Releases: jundot/omlx
v0.2.10
If you're on an M5 Mac, download the
macos26-tahoeDMG for full performance. themacos15-sequoiabuild does not include M5 acceleration.
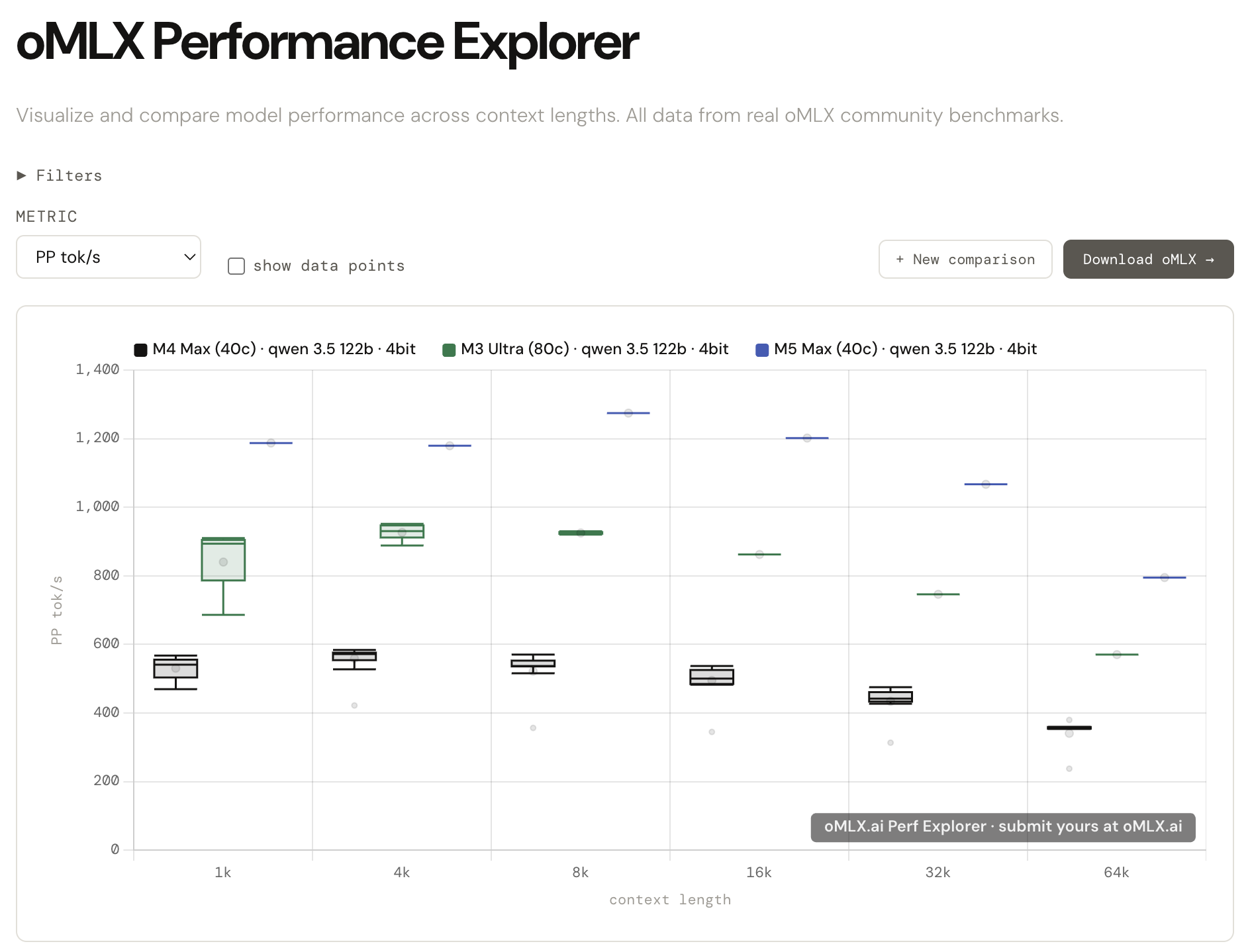
Introducing oMLX.ai Performance Explorer
All those benchmarks you've been running from the admin dashboard? Nearly 10,000 runs have been submitted by the community so far, and the data is now live at oMLX.ai.
Compare your results side by side across different Apple Silicon configs — M1 through M5, different quantizations, different context lengths. The kind of comparison that used to mean digging through scattered reddit posts and old GitHub threads.
Here's a sample comparison: https://omlx.ai/c/jmxd8a4
Every benchmark you submit makes the dataset more reliable for everyone. Submission is built into the oMLX admin dashboard and takes about 30 seconds.
New Features (v0.2.10)
Reload models from admin dashboard (#55)
- added reload button in the Model Manager tab that re-scans model directories and re-applies model settings (pinned, default, aliases) without restarting the server. requested by users managing oMLX on remote devices over the local network.
Update available indicator in admin navbar
- added hourly GitHub release check with a green dot next to the version number when a newer release exists. clicking it links to the release page.
Traditional Chinese (zh-TW) locale (PR #178)
- added zh-TW locale with 470 translation keys using standard Taiwan terminology. includes Noto Sans TC font and language selector update.
Bug Fixes (v0.2.10)
Model alias not recognized with provider prefix (#189)
- fixed external apps (OpenCode, OpenClaw, Codex) sending model names with a provider prefix (e.g.
omlx/my-model) failing to match. the server now strips the prefix and retries alias lookup. error messages also show aliases instead of raw directory names.
8GB RAM devices unable to load any model (#137)
- fixed
max_model_memory: autoreserving a fixed 8GB for the system, leaving 0 bytes usable on 8GB devices. switched to adaptive percentage-based reservation so small-memory devices can still load models.
Embedding/reranker segfault under concurrent load
- fixed Metal command buffer races when embedding or reranker inference ran concurrently with LLM generation. MLX GPU ops for embedding/reranker engines are now serialized onto the global executor thread.
Other fixes
- fixed menubar "Update Available" item not appearing until menu happened to rebuild (PR #181)
- fixed unclear error message when safetensors files are missing for embedding/reranker models
full changelog: v0.2.9...v0.2.10
New Contributors
- @JianShan-1214 made their first contribution in PR #178
Thanks to @JianShan-1214 and @kuanjames for their contributions!
Contributors
Assets 4
v0.2.9
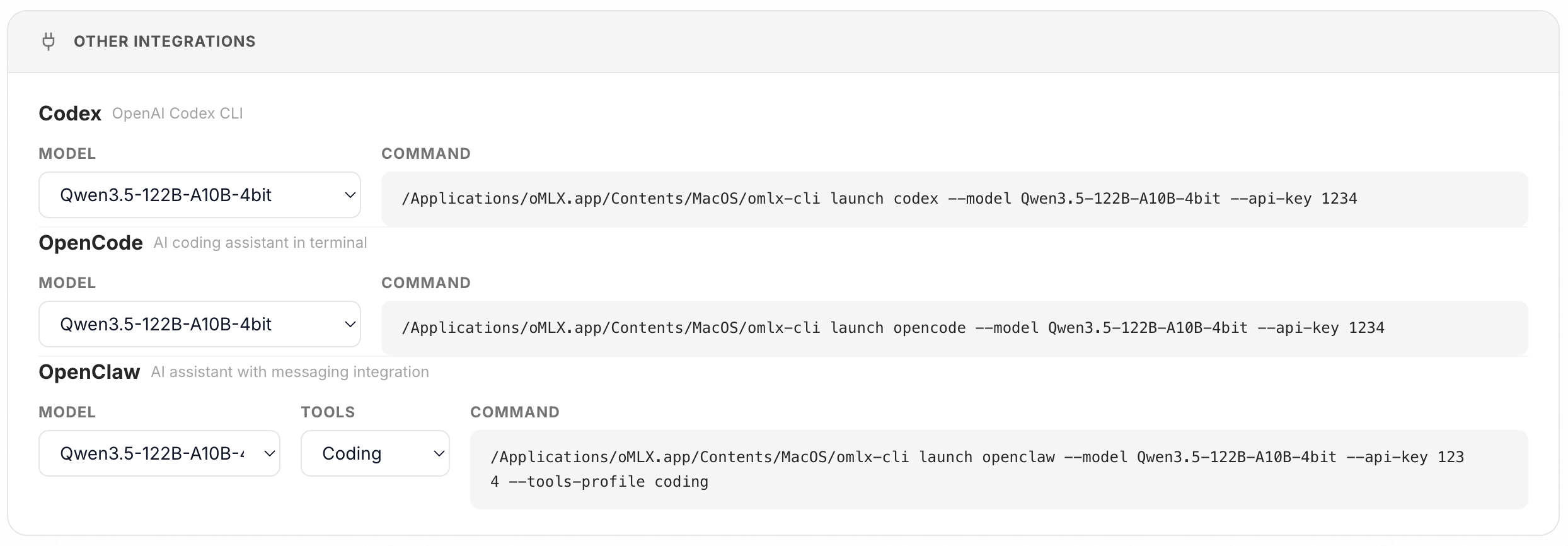
Highlight: one-click integrations for OpenClaw, OpenCode, and Codex + M5 Neural Accelerator support
- you can now set up OpenClaw, OpenCode, and Codex from the oMLX admin dashboard with a single click and paste. no more manual config editing.
- M5 Neural Accelerator support added. if you're on an M5 Mac, download the
macos26-tahoeDMG for full performance. themacos15-sequoiabuild does not include M5 acceleration.
New Features (v0.2.9)
Qwen3-Reranker support (PR #165)
- added CausalLM-based reranker support for Qwen3-Reranker family models. uses yes/no logit scoring, auto-detected by architecture + directory name, loaded via mlx-lm.
Bug Fixes (v0.2.9)
Codex agentic coding stops mid-session
- fixed Responses API input converter creating duplicate assistant messages per tool-call round, causing models to output EOS after several rounds. assistant message and tool_calls are now merged into a single turn.
Tool-call streaming markup leakage (follow-up)
- fixed additional edge cases where tool-call envelope markup (
[Tool call: ...]) leaked as literal text during streaming. covers bracket prefix sanitizer for multi-prefix detection, unresolved bracket prefix leakage, and mixed bracket marker scenarios (#172, PR #174)
Other fixes
- fixed menubar app now resolves host/port from settings instead of hardcoding
- fixed built-in chat now uses the configured default model instead of the first model in the list (#168)
- fixed model download stall detection with mtime tracking and sequential queue
- added
--macos-targetbuild flag for platform-specific mlx wheel swapping
full changelog: v0.2.8...v0.2.9
New Contributors
- @shyuan made their first contribution in #165
- @jwcrystal made their first contribution in #168
Thanks to @shyuan, @jwcrystal, and @lyonsno for their contributions!
Contributors
Assets 4
v0.2.8
Highlight: one-click integrations for OpenClaw, OpenCode, and Codex + M5 Neural Accelerator support
- You can now set up OpenClaw, OpenCode, and Codex from the oMLX admin dashboard with a single click and paste. no more manual config editing.
- M5 Neural Accelerator support added. if you're on an M5 Mac, download the
macos26-tahoeDMG for full performance. themacos15-sequoiabuild does not include M5 acceleration.
Critical bug fixes
- Claude Code tool call markup leakage - streamed tool-call envelopes (
[Tool call: ...]) no longer leak as literal text or cause conversation stalls mid-coding. covers both OpenAI and Anthropic paths (#159, PR #140) - Garbled output on second request - when the first request included images and the second request was longer, positional encoding state from the previous request would corrupt the output. fixed by clearing mRoPE position state between sequential prefills (#131)
What's new
- OpenClaw, OpenCode, Codex one-click integrations - configure and launch external AI coding tools directly from the admin dashboard (#145)
- OpenAI Responses API endpoint - added
/v1/responsesfor broader API compatibility (#138) - Sub key (additional API key) support - multiple API keys for shared server access (PR #147)
- Download resume and retry - model downloads now support resuming from where they left off (#156)
- Favicon for admin page (#164)
- Chat sidebar logo links to dashboard
- Widen Codex/OpenCode model selector in integrations UI for better readability
Bug fixes
- Chat UI rendering issues in dark/light mode (#143)
- Thinking block elapsed time - now shows the actual thinking duration instead of incorrect values (#161)
- SSD cache slider - percentage calculation now uses total disk capacity instead of free space (#162)
- Model directory pointing directly at a model folder - previously failed to detect the model (PR #150)
- Version comparison crash on PEP 440 beta versions (e.g.
0.2.8b1) - Startup crash detection and ProcessLookupError in menubar app server stop
- Homebrew build - pydantic-core now builds from source to prevent dylib fixup failure
v0.2.7
What's New
Features
- HuggingFace mirror endpoint support: configure a custom HF mirror endpoint for regions with restricted access to huggingface.co. applies to model downloads, search, and all Hub API calls. (#116)
- Dashboard tab persistence: selected dashboard tabs are now persisted in URL query params, so refreshing the page or sharing a link keeps your current view. (#129)
- Extended metrics reference: batch size, speedup ratio, and per-request prefill TPS added to the metrics reference panel. (#101)
- mlx-lm upgraded to v0.31.1: updated to commit 4a21ffd for latest model support and bug fixes.
Bug Fixes
- Streaming with tool calls: content is now streamed token-by-token even when tools are present, instead of buffering the entire response. (#103)
- Model alias settings lookup: per-model settings (temperature, max tokens, etc.) now correctly resolve model aliases before lookup. (#117)
- Cache corruption infinite loop: cache corruption during prefill no longer causes an infinite retry loop. the corrupted cache is cleared and prefill restarts cleanly.
- Requests dict leak on cache failure:
fail_all_requestsno longer triggers a full cache reset, and properly cleans up the requests dictionary. - HuggingFace API timeouts: added timeouts to all HuggingFace Hub API calls to prevent the server from freezing when HF is unreachable. (#124)
- Qwen3/Gemma3 misidentified as embedding models: LLMs with certain architectures were incorrectly classified as embedding models. (#130)
- macOS 15.0+ requirement enforced: MLX >= 0.29.2 requires macOS 15.0 (Sequoia). the app now checks and enforces this at startup. (#125)
- i18n language setting not persisting: language setting selected before server init was lost after initialization. (#119)
- Anthropic tool-call filtering: added fallback safety for edge cases in Anthropic adapter tool-call handling.
Documentation
- Multilingual README: added Chinese, Korean, and Japanese translations.
New Contributors
- @TipKnuckle made their first contribution in #103
- @jonsnowljs made their first contribution in #129
Thanks to @TipKnuckle, @jonsnowljs, and @rsnow for their contributions!
Contributors
Assets 3
v0.2.6
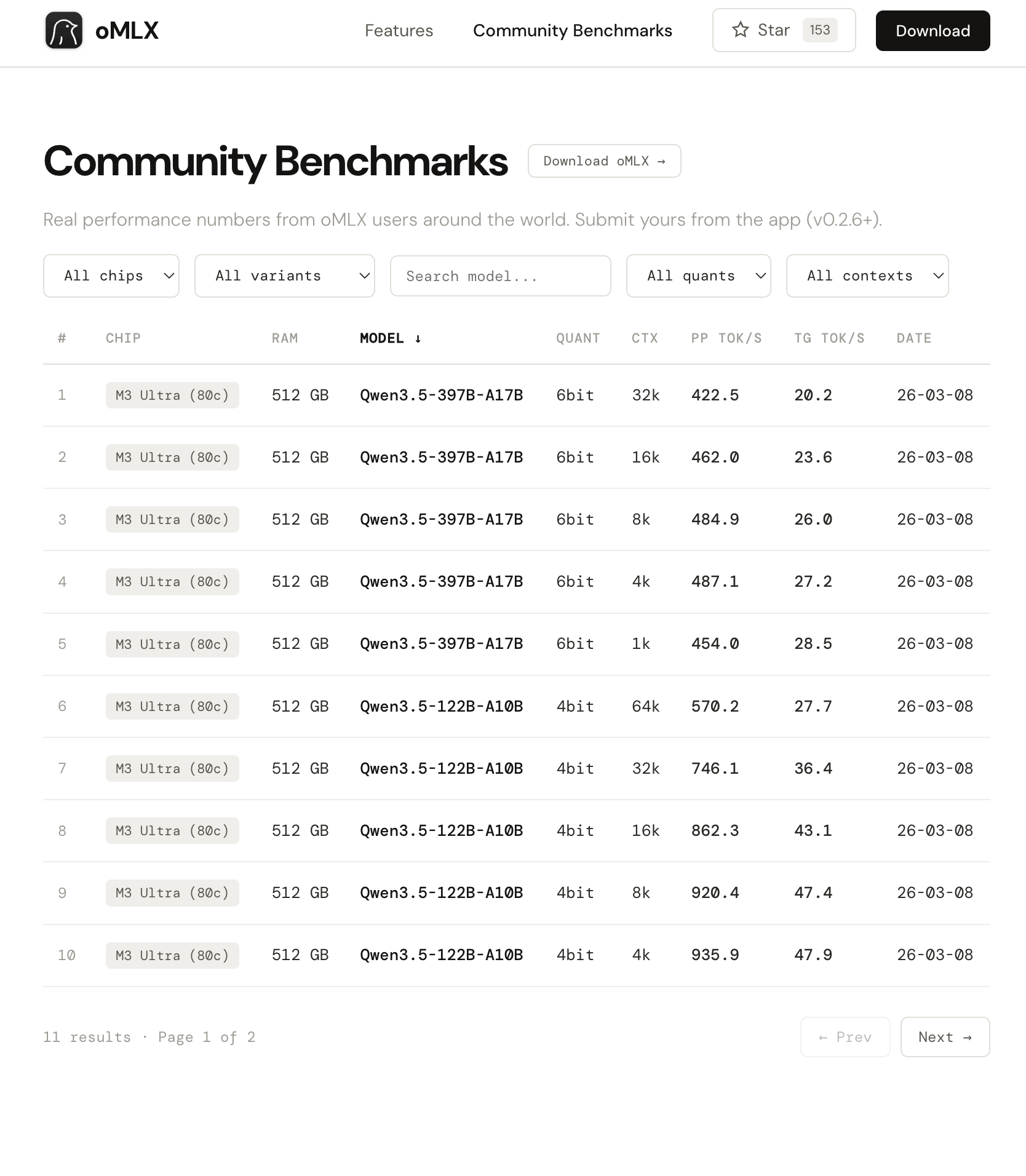
Highlight: introducing oMLX.ai community benchmarks
Every Mac, every model — all benchmarks at a glance.
oMLX.ai is now live with a community benchmark board. starting from v0.2.6, you can share your benchmark results directly from the admin dashboard and compare performance across different Macs and models. check it out at oMLX.ai!
What's new
- Community benchmark integration — benchmark results from the admin dashboard can be shared to oMLX.ai. your unique device ID links to your submissions page for easy management
Bug fixes
- Status page API endpoints now reflect configured host — previously always showed
localhosteven when a custom IP was set in server settings (#98)
v0.2.5
What's New
Features
- Presence penalty & min_p sampling: added
presence_penaltyandmin_pas new sampling parameters for finer control over generation behavior. configurable per-model from the admin panel's model settings. (#94)
Bug Fixes
- Metal crash on concurrent add_request: serialized
add_requestcalls through the MLX executor to prevent Metal GPU crashes under concurrent request submission. (#95) - HuggingFace model search broken: removed deprecated
directionparameter fromhuggingface_hub.list_models()that was silently breaking model search results.
Dependencies
- mlx-vlm updated to 348466f: adds support for new VLM model types (MiniCPM-O, Phi-4-reasoning-vision, Phi-4-Multimodal) and includes various bug fixes. oMLX's model discovery and vision input pipeline updated accordingly.
Thanks to @rsnow for reporting the Metal crash issue!
Contributors
Assets 3
v0.2.4
What's New
Features
- Skip API key verification (localhost): when the server is bound to localhost, you can now disable API key verification for all API endpoints from global settings. makes local-only workflows frictionless, no more dummy keys needed. the option automatically resets when switching to a public host. (#92)
- Model alias: set a custom API-visible name for any model via the model settings modal.
/v1/modelsreturns the alias instead of the directory name, and requests accept both the alias and the original name. useful when switching between inference providers without reconfiguring clients. (#92) - Version display: the CLI now shows the version in the startup banner, and the admin navbar displays the running version. (#90)
Bug Fixes
- Loaded model lost after re-discovery: deleting a model or changing settings triggered model re-discovery, which dropped already-loaded engines from the pool. loaded models now preserve their runtime state across re-discovery. (#89)
- Text-only VLM quant misdetection: text-only quantizations of natively multimodal models (e.g. Qwen 3.5 122B converted via
mlx_lm.convert) were misdetected as VLM, causing a failed load attempt on every restart. now correctly classified as LLM whenvision_configis absent. (#84) - SSD cache utilization over 100%: cache utilization could exceed 100% when available disk space shrank after initial calculation. now clamped properly.
- Reasoning model output token caching: output tokens from reasoning models (with
<think>tags) were being cached unnecessarily. now skipped to avoid polluting the prefix cache.
UI Improvements
- Model settings modal reordered: alias / model type / ctx window / max tokens / temperature / top p / top k / rep. penalty / ttl / load defaults
- Alias badge shown next to model name in both model settings list and model manager
New Contributors
Thanks to @rsnow for the contribution!
Contributors
Assets 3
v0.2.3.post4
Hotfix: Fix crash when running multiple models simultaneously
Fixed a bug where the server process terminates when two or more models receive requests at the same time.
Symptom: Server crashes when multiple models are used concurrently (e.g., VLM as interface model + LLM for chat in Open WebUI)
Cause: Each model engine ran GPU operations on a separate thread, causing Metal command buffer races on Apple Silicon
Fix: All model GPU operations now run on a single shared thread. No impact on single-model performance.
v0.2.3.post3
Hotfix
Bug fixes
- Fix VLM concurrent request GPU race condition causing TransferEncodingError and server crash (#80)
- Remove
mx.clear_cache()from event loop thread to prevent Metal GPU contention with_mlx_executorduring concurrent VLM requests - Always synchronize
generation_streamon request completion regardless of cache setting (previously skipped when oMLX cache was disabled) - Add
clear_pending_embeddings()to normal completion path for consistency with abort path
- Remove
v0.2.3.post2
Hotfix
Bug fixes
- Fix VLM multi-request blocking: second request now starts immediately instead of waiting for the first to finish
- Fix segfault when sending concurrent VLM image requests by ensuring all scheduler steps run on the MLX executor thread (#81)
- Fix missing mcp package crash on server start
- Fix memory limit UI showing incorrect label when set to 0