v0.2.10
If you're on an M5 Mac, download the
macos26-tahoeDMG for full performance. themacos15-sequoiabuild does not include M5 acceleration.
Introducing oMLX.ai Performance Explorer
All those benchmarks you've been running from the admin dashboard? Nearly 10,000 runs have been submitted by the community so far, and the data is now live at oMLX.ai.
Compare your results side by side across different Apple Silicon configs — M1 through M5, different quantizations, different context lengths. The kind of comparison that used to mean digging through scattered reddit posts and old GitHub threads.
Here's a sample comparison: https://omlx.ai/c/jmxd8a4
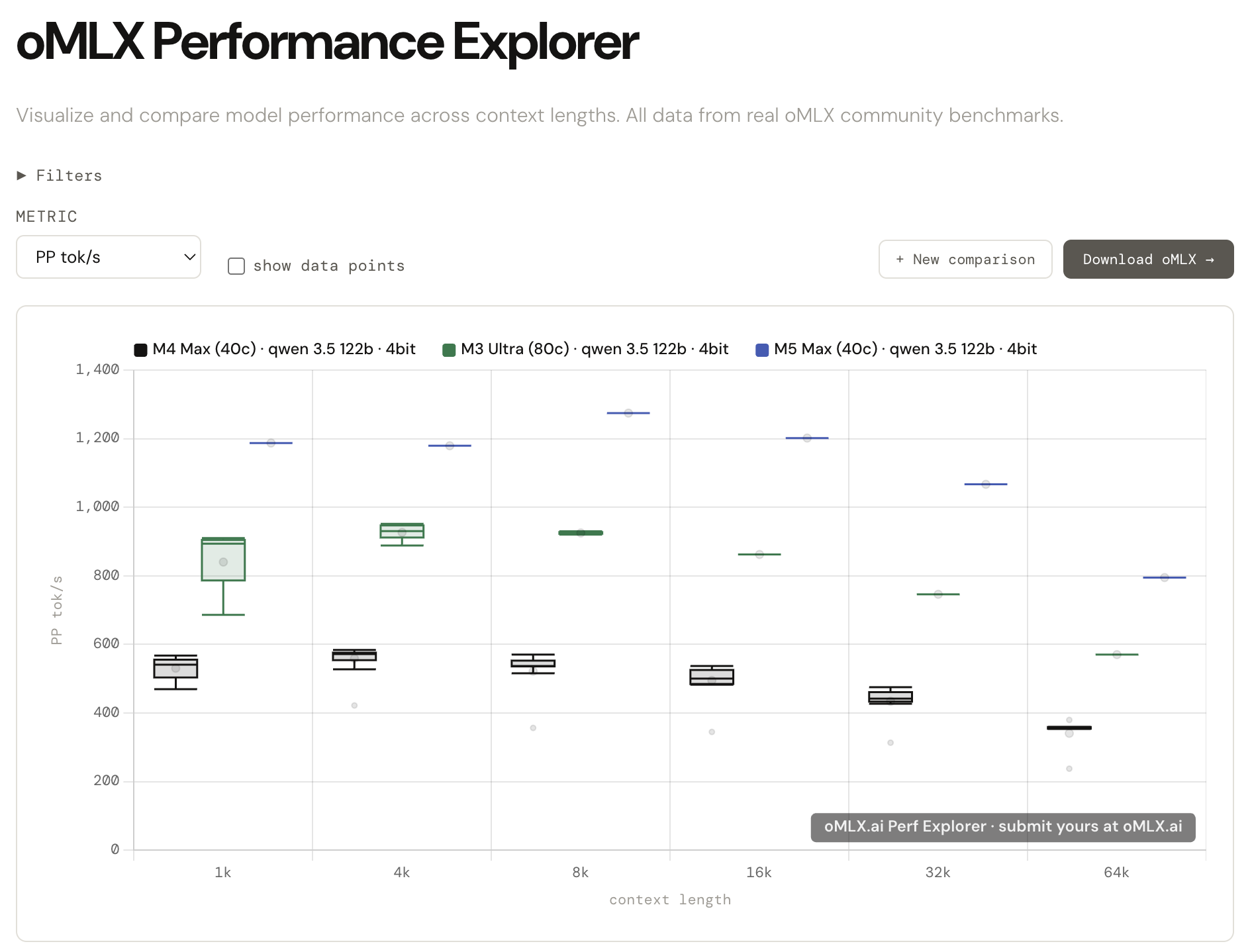
Every benchmark you submit makes the dataset more reliable for everyone. Submission is built into the oMLX admin dashboard and takes about 30 seconds.
New Features (v0.2.10)
Reload models from admin dashboard (#55)
- added reload button in the Model Manager tab that re-scans model directories and re-applies model settings (pinned, default, aliases) without restarting the server. requested by users managing oMLX on remote devices over the local network.
Update available indicator in admin navbar
- added hourly GitHub release check with a green dot next to the version number when a newer release exists. clicking it links to the release page.
Traditional Chinese (zh-TW) locale (PR #178)
- added zh-TW locale with 470 translation keys using standard Taiwan terminology. includes Noto Sans TC font and language selector update.
Bug Fixes (v0.2.10)
Model alias not recognized with provider prefix (#189)
- fixed external apps (OpenCode, OpenClaw, Codex) sending model names with a provider prefix (e.g.
omlx/my-model) failing to match. the server now strips the prefix and retries alias lookup. error messages also show aliases instead of raw directory names.
8GB RAM devices unable to load any model (#137)
- fixed
max_model_memory: autoreserving a fixed 8GB for the system, leaving 0 bytes usable on 8GB devices. switched to adaptive percentage-based reservation so small-memory devices can still load models.
Embedding/reranker segfault under concurrent load
- fixed Metal command buffer races when embedding or reranker inference ran concurrently with LLM generation. MLX GPU ops for embedding/reranker engines are now serialized onto the global executor thread.
Other fixes
- fixed menubar "Update Available" item not appearing until menu happened to rebuild (PR #181)
- fixed unclear error message when safetensors files are missing for embedding/reranker models
full changelog: v0.2.9...v0.2.10
New Contributors
- @JianShan-1214 made their first contribution in PR #178
Thanks to @JianShan-1214 and @kuanjames for their contributions!