Problem Defination
The proposed idea approaches the demand side management problem using smart dToU policy by selecting favourable participants to further improve user engagement. The basic idea is to design a tariff policy which would match the observed mean consumption to target mean consumption. While improving the tariff policy, the algorithm will also run natural selection algorithm considering users' influence on overall consumption change. The target outcome of the experiment is to select the optimal set of participating users in order to match the target mean consumption for each experiment.
For the aforementioned experimental setup, based on their engagement, the users are categorized as follows:
- Users with 95% engagement
- Users with 60% engagement
- Users with 30% engagement
- Users with less than 10% engagement
The above categories are proposed for initial conceptualization and may change over time.
-
The upper limit on the number of test signals:
- For each experimental setup, a limited number of test signals will be provided.
- The algorithm can decide the number of recipients for each test signal.
-
Available tariff policies:
- The model can choose from a predefined set of tariff policies for every experiment case. This step is implemented due to other constraints on tariff policy design such as - minimum duration of tariff level, predictable peak hours, limits on the maximum number of experiments per day etc. (in other words, why reinvent a wheel!)
-
Minimize the loss function
- The loss is calculated as a quadratic function of the difference between expected mean consumption and target mean consumption
The problem is two-fold. The first step of the problem is to identify the best tariff policy from the given set of tariff policies. The next and more interesting problem is to obtain a specific set of users who will get tariff signals for a particular trial.
Although the experiment design for dToU tariff policy design is a simple problem (because of known and predictable peak hours), the complexity of the problem increases when we try to minimize the number of users who will receive the tariff signals. At this point, the problem can be analyzed from two different perspectives:
- Frequentist problem (classic way of machine learning)
- Bayesian problem
The Bayesian analysis is superior to classic frequentist analysis because of the following advantages:
- Use of priors. Therefore easier to compensate the shift in the target variable (the idea of 'target shift' seems more important in this case than 'covariate shift' as user behaviour would change over time, but contextual variables will have predictable trends)
- Bayesian analysis tells us how likely 'A' is the winner over 'B' and by how much. This improves transparency in the decision making process for an energy retailer company in the practical world. Frequentist problem depends entirely on the prespecified hypothesis. Hence, can be fooled easily.
- Bayesian analysis doe not require a user to define many hyper-parameters/ thresholds to formulate a valid hypothesis. Hence, the robustness and reliability of the algorithm are better. This is especially important in this case as the entire hypothesis formulation depends on simulation data. Therefore, ideally models with Bayesian hypothesis would perform better in the practical world.
Both parts of the problem will be solved with active learning method. The first problem can be solved with frequentist analysis as well as Bayesian analysis (solution can be converged easily with a limited predefined set of tariff policies). Hence, the problem of tariff policy selection can be solved with any available probabilistic method using active learning.
For choosing the optimal set of the user for an experiment (prioritized by algorithm) to meet the target consumption level, Bayesian analysis will be used. The Bayes rule for this problem can be formulated as below,
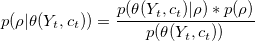
Where,

The above Bayesian approach directly uses the simulator generated 'observation' as the expected mean consumption. A more practical/ realistic approach would be the use of contextual variables. In the latter approach, the assumption is made that the contextual variables will fully describe the energy needs of users at any particular time. The target means consumption will be provided to the model from preset targets (generated by us). The ρ is the set of contributions of k users in total energy consumption change for each preset targets.
What this approach can do-
- design dToU tariff policy with active learning technique
- update the knowledge with each new experiment and can cope up with changing user behaviour over time (target shift)
- organically solve the problem of user selection considering user interest in the dToU scheme
- provide transparency in user selection for reception of price signals with the Bayesian approach
- Practical benefit: Natural selection. Potentially more engaging users can get more rewards by energy retailer company, while least interested users will opt out naturally and won't get punished for not participating
Following tests can be carried out to understand the effectiveness of the approach.
- Analyze the effect of the number of participating users (for each experiment) on final model accuracy (optimal set of users will not provide any new information)
- Effect of number of tariff signals sent (per experiment) on accuracy
- Analyze the effect of target shift/covariate shift by changing input data