v0.2.9
Highlight: one-click integrations for OpenClaw, OpenCode, and Codex + M5 Neural Accelerator support
- you can now set up OpenClaw, OpenCode, and Codex from the oMLX admin dashboard with a single click and paste. no more manual config editing.
- M5 Neural Accelerator support added. if you're on an M5 Mac, download the
macos26-tahoeDMG for full performance. themacos15-sequoiabuild does not include M5 acceleration.
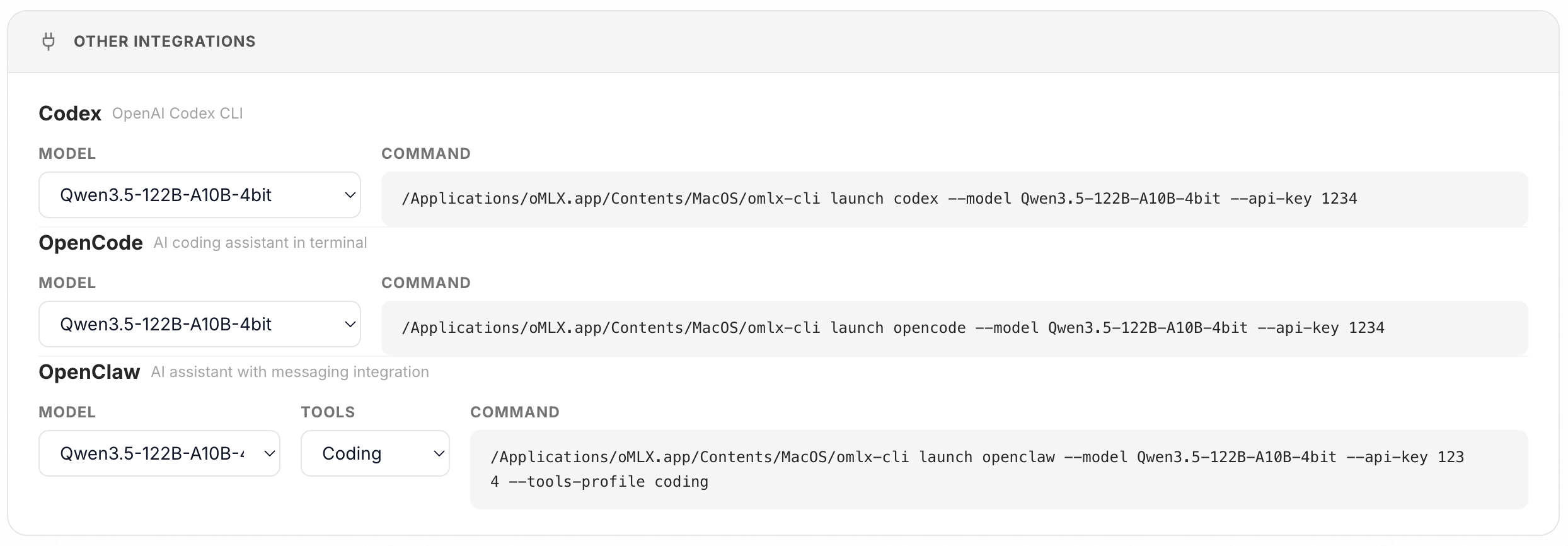
New Features (v0.2.9)
Qwen3-Reranker support (PR #165)
- added CausalLM-based reranker support for Qwen3-Reranker family models. uses yes/no logit scoring, auto-detected by architecture + directory name, loaded via mlx-lm.
Bug Fixes (v0.2.9)
Codex agentic coding stops mid-session
- fixed Responses API input converter creating duplicate assistant messages per tool-call round, causing models to output EOS after several rounds. assistant message and tool_calls are now merged into a single turn.
Tool-call streaming markup leakage (follow-up)
- fixed additional edge cases where tool-call envelope markup (
[Tool call: ...]) leaked as literal text during streaming. covers bracket prefix sanitizer for multi-prefix detection, unresolved bracket prefix leakage, and mixed bracket marker scenarios (#172, PR #174)
Other fixes
- fixed menubar app now resolves host/port from settings instead of hardcoding
- fixed built-in chat now uses the configured default model instead of the first model in the list (#168)
- fixed model download stall detection with mtime tracking and sequential queue
- added
--macos-targetbuild flag for platform-specific mlx wheel swapping
full changelog: v0.2.8...v0.2.9
New Contributors
- @shyuan made their first contribution in #165
- @jwcrystal made their first contribution in #168
Thanks to @shyuan, @jwcrystal, and @lyonsno for their contributions!
Contributors
shyuan, lyonsno, and jwcrystal