 O(n²) SDPA fallback and enforcing safe prefill chunk sizes
- Native BERT/XLMRoBERTa embedding. Load BERT-family embedding models (bge-m3, mxbai-embed) without mlx-embeddings fallback (#330 by @yes999zc)
- Jina v3 reranker. Reranking via
<|score_token|>logits for jinaai/jina-reranker-v3-mlx (#331 by @yes999zc) - Partial mode. Assistant message prefill support for Moonshot/Kimi K2 models (
partialfield +namefield passthrough) (#306 by @blightbow) - Codex smart config merging. Non-destructive config merge with reasoning model auto-detection (#249 by @JasonYeYuhe)
- i18n normalization. Normalize translation files against en.json with missing key detection (#247 by @xiaoran007)
- Web dashboard generating status. Show generating status for active requests after prefill completes
Experimental Features
- SpecPrefill. Attention-based sparse prefill for MoE models. Reduces prefill compute by skipping low-attention tokens. System prompt is protected from token dropping to preserve instruction following.
Bug Fixes
- Fix chat streaming failure not sending error message to client (#342)
- Fix TTL auto-unload during benchmark causing Metal GPU crash
- Fix dtype normalization on enhanced path causing OOM on large models
- Fix oQ bf16→fp16 weight conversion causing 41% quantized value corruption
- Fix oQ mxfp4 uint8 scales being force-cast to fp16
- Fix oQ clip optimization mask dtype and position_ids for Qwen3.5
- Fix oQ streaming quantization accuracy and VLM support
- Fix MC benchmarks (MMLU, HellaSwag, TruthfulQA) always scoring 0% due to max_tokens=1
- Fix HumanEval scoring. Prepend prompt imports when model returns function only
- Fix MBPP scoring. Include test cases in prompt so model uses correct function name
- Fix benchmark code extraction. Extract last answer/code block instead of first
- Fix benchmark penalties. Force neutral presence_penalty=0 and repetition_penalty=1
- Fix think prefix false positive for disabled thinking patterns (
<think></think>) - Fix responses API image support for VLM + missing prompt_tokens in completions usage
- Fix SSE streaming behind nginx reverse proxy (X-Accel-Buffering header) (#309)
- Fix CausalLM-based embedding model detection (Qwen3-Embedding) (#327)
- Fix web dashboard unload tooltip clipping in active models box (#314)
- Fix web dashboard 401 warning log spam from dashboard polling
- Fix web dashboard model settings not showing for embedding/reranker models
- Fix PEP 735 dependency-groups for
uv sync --dev(#305 by @blightbow)
New Contributors
- @blightbow made their first contribution in #305
- @yes999zc made their first contribution in #330
- @JasonYeYuhe made their first contribution in #249
- @xiaoran007 made their first contribution in #247
Full changelog: v0.2.19...v0.2.20rc1
Contributors
Assets 4
v0.2.20.dev3
This is a pre-release build for testing purposes.
New Features
- Native BERT/XLMRoBERTa embedding — load BERT-family embedding models (bge-m3, mxbai-embed) without mlx-embeddings fallback (#330 by @yes999zc)
- Jina v3 reranker — reranking via
<|score_token|>logits for jinaai/jina-reranker-v3-mlx (#331 by @yes999zc) - oQ3.5 quantization level — base 3-bit + expert down_proj 4-bit (~3.9 bpw)
- oQ VLM support — quantize vision-language models with vision weight preservation
- oQ FP8 model support — allow native FP8 models (MiniMax, DeepSeek) as quantization source
- Partial mode — assistant message prefill support for Moonshot/Kimi K2 models (
partialfield +namefield passthrough) (#306 by @blightbow) - Benchmark sample sizes — add 500/1000/2000 sample options for MMLU and HellaSwag
- Benchmark comparison columns — show mode/sample and full dataset size in comparison table
- Codex smart config merging — non-destructive config merge with reasoning model auto-detection (#249 by @JasonYeYuhe)
- i18n normalization — normalize translation files against en.json with missing key detection (#247 by @xiaoran007)
- Admin generating status — show generating status for active requests after prefill completes
Bug Fixes
- fix oQ bf16→fp16 weight conversion causing 41% quantized value corruption
- fix oQ mxfp4 uint8 scales being force-cast to fp16
- fix oQ clip optimization mask dtype and position_ids for Qwen3.5
- fix think prefix false positive for disabled thinking patterns (
<think></think>) - fix responses API image support for VLM + missing prompt_tokens in completions usage
- fix SSE streaming behind nginx reverse proxy (X-Accel-Buffering header) (#309)
- fix CausalLM-based embedding model detection (Qwen3-Embedding) (#327)
- fix admin unload tooltip clipping in active models box (#314)
- fix admin 401 warning log spam from dashboard polling
- fix admin model settings not showing for embedding/reranker models
- fix PEP 735 dependency-groups for
uv sync --dev(#305 by @blightbow)
New Contributors
- @blightbow made their first contribution in #305
- @yes999zc made their first contribution in #330
- @JasonYeYuhe made their first contribution in #249
- @xiaoran007 made their first contribution in #247
Contributors
Assets 4
v0.2.20.dev2
This is a pre-release build for testing purposes.
New Features
- Hybrid quantization modes — per-layer mxfp4/mxfp8/affine format selection for better quality-size tradeoffs
- Clip optimization speedup — GPU batch size setting for faster AWQ-style clipping
- Block inference during quantization — prevents request conflicts while oQ is running
- Download raw results — export benchmark results as JSON
- Use model sampling settings — benchmarks now respect per-model sampling parameters
Bug Fixes
- fix MC benchmarks (MMLU, HellaSwag, TruthfulQA) always scoring 0%
v0.2.20.dev1
This is a pre-release build for testing purposes. Detailed feature breakdowns will be included in the official release notes. Please test extensively and report any issues.
New Features
- oQ Quantization — oMLX Universal Dynamic Quantization with oQ2-oQ8 levels, calibration datasets, and CLIP support
- Accuracy Benchmark — evaluate model intelligence with MMLU, HellaSwag, TruthfulQA, GSM8K, and LiveCodeBench. all datasets bundled locally for offline use. card-style grid UI with per-benchmark sample size selector (30/50/100/200/300/Full) and batch processing (1x/2x/4x/8x)
- Benchmark Queue — queue multiple models for sequential benchmarking. results persist on the server until explicitly cleared. comparison table in text export for easy cross-model analysis
- SpecPrefill — attention-based sparse prefill for MoE models. reduces prefill compute by skipping low-attention tokens while preserving output quality
- Prefill Memory Guard — prevents kernel panics on large context by detecting head_dim>128 O(n²) SDPA fallback and enforcing safe prefill chunk sizes
- MLX Only filter in model downloader — toggle to show only MLX-converted models
- Admin override for OCR model sampling params — prevent repetition loops on OCR models
Bug Fixes
- fix anthropic API temperature default (should be None, not 1.0)