Releases: skypilot-org/skypilot
Release v0.12.3.post1
SkyPilot v0.12.3.post1
Get it now with:
uv pip install "skypilot>=0.12.3.post1"What's Changed
- Release 0.12.3.post1 by @Michaelvll in #9736
Full Changelog: v0.12.3rc1...v0.12.3.post1
Contributors
Assets 2
Release v0.12.3
SkyPilot v0.12.3
Get it now with:
uv pip install "skypilot>=0.12.3"What's Changed
- Release 0.12.3 by @Michaelvll in #9708
Full Changelog: v0.12.3rc1...v0.12.3
Contributors
Assets 2
SkyPilot v0.12.2.post1
SkyPilot v0.12.2.post1
Get it now with:
uv pip install "skypilot>=0.12.2.post1"What's changed?
- Pin kubernetes<36 due to RBAC regression from the package
SkyPilot v0.12.2
SkyPilot v0.12.2
Get it now with:
uv pip install "skypilot>=0.12.2"Full Changelog: v0.12.1...v0.12.2
SkyPilot v0.12.1
SkyPilot v0.12.1
Get it now with:
uv pip install "skypilot>=0.12.1"Full Changelog: v0.12.0...v0.12.1
SkyPilot v0.12.0
SkyPilot v0.12.0: Slurm Support, Job Groups for RL, Agent Skill, Recipes, Pool Autoscaling for Batch Inference, 7x Data Mounting, and More
SkyPilot v0.12.0 brings major new capabilities: Slurm integration for running SkyPilot on existing Slurm clusters, Job Groups for heterogeneous parallel workloads like RL training, an Agent Skill that teaches AI coding agents to use SkyPilot, Recipes for sharing reusable YAML templates across teams, and significant Pool enhancements including autoscaling. This release also drops Python 3.7/3.8, with Python 3.9+ now required.
Get it now with:
uv pip install "skypilot[all]>=0.12.0"Or, upgrade your team SkyPilot API server:
NAMESPACE=skypilot
RELEASE_NAME=skypilot
VERSION=0.12.0
helm repo update skypilot
helm upgrade -n $NAMESPACE $RELEASE_NAME skypilot/skypilot \
--set apiService.image=berkeleyskypilot/skypilot:$VERSION \
--version $VERSION --devel --reuse-valuesDeprecations & Breaking Changes:
- Dropped Python 3.7 and 3.8 support—Python 3.9+ is now required (#8489).
sky.jobs.queue(version=1)is deprecated and will be removed in v0.13. Usesky.jobs.queue(version=2)instead. The new version returns richer job metadata as dictionaries (#9118).
Highlights
[New] Slurm Support
SkyPilot now supports connecting your Slurm clusters, bringing its unified interface to one of the most widely used job schedulers in high-performance computing (#5491, #8198, #8219, #8268, #8291, #8470, #8604, #8729, and 25+ additional PRs). Users can launch SkyPilot clusters and managed jobs on Slurm clusters with the same CLI and YAML they use for cloud and Kubernetes, enabling seamless workload portability across all AI infra.

Key capabilities include:
- Multi-node clusters with partition-level resource management
- Container support via pyxis/enroot for reproducible environments
- SSH ProxyJump for clusters behind bastion hosts
- GPU availability viewing with
sky show-gpusfor Slurm partitions - Custom sbatch directives via
sbatch_optionsin task YAML - Configurable workdir and tmpdir for shared filesystem environments
- Admin policy support for Slurm partition routing
# Launch on a Slurm cluster
resources:
accelerators: H100:8
infra: slurm# View GPU availability across Slurm clusters
sky show-gpus --infra slurm
# Launch a training job on Slurm
sky launch --infra slurm/my-cluster train.yaml[New] Agent Skill: AI Agents Meet SkyPilot
SkyPilot now ships an official Agent Skill that teaches AI coding agents—Claude Code, Codex, and others—how to use SkyPilot (#8823, #9017, #9037). With the skill installed, your agent can launch clusters, run managed jobs, serve models, compare GPU pricing, and manage cloud resources—all through natural language.
Install the skill (docs) by telling your agent:
Fetch and follow the install guide https://github.com/skypilot-org/skypilot/blob/HEAD/agent/INSTALL.mdIn our Scaling Autoresearch blog post, we gave Claude Code the SkyPilot agent skill and access to a 16-GPU Kubernetes cluster. Over 8 hours, the agent autonomously submitted ~910 experiments in parallel, achieving a 9x speedup over sequential search—and even discovered hardware-specific optimizations on its own.
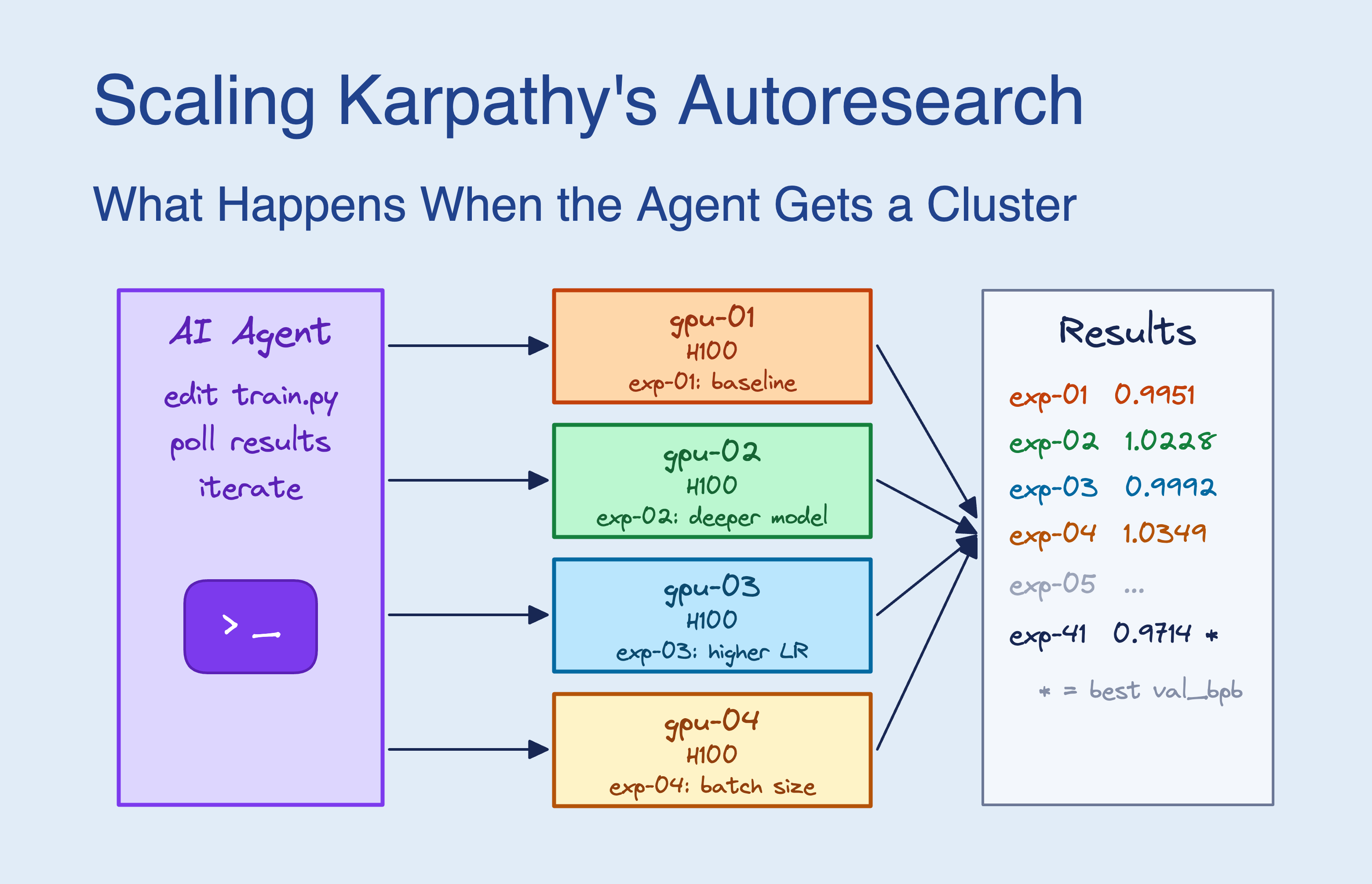
Example interactions your agent can now handle:
| Capability | Example Prompt |
|---|---|
| Launch dev clusters | "Launch a cluster with 4 A100 GPUs. Auto-stop after 30 min idle." |
| Fine-tune models | "Fine-tune Llama 3.1 8B on my dataset at s3://my-data. Use spot instances." |
| Distributed training | "Run PyTorch DDP training across 4 nodes with 8 H100s each." |
| Serve models | "Deploy Llama 3.1 70B with vLLM. Autoscale 1-3 replicas based on QPS." |
| Compare pricing | "What's the cheapest 8x H200 across AWS, GCP, Lambda, and CoreWeave?" |
| Multi-cloud failover | "Submit jobs that try our Slurm cluster first and fall back to AWS." |
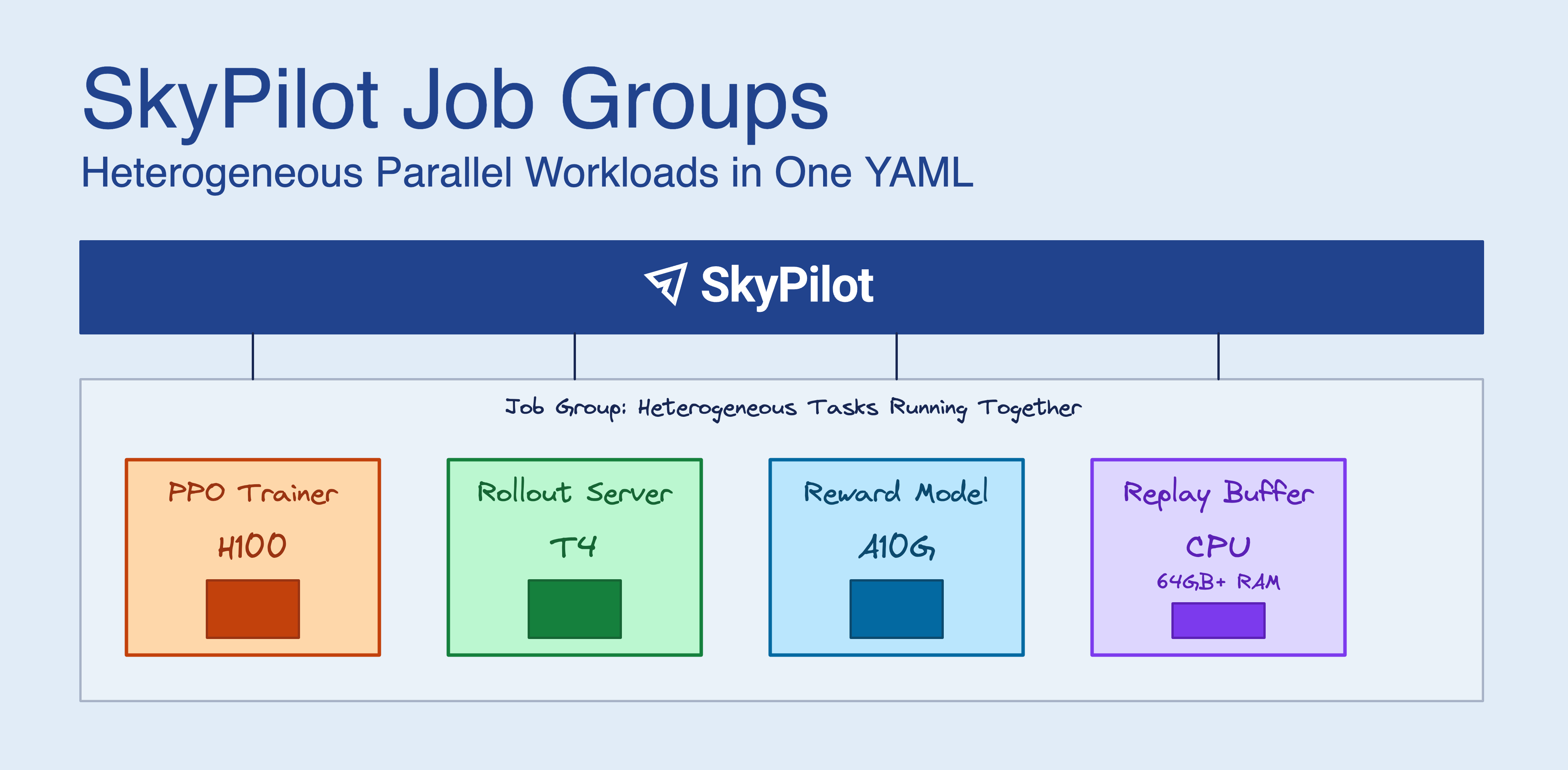
[New] Job Groups: Heterogeneous Parallel Workloads
SkyPilot Job Groups let you define multiple tasks with different resource requirements that run together as a single managed job (#8456, #8664, #8686, #8688, #8713, #8940). This is ideal for reinforcement learning workflows where training, inference, and data servers need different hardware—H100s for policy training, cheaper GPUs for rollout inference, and high-memory CPUs for replay buffers.
SkyPilot provisions all resources together, configures networking automatically with built-in service discovery ({task_name}-{node_index}.{job_group_name}), and manages the full lifecycle as one unit.
# Multi-document YAML for a Job Group
---
name: rl-training
execution: parallel
primary_tasks: [ppo-trainer]
---
name: data-server
resources:
cpus: 4+
run: |
python data_server.py --port 8000
---
name: ppo-trainer
resources:
accelerators: H100:1
run: |
python ppo_trainer.py --data-server data-server-0.rl-training:8000
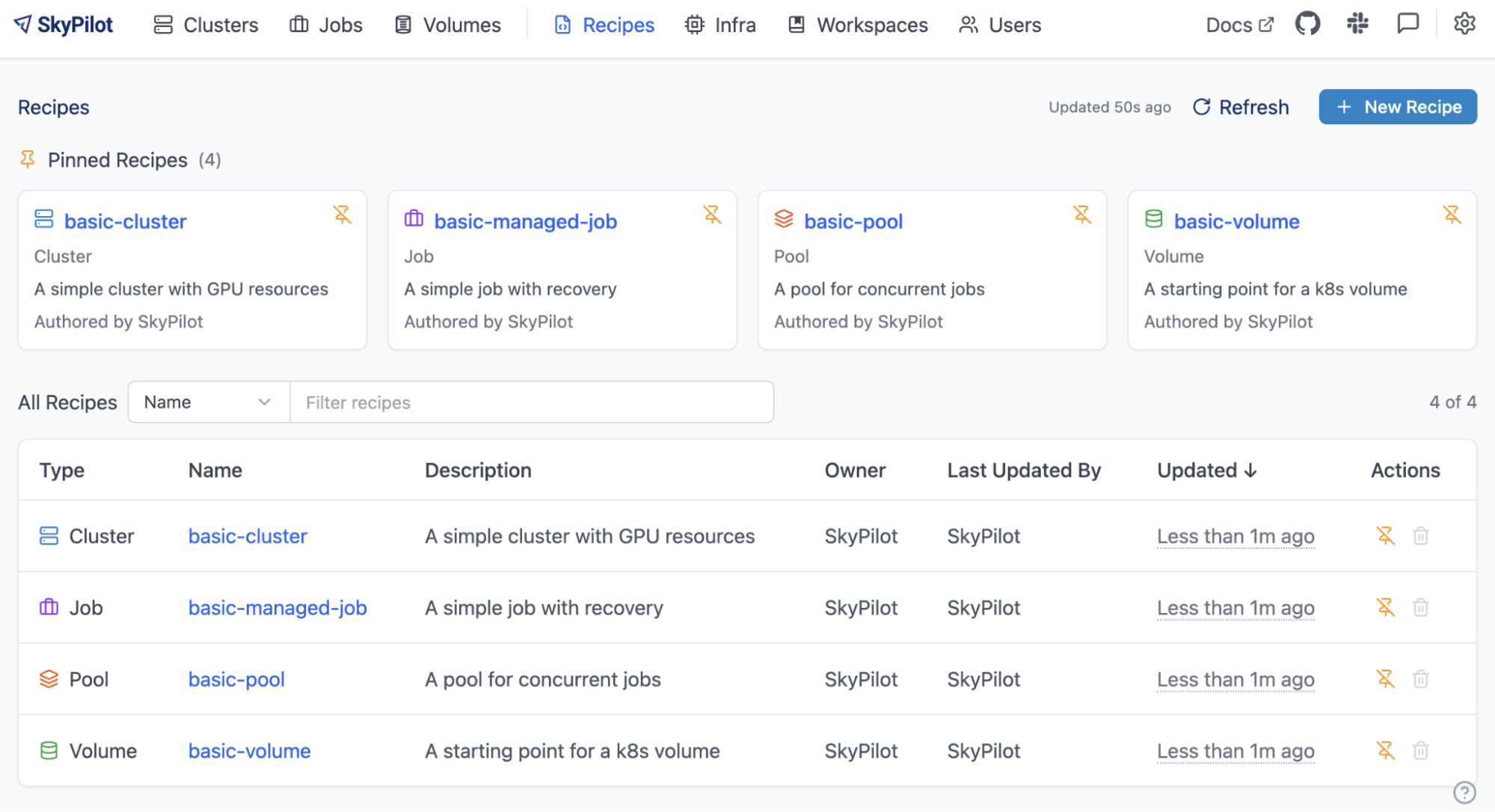
[New] Recipes: Shared YAML Registry
Recipes allow teams to store and share SkyPilot YAMLs in a centralized, team-accessible registry (#8755, #8825, #8851, #8873, #8876, #8882). Launch standardized workloads directly from the CLI or dashboard without local YAML files, reducing DevOps overhead and ensuring consistent configurations across the team.
Recipes support clusters, managed jobs, pools, and SkyServe, with built-in validation that blocks local file dependencies to ensure portability.
# Launch a recipe directly
sky launch recipes:dev-cluster
# Launch with custom overrides
sky launch recipes:gpu-cluster --cpus 16 --gpus H100:4 --env DATA_PATH=s3://my-data
Pool Autoscaling & Enhancements
SkyPilot Pools receive major upgrades with autoscaling, multiple jobs per worker, heterogeneous pools, and memory-aware scheduling (#8483, #8192, #8315, #8279, #8509, #7891).
- Autoscaling (#8483): Pools now automatically scale workers up and down (including to zero) based on queue length, maximizing GPU utilization while minimizing cost.
- Multiple jobs per worker (#8192): Workers can now run multiple concurrent jobs, improving resource utilization for smaller workloads.
- Heterogeneous pools (#8315): Pools can now contain workers with different resource configurations.
- Memory-aware scheduling (#8279): The pool scheduler now considers memory requirements when assigning jobs to workers.
- Fractional GPU improvements (#8509, #8480): Fixed fractional GPU support across multiple workers and corrected dashboard display.
# autoscaling-pool.yaml
pool:
min_workers: 0
max_workers: 10
resources:
accelerators: H100
setup: |
echo "Setup complete!"Dashboa...
Contributors
Assets 2
SkyPilot v0.11.2
SkyPilot v0.11.2: Slurm Support, JobGroups, Enhanced Pools, External Links, Autostop Hooks, 7x data mount speed up and More
SkyPilot v0.11.2 delivers Slurm support in Beta, JobGroups for heterogeneous parallel workloads, and significantly enhanced Pools with autoscaling, multi-job scheduling and heterogeneous GPU support. This release also brings Autostop Hooks, 7x MOUNT_CACHED mode uploads speed up, automatic EFA on EKS, and numerous admin, security, and performance improvements.
Get it now with:
uv pip install "skypilot>=0.11.2"Or, upgrade your team SkyPilot API server:
NAMESPACE=skypilot
RELEASE_NAME=skypilot
VERSION=0.11.2
helm repo update skypilot
helm upgrade -n $NAMESPACE $RELEASE_NAME skypilot/skypilot \
--set apiService.image=berkeleyskypilot/skypilot:$VERSION \
--version $VERSION --devel --reuse-valuesBreaking Change: Python 3.9+ required — Python 3.7 and 3.8 are no longer supported (#8489). Please upgrade before installing this release.
Highlights
[Beta] Slurm Support
SkyPilot now supports Slurm as a new infrastructure backend, enabling users to orchestrate workloads on HPC clusters alongside cloud VMs and Kubernetes — all through the same unified interface (docs, #5491, #8138).
This release brings comprehensive Slurm capabilities:
- Multi-node distributed workloads — run distributed training jobs across multiple Slurm nodes with proper environment variable propagation and per-node logging (#8219)
- Containerized execution via NVIDIA pyxis/enroot — specify Docker images with
--image-idfor reproducible, GPU-accelerated workloads (#8604, #8609) - Resource-scoped SSH sessions —
ssh <cluster>drops you inside the Slurm job allocation, sonvidia-smicorrectly reflects only your allocated GPUs (#8268) - Interactive SSH authentication (2FA, password prompts) for clusters requiring keyboard-interactive auth (#8317)
- Partition support — Slurm partitions are mapped to SkyPilot zones, enabling partition-aware scheduling (#8198)
- Multi-cluster support — configure and use multiple Slurm clusters simultaneously
- Dashboard integration — Slurm clusters appear in the infrastructure page with status and GPU utilization
See the Slurm documentation for setup instructions.

JobGroups: Heterogeneous Parallel Workloads
JobGroups enable running multiple jobs with different resource requirements together as a managed group (blog, #8456). Define multi-task pipelines in a single multi-document YAML file:
# Header: job group metadata
name: rl-training
execution: parallel
primary_tasks: [trainer]
termination_delay: 30s
---
name: trainer
resources:
accelerators: A100:8
run: python train.py
---
name: reward-server
resources:
accelerators: A100:1
run: python reward_server.pyKey capabilities:
- Parallel cluster launch and monitoring — all jobs launched and tracked concurrently
- Inter-job networking — easy task name based hostname discovery (.) for job-to-job communication
- Dashboard UI — expandable rows for multi-task groups, task-specific log filtering
- CLI support —
sky jobs logs --task-name <name>for viewing specific task logs
Example applications included: RL post-training (RLHF) pipeline and parallel train-eval pipeline.
Enhanced Pools: Multi-Job Scheduling and Heterogeneous GPUs
SkyPilot Pools receive significant upgrades in this release:
- Multiple jobs per worker — the scheduler now performs resource-aware bin-packing, tracking CPU, memory, and accelerator usage to fit multiple jobs on a single worker (#8192, #8279)
- Autoscaling — pools can now automatically scale workers up and down (including to zero) based on queue length. Specify
min_workers,max_workers, and target queue length; aQueueLengthAutoscalerhandles the rest while protecting running jobs from cancellation (#8483) - Heterogeneous GPU support — specify
any_ofresource configurations and the scheduler dynamically resolves to available hardware (#8315):
resources:
any_of:
- accelerators: T4:1
- accelerators: A100:1- 9x faster concurrent job launch — launching 100 concurrent jobs reduced from 4.5 minutes to 30 seconds using the new
--num-jobsargument (#7891) - Fractional GPU scheduling fix — fractional GPU jobs now correctly schedule across all workers (#8509)
External Links
SkyPilot dashboard now automatically detects your W&B links generated by your AI workloads. No need to dig into the job logs to figure out where your training panels are. (#8405)

Autostop Hooks
An autostop hook mechanism allow running custom scripts before a cluster is automatically stopped — for example, to save checkpoints, sync W&B runs, or send Slack notifications (#8412):
resources:
autostop:
idle_minutes:10
hook:|
wandb sync
curl -X POST $SLACK_WEBHOOK -d '{"text": "Cluster shutting down"}'
hook_timeout:300- New
sky logs --autostopcommand to view hook execution logs sky execis rejected onAUTOSTOPPINGclusters;sky launchwaits for autostop to complete before restarting
Automatic EFA Setup on Amazon EKS
SkyPilot now automatically configures Elastic Fabric Adapter (EFA) on EKS with a single flag (#8557):
resources:
network_tier: bestThis automates what was previously a complex manual setup, delivering ~78.8 GB/s inter-node bandwidth (vs ~4.1 GB/s without EFA), critical for distributed training performance. EFA interfaces are allocated proportionally to the requested GPU count.

7x MOUNT_CACHED Uploads Speed Up
Parallel uploads are now the default for MOUNT_CACHED file mounts, delivering a 7x speedup — flush time dropped from 151s to 21s for a ~14.6 GB test workload (#8455). A new data.mount_cached.sequential_upload config option allows reverting to sequential uploads if needed.

Exit Code-Based Job Recovery
Users can now specify exit codes that trigger automatic job recovery in managed jobs (#8324):
resources:
job_recovery:
recover_on_exit_codes:[29]When a job exits with a specified code, SkyPilot automatically recovers it — useful for transient failures with known error codes.
Windows WSL Support
Automatically detect that SkyPilot is running in WSL, and seamless set up VSCode Remote-SSH for Windows users (#8669)
Admin Deployment Improvement
- External authentication proxy support — deploy behind AWS ALB with Cognito, Azure Front Door, or custom SSO proxies; supports both plaintext and JWT header formats (#8751)
- Sidecar container support — Istio, Datadog, and other sidecar injection no longer breaks K8s provisioning; SkyPilot explicitly targets the
ray-nodecontainer (#8353, #8444)
What’s New
Kubernetes
- Improved Kueue integration — 24-hour provisioning timeout, workspace-level queue configuration, controller pod exclusion, and pod annotations (#8484)
- GPU detection fix — L40S no longer misidentified as L4; added Blackwell, newer Hopper, and Ada Lovelace GPUs (#8593)
kubernetes.set_pod_resource_limits— set pod CPU/memory limits relative to requests for pod resource limit enforcement ([#8644](https://github.com/skypilot-org/skypilot/pul...
Contributors
Assets 2
Release v0.11.2rc1
This patch release is a minor bump from v0.11.1 to to get you the latest fixes:
- Always set SSH key permission to avoid issue when jobs controller restarts by high availability setting #8316
Install the release candidate:
# Select needed clouds.
uv pip install 'skypilot[kubernetes,aws,gcp]==0.11.2rc1'
Upgrade your remote API server:
NAMESPACE=skypilot # TODO: change to your installed namespace
RELEASE_NAME=skypilot # TODO: change to your installed release name
helm repo update skypilot
helm upgrade -n $NAMESPACE $RELEASE_NAME skypilot/skypilot \
--version 0.11.2-rc.1 \
--reset-then-reuse-values \
--set apiService.image=null # reset to default image
Full Changelog: v0.11.1...v0.11.2rc1
SkyPilot v0.11.1
This patch release is a minor bump from v0.11.0 to to get you the latest fixes:
- #8285: Fix an issue where the API server request database is incorrectly locked causing an irresponsive API server with an error:
sqlite3.OperationalError: database is locked
See the full v0.11 release notes for everything new in SkyPilot v0.11!
SkyPilot v0.11.0
SkyPilot v0.11.0: Multi-Cloud Pools, Fast Managed Jobs, Enterprise-Readiness at Large Scale, Programmability
SkyPilot v0.11.0 delivers major new features: Pools and Managed Jobs Consolidation Mode; significant improvement enterprise-readiness at large scale: supports hundreds of AI engineers with a single API server instance, avoid OOM, >10x performance improvement on many requests, additional observability, and more; and UX improvements: Templates, Python SDK, CI/CD, Git Support, and more.
Get it now with:
uv pip install "skypilot>=0.11.0"Or, upgrade your team SkyPilot API server:
NAMESPACE=skypilot
RELEASE_NAME=skypilot
VERSION=0.11.0
helm repo update skypilot
helm upgrade -n $NAMESPACE $RELEASE_NAME skypilot/skypilot \
--set apiService.image=berkeleyskypilot/skypilot:$VERSION \
--version $VERSION --devel --reuse-valuesHighlights
[Beta] SkyPilot Pools: Batch inference across clouds & k8s
SkyPilot supports spawning a pool that launches a set of workers across many clouds and Kubernetes clusters (docs, #6260, #6426, #6459, #6552, #6591, #6665, #6675, #7332, #7963, #8008, #7876, #8047, #7930,#8039, #7846, #7855, #7919, #7920). Jobs can be scheduled on this pool and distributed to workers as they become available.
Key benefits include:
- Fully utilize your GPU capacity across clouds & k8s
- Unified queue for jobs on all infra
- Keep workers warm, scale elastically
- Step aside for other higher priority jobs; reschedule when GPUs become available
Learn more in our blog post.

[GA] Managed Jobs Consolidation mode
Consolidation Mode is general available (#7122, #7127, #7396, #7459, #7498, #7560, #7601, #7619, #7717, #7720, #7847, #8082, #8021, #8106). This enables:
- 6x faster job submission
- consistent credentials across the API server and jobs controller.
- Persistent managed jobs state on postgres
# config.yaml
jobs:
controller:
consolidation_mode: true # Currently defaults to False.

Efficient and Robust Managed Jobs
We have significantly optimized the Managed Jobs controller, allowing it to handle 2000+ parallel jobs on a single 8-CPU controller—an 18x improvement in job capacity with the same controller size (#7051, #7371, #7379, #7408, #7432, #7473, #7487, #7488, #7494, #7519, #7585, #7595, #7945, #7966, #7979,#8036, #8095).

Enterprise-Ready SkyPilot at Large-scale
- Support hundreds of AI engineers with a single SkyPilot API server instance
- Significant reduction in memory consumption and avoid OOM for API server

- CLI/SDK/Dashboard speed up with a large amount of clusters, jobs

- Comprehensive API server metrics for operation

- SSO support with Microsoft Entra ID

Kubernetes
UX, Robustness, Performance Improvement
- Robust SSH for SkyPilot cluster on Kubernetes
- Robust multi-node(pod) provisioning with retry and recovery (#7820, #7854, #7852)
- Improve resource cleanup after termination
- Intelligent GPU name detection
- Improved volume support: label support, name validation, SDK support.
Volume Support for Existing PVC and Ephemeral Volumes (#7915, #7971,#8179)
-
Exising PVC: Reference pre-existing Kubernetes PersistentVolumeClaims as a SkyPilot volume (#7915).
# volume.yaml name: existing-pvc-name type: k8s-pvc infra: k8s/context1 use_existing: true config: namespace: namespace
-
Ephemeral Volumes: automatically create volumes when a cluster is launched and deleted when the cluster is torn down, making them ideal for temporary storage across multiple nodes, such as caches and intermediate results.
# task.sky.yaml file_mounts: /mnt/cache: size: 100Gi
Cloud Support
CoreWeave Integration Announcement
CoreWeave now officially support SkyPilot (#6386, #6519, #6895, #7756, #7838). This integration provides: Infiniband Support, Object Storage, Autoscaling.
See the announcement on Coreweave blog.

AMD GPU Support Announcement
SkyPilot now fully supports AMD GPUs on Kubernetes clusters (#6378, #6944). This includes: GPU Detection and Scheduling, Dashboard Metrics, ROCm Support.
See the announcement on AMD Rocm blog.

More Clouds Support
- Together AI Instant cluster
- Seeweb support
User Experience
SkyPilot Templates
SkyPilot now ships predefined YAML templates for launching clusters with popular frameworks and patterns. Templates are automatically available on all new SkyPilot clusters. (#7935, #7965)
You can now launch a multi-node Ray cluster by adding a single line to your YAML’s run block:
run: |
# One-line setup for a distributed Ray cluster
~/.sky/templates/ray/start_cluster
# Submit your job
python train.pyProgrammability: SkyPilot Python SDK
SkyPilot Python SDK is significantly improved with:
- Type hints

- Log streaming
logs = sky.tail_logs(cluster_name, job_id, follow=True, preload_content=False)
for line in logs:
if line is not None:
if 'needle in the haystack' in line:
print("found it!")
break
logs.close()- Admin policy: build admin policy with helper functions
resource_config = user_request.task.get_resource_config()
resource_config['use_spot'] = True
user_request.task.set_resources(re...