SkyPilot v0.12.0
SkyPilot v0.12.0: Slurm Support, Job Groups for RL, Agent Skill, Recipes, Pool Autoscaling for Batch Inference, 7x Data Mounting, and More
SkyPilot v0.12.0 brings major new capabilities: Slurm integration for running SkyPilot on existing Slurm clusters, Job Groups for heterogeneous parallel workloads like RL training, an Agent Skill that teaches AI coding agents to use SkyPilot, Recipes for sharing reusable YAML templates across teams, and significant Pool enhancements including autoscaling. This release also drops Python 3.7/3.8, with Python 3.9+ now required.
Get it now with:
uv pip install "skypilot[all]>=0.12.0"Or, upgrade your team SkyPilot API server:
NAMESPACE=skypilot
RELEASE_NAME=skypilot
VERSION=0.12.0
helm repo update skypilot
helm upgrade -n $NAMESPACE $RELEASE_NAME skypilot/skypilot \
--set apiService.image=berkeleyskypilot/skypilot:$VERSION \
--version $VERSION --devel --reuse-valuesDeprecations & Breaking Changes:
- Dropped Python 3.7 and 3.8 support—Python 3.9+ is now required (#8489).
sky.jobs.queue(version=1)is deprecated and will be removed in v0.13. Usesky.jobs.queue(version=2)instead. The new version returns richer job metadata as dictionaries (#9118).
Highlights
[New] Slurm Support
SkyPilot now supports connecting your Slurm clusters, bringing its unified interface to one of the most widely used job schedulers in high-performance computing (#5491, #8198, #8219, #8268, #8291, #8470, #8604, #8729, and 25+ additional PRs). Users can launch SkyPilot clusters and managed jobs on Slurm clusters with the same CLI and YAML they use for cloud and Kubernetes, enabling seamless workload portability across all AI infra.

Key capabilities include:
- Multi-node clusters with partition-level resource management
- Container support via pyxis/enroot for reproducible environments
- SSH ProxyJump for clusters behind bastion hosts
- GPU availability viewing with
sky show-gpusfor Slurm partitions - Custom sbatch directives via
sbatch_optionsin task YAML - Configurable workdir and tmpdir for shared filesystem environments
- Admin policy support for Slurm partition routing
# Launch on a Slurm cluster
resources:
accelerators: H100:8
infra: slurm# View GPU availability across Slurm clusters
sky show-gpus --infra slurm
# Launch a training job on Slurm
sky launch --infra slurm/my-cluster train.yaml[New] Agent Skill: AI Agents Meet SkyPilot
SkyPilot now ships an official Agent Skill that teaches AI coding agents—Claude Code, Codex, and others—how to use SkyPilot (#8823, #9017, #9037). With the skill installed, your agent can launch clusters, run managed jobs, serve models, compare GPU pricing, and manage cloud resources—all through natural language.
Install the skill (docs) by telling your agent:
Fetch and follow the install guide https://github.com/skypilot-org/skypilot/blob/HEAD/agent/INSTALL.mdIn our Scaling Autoresearch blog post, we gave Claude Code the SkyPilot agent skill and access to a 16-GPU Kubernetes cluster. Over 8 hours, the agent autonomously submitted ~910 experiments in parallel, achieving a 9x speedup over sequential search—and even discovered hardware-specific optimizations on its own.
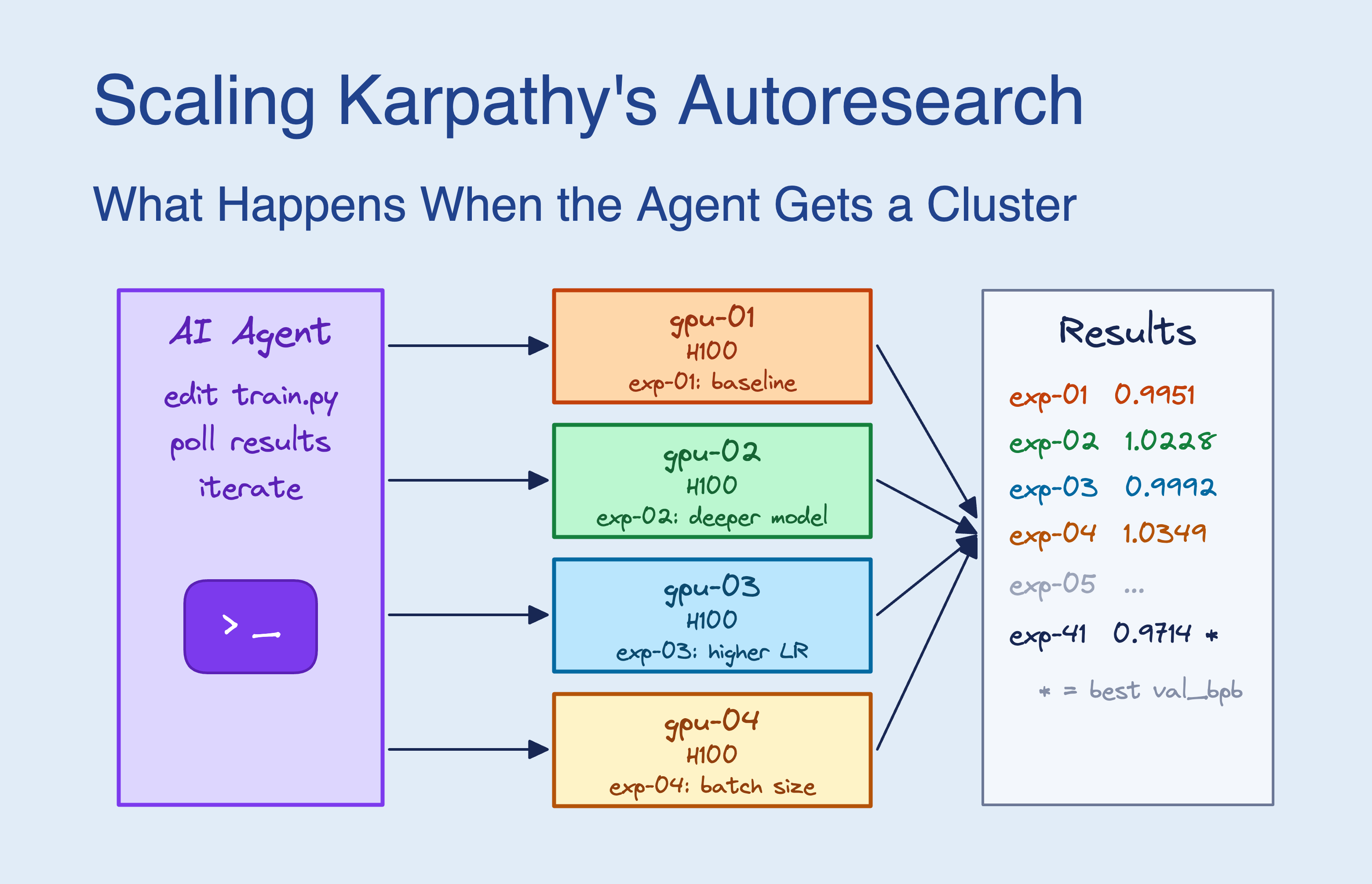
Example interactions your agent can now handle:
| Capability | Example Prompt |
|---|---|
| Launch dev clusters | "Launch a cluster with 4 A100 GPUs. Auto-stop after 30 min idle." |
| Fine-tune models | "Fine-tune Llama 3.1 8B on my dataset at s3://my-data. Use spot instances." |
| Distributed training | "Run PyTorch DDP training across 4 nodes with 8 H100s each." |
| Serve models | "Deploy Llama 3.1 70B with vLLM. Autoscale 1-3 replicas based on QPS." |
| Compare pricing | "What's the cheapest 8x H200 across AWS, GCP, Lambda, and CoreWeave?" |
| Multi-cloud failover | "Submit jobs that try our Slurm cluster first and fall back to AWS." |
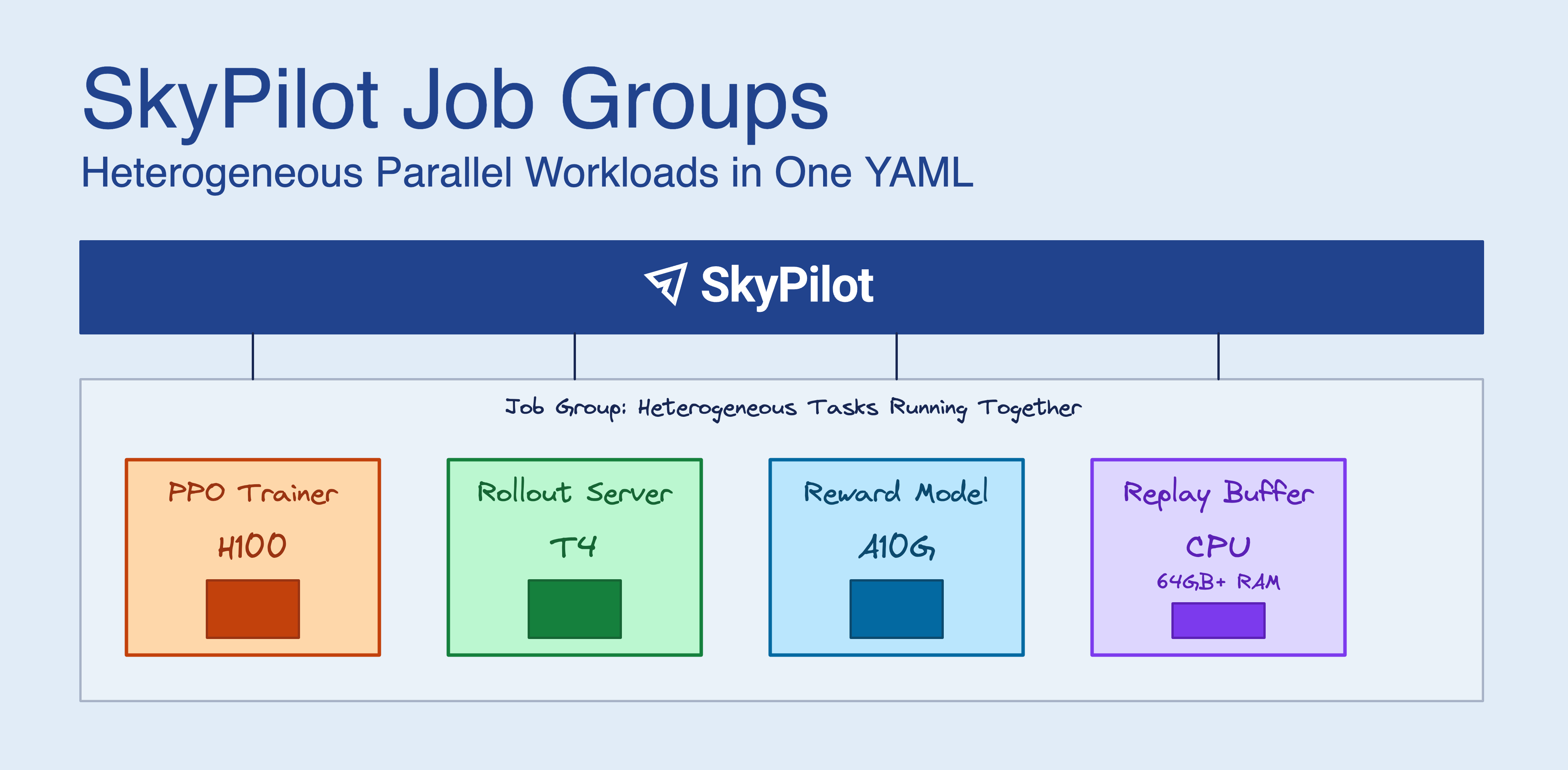
[New] Job Groups: Heterogeneous Parallel Workloads
SkyPilot Job Groups let you define multiple tasks with different resource requirements that run together as a single managed job (#8456, #8664, #8686, #8688, #8713, #8940). This is ideal for reinforcement learning workflows where training, inference, and data servers need different hardware—H100s for policy training, cheaper GPUs for rollout inference, and high-memory CPUs for replay buffers.
SkyPilot provisions all resources together, configures networking automatically with built-in service discovery ({task_name}-{node_index}.{job_group_name}), and manages the full lifecycle as one unit.
# Multi-document YAML for a Job Group
---
name: rl-training
execution: parallel
primary_tasks: [ppo-trainer]
---
name: data-server
resources:
cpus: 4+
run: |
python data_server.py --port 8000
---
name: ppo-trainer
resources:
accelerators: H100:1
run: |
python ppo_trainer.py --data-server data-server-0.rl-training:8000
[New] Recipes: Shared YAML Registry
Recipes allow teams to store and share SkyPilot YAMLs in a centralized, team-accessible registry (#8755, #8825, #8851, #8873, #8876, #8882). Launch standardized workloads directly from the CLI or dashboard without local YAML files, reducing DevOps overhead and ensuring consistent configurations across the team.
Recipes support clusters, managed jobs, pools, and SkyServe, with built-in validation that blocks local file dependencies to ensure portability.
# Launch a recipe directly
sky launch recipes:dev-cluster
# Launch with custom overrides
sky launch recipes:gpu-cluster --cpus 16 --gpus H100:4 --env DATA_PATH=s3://my-data
Pool Autoscaling & Enhancements
SkyPilot Pools receive major upgrades with autoscaling, multiple jobs per worker, heterogeneous pools, and memory-aware scheduling (#8483, #8192, #8315, #8279, #8509, #7891).
- Autoscaling (#8483): Pools now automatically scale workers up and down (including to zero) based on queue length, maximizing GPU utilization while minimizing cost.
- Multiple jobs per worker (#8192): Workers can now run multiple concurrent jobs, improving resource utilization for smaller workloads.
- Heterogeneous pools (#8315): Pools can now contain workers with different resource configurations.
- Memory-aware scheduling (#8279): The pool scheduler now considers memory requirements when assigning jobs to workers.
- Fractional GPU improvements (#8509, #8480): Fixed fractional GPU support across multiple workers and corrected dashboard display.
# autoscaling-pool.yaml
pool:
min_workers: 0
max_workers: 10
resources:
accelerators: H100
setup: |
echo "Setup complete!"Dashboard Performance & GPU Metrics
The SkyPilot dashboard receives significant performance improvements and new observability features (#8523, #8718, #8651, #8534, #8539).
- 6x faster infra page on first load with general speed improvements across all pages (#8523)
- GPU metrics for managed jobs and job groups (#8718), including GPU temperature panel (#8472) and external Grafana links (#8599)
- Cluster burn rate metric (#8683) and RPS-by-user metric (#8999) in the API server Grafana dashboard
- Progressive loading for workspace and infra pages (#8575, #8550)
Consolidation Mode by Default
Deploy-mode API servers now auto-enable consolidation mode (#9090), which runs managed job controllers on the API server itself instead of launching separate controller VMs. This eliminates controller overhead costs and simplifies managed job operations for team deployments.
7x MOUNT_CACHED Speed Up
Parallel uploads are now the default for MOUNT_CACHED file mounts, delivering a 7x speedup — flush time dropped from 151s to 21s for a ~14.6 GB test workload (#8455). Advanced tuning options are available via data.mount_cached config (#8810, #8831, #8994).

Automatic EFA on EKS
SkyPilot now automatically configures Elastic Fabric Adapter (EFA) on EKS, delivering ~78.8 GB/s inter-node bandwidth (vs ~4.1 GB/s without EFA) — critical for distributed training performance (#8557, #8771):
resources:
network_tier: best

Autostop Hooks
A new autostop hook mechanism allows running custom scripts before a cluster is automatically stopped — for example, to save checkpoints, sync W&B runs, or send notifications (#8412):
resources:
autostop:
idle_minutes: 10
hook: |
wandb sync
curl -X POST $SLACK_WEBHOOK -d '{"text": "Cluster shutting down"}'
hook_timeout: 300External Links (W&B Integration)
The SkyPilot dashboard now automatically detects W&B links and other external URLs generated by your AI workloads — no more digging through job logs (#8405).

Exit Code-Based Job Recovery
Users can now specify exit codes that trigger automatic job recovery in managed jobs, useful for transient failures with known error codes (#8324):
resources:
job_recovery:
recover_on_exit_codes: [29]Windows WSL Support
SkyPilot now auto-detects WSL and seamlessly configures VSCode Remote-SSH for Windows users (#8669).
What's new: compared to v0.11.0
API Server
- File mounts upload v2: Upload caching, isolation, and garbage collection for improved performance and reliability (#9049).
- Content Security Policy and security headers middleware for improved security posture (#8951).
- Fix Zip Slip vulnerability in
/uploadendpoint (#8723). - Proxy auth support (#8751) and polling-based authentication for
sky api login(#8590). - Server-side heartbeat daemon for health monitoring (#8984, #8997).
- Auto-enable consolidation mode for deploy-mode servers (#9090).
- Daemon log size limit and auto rotation (#9028) and GC for request debug logs (#9029).
- Fix concurrent Alembic migration crash on startup (#9068).
- Fixed stalled transaction blocking write operations (#8285).
- Fixed AWS session cache memory leak in status refresh daemon (#8098).
- Fixed BasicAuth rejecting Bearer tokens when both auth methods enabled (#8503).
- Fixed
sky api stophang on zombie processes in containers (#8839). - Fixed API server slow with many workspaces (#8968).
- Fixed HTTP 400 errors with large cookies (#8834).
- Fixed SSO loopback issues (#8554) and workspace fixes (#8569).
- Fixed remote version not being set due to cache hits (#8886).
- Do not persist sqlite db when rolling-update is enabled (#8607).
- Fixed Postgres issue with DISTINCT queries (#8716).
- Fixed Casbin RoleManager race condition in
/usersendpoint (#8973). - Search API requests by cluster name (#8786).
- Separate request logs from task log dir (#8793), PID and millisecond timestamps in API server logs (#8270).
- Backward compatibility: Map
AUTOSTOPPINGstatus toUPfor old clients (#9073). - Fixed Grafana datasource provisioning race condition (#8835).
- Helm chart improvements: scheduling constraints (#8134),
fullnameOverridesupport (#8528), RWX persistent storage with RollingUpdate (#8537), unified ingress resource (#8532), disabling basic auth middleware (#8694), CoreWeave credentials (#8200), DigitalOcean credentials (#7931), SSH node pool config (#8249), Slurm credentials (#8729), AWS config mounting (#8827).
Kubernetes
- Auto EFA setup on EKS for high-performance networking (#8557, #8771).
- Multi-container sidecar support for SkyPilot pods (#8444).
- Pod resource limits config flag for setting CPU/memory limits on pods (#8644).
- User-configurable pricing catalog for virtual instance types on Kubernetes and Slurm (#8874).
remote_identityoverride in task config (#8659).- Kueue integration improvements (#8484).
- Do not schedule on not-ready nodes (#8172), disable Ray memory monitor on k8s (#8231).
- Show cordon and taint info in GPU info (#8596), CPU/memory info in
sky show-gpusand infra dashboard (#8222). - Fail fast during cluster provisioning (#8979), force delete stale pods during launch (#8752).
- Avoid erroring for unknown instance types with GKE autoscaler (#8326).
- Workspace label on pods (
skypilot-workspace) for filtering (#8893) and user annotations on k8s pods (#9065). - Exclude kubeconfig for non-controller clusters when
allowed_contextsis set (#8821). - Support parsing millibytes for memory (#8520).
- Increased WebSocket open timeout for SSH proxy (#8707).
- Add retry for optional packages installation (#8977), Teleport SSL retry (#8976).
- Fix orphaned stream logs in Kubernetes (#8945).
- Fix pod name and worker index mismatch (#8037), GPU labeller for L40S (#8593), service leak (#8745), race condition in k8s client construction (#8705), kubeconfig upload with SERVICE_ACCOUNT (#8386), pod keep-alive SIGTERM vulnerability (#8972), RBAC 409 race (#8969), netcat install on Debian Trixie (#9086), rsync wait script (#8396), watch client error (#8757), NullPool for PG async engines (#8725), pod termination reason with null timestamps (#8674).
Volumes
- Volume subpath support for mounting specific directories within a volume (#9039).
- Create volumes from PVCs with target labels (#8853) and from existing file systems (#9048).
- Surface PVC errors during
sky launch(#8589) and revamped volume background refresh (#8524). - Volume mounting warning now shows when relaunching on the same cluster with a volume (#8436).
- Fail fast for not-ready volumes (#8739).
- Refresh volume config to set region correctly for in-cluster volumes (#8543).
- Improved volume operations error handling for context errors (#8397).
- Fixed ephemeral volume creation (#8179).
Storage
- Parallel upload by default for
MOUNT_CACHEDwith configurable sequential fallback (#8455). - Advanced
MOUNT_CACHEDconfigurations for workload-specific tuning (#8810, #8831, #8994). - VastData S3-compatible object storage support (
vastdata://) (#9041, #9072). --gracefulflag for cluster storage operations (#8753).- Fixed S3 mounting with SSO and IAM role credentials (#8358).
Core & Backend
- Pending state for clusters during provisioning for clearer status visibility (#8262).
- Autostop hook that runs before cluster autostop for custom cleanup (#8412).
- Auto-configure Windows SSH config when running in WSL (#8669).
provision.install_condaconfig to disable conda installation on provisioned nodes (#8662).SKYPILOT_USERenvironment variable available in jobs (#8747).- Configurable
.skydirectory location—put.skysomewhere other than$HOME(#8153). - Restore autostop settings on cluster start (#8022).
- Support running multiple skylets on a single machine (#8156).
- Redact Docker passwords from provision and build logs (#8080, #8910).
- Better Docker username handling (#8632).
- Fixed SSH authentication for Docker images with non-root default users (#8738).
- Fixed autostop not triggering on Docker-based clusters (#8932).
- Fixed failed jobs reported as SUCCEEDED due to
rcloneflush script (#8930). - Fixed entrypoint quoting for args with shell special characters (#8939).
- Fixed
sky cancelreliability (#8203), uv >=0.10.5 stripping execute permissions on XFS (#8904), WebSocket SSH proxy timeout under concurrent connections (#9001), openssh version andSetEnvcompatibility (#9075). - Fixed unexpected behavior and improved logging for
sky downfailure (#8460). - Fixed Docker images with
WORKDIRset to site-packages causing setup failures (#8378). - Fixed bash operator precedence in cloud dependency install chain (#9002).
- Fixed subprocess UTF-8 codec error (#8802), accelerator inference issue with resource copy (#8648).
- Always set SSH key permissions correctly (#8316).
- Rsync: add
--no-owner --no-groupfor both uploads and downloads (#8556). - User-specific exit codes for job retry (#8324).
- Fixed
RuntimeError: dictionary changed size during iterationinContextualEnviron(#8962).
Managed Jobs
- Graceful cancel for managed jobs—download logs before cleanup when cancelled (#8772, #8990).
- API access for managed jobs with token cleanup (#8900).
- Retry job status check with timeout-based retry and cluster refresh in separate thread (#8366).
- Clean up orphaned replica records during service shutdown (#8175).
- Add
internal_external_ipsandinternal_servicesto ManagedJobRecord for richer job metadata (#8735). - Warning for lost file mounts on rolling update with consolidation mode (#8350).
- Fixed file mount failure on rolling upgrade with consolidation (#8333, #9027).
- Fixed consolidation mode service scaling with memory (#8989).
- Fixed update number of SkyServe workers UX (#8963).
- Metrics for managed jobs in consolidation mode (#9038).
Infrastructure & Cloud Integrations
AWS
- Instance storage via
LocalDiskfeature: Access NVMe instance storage on supported instance types (#8762, #8807, #8661). - Multiple VPCs with failover (#8722), failover when VPC not found in region (#8734).
- Added ap-southeast-4 region (Melbourne) (#8055).
- Changed g7e accelerator name in catalog to RTXPRO6000 (#8721).
- Fixed p5e.48xlarge CPU count inference (#8465).
GCP
- Queued Resources support for capacity reservation (#8481).
- Fixed catalog fetcher for c3d, c4, c4d instance families (#8327).
Azure
- Labels support for VM instance tags (#8987).
- Networking support:
use_internal_ips,vpc_name,ssh_proxy_command(#8986). - Remote identity with managed identities (#8985).
- Fixed blobfuse2 mounting on Debian 13 (trixie) (#8730).
Nebius
- Kubernetes autoscaler support (#8805).
- Configurable
subnet_id(#8814) and disk tiers (#8905). - Enable UFW to fix CVE-2023-48022 (#8627).
Vast
- Secure instances option (#8212), extended GPU options (#8536).
- Fixed SSH authentication (#8614), spot bid_per_gpu (#9000), SSH key double-quoting (#9059).
RunPod
New Clouds
Other
SSH Node Pools
- Ban heterogeneous nodes during SSH node pool setup (#8230).
- Fixed SSH tunnel file after API upgrade (#8508),
lstrip('ssh-')bug (#8417), autoscaler config polluting SSH node pools (#9012). - Internal refactoring and deployment improvements (#8154, #8173, #8226).
User Experience
Admin Control
- Client version info in admin policy
UserRequest(#8741). - Slurm partition routing admin policy example (#9003).
Dashboard
- Filtering by SkyPilot labels (#8507), last update timestamp next to refresh button (#8370).
- Slurm cluster detail pages and improved context detail views (#8692, #8675).
- Upgrade banner detection and visibility fix (#9067).
- Default clusters page filter to cluster name (#8828).
- Show hint when no infra enabled (#8452), fix < 1 CPU rounding (#8289, #8424).
- Improved log handling for large line sizes (#8281), compressed log downloads (#8626).
- GPU metrics refresh fix (#8496), GPU temperature panel (#8472), Prometheus retention policy improvements (#8471).
- Glassy loading effect for infra page (#8624), round CPU/memory to integers on infra page (#8676), warning icon for unreachable contexts (#8677).
- Fixed enabled clouds during Kubernetes refreshing (#8313), service account expiry input not accepting 0 (#8678), download logs from dashboard (#8407).
CLI
- New
sky gpuscommand group withlistandlabelsubcommands (#8691). --secret-fileoption for passing secrets from files (#8646).- JSON output support for select CLI commands (#8784).
- Hint for k8s nodes with GPU labels but zero GPU resources (#8629).
- Dedup GPU counts on
sky show-gpus(#8576), fix pandas >=3.0.0 compatibility (#8643). - Allow
ssheven if Ray cluster is in bad state (#8649). - Hint for updating SkyPilot when outdated (#8197).
- Exit 1 if
sky serve statusfails (#8406). --allflag forsky jobs pool status(#8392).- Hide
volumefromsky -h(#8228). - Remove the start-server side-effect of
sky api info(#9076). - Quieter jobs log tailing cancellation (#8917).
Dependencies
- Pin SQLAlchemy >= 2.0.0 and alembic >= 1.8.0 (#8546).
- Added greenlet for SQLAlchemy asyncio support (#8653).
- Pin pycares < 5 to work around aiodns issue (#8259).
- Updated colorama version pin (#8319).
- Lazy pandas import in Seeweb and Shadeform catalogs for faster CLI startup (#8446).
Documentation & Examples
- Slurm documentation: Getting started guide (#8138), migration guide (#8515), FAQ (#8275), GPU availability (#8666), container images and private registries (#8920), partition routing policy (#9003).
- Airgapped setup documentation (#7312).
- New examples: NVIDIA Dynamo serving (#7333), SAM3 video segmentation (#8384), VeRL search (#8241), OpenClaw (#8856), fairseq2 (#8844), OpenRLHF (#8077), Job Group SDK examples (#8940), AWS EFA on HyperPod Slurm (#8966).
- Orchestrator integrations: Prefect (#8506), Temporal (#4017).
- Deepseek OCR and SkyPilot Pools example (#8016), improved GitOps example (#8030), Monarch example (#8845).
- Marimo notebooks as a SkyPilot job (#8123).
- Shadeform documentation (#7916), EKS tagging for
sky serve(#8141). - Restrict overly permissive S3 IAM permissions in docs (#8642).
- Private registry secrets on k8s (#8372), GCP private registry hint (#8377).
- Revamped installation page (#8183), updated Jobs Recovery docs (#8571), PodIP port mode documentation (#6211), consolidation mode docs (#8195).
Testing & CI/CD
- Memory benchmark in smoke tests (#8161).
- Dashboard performance tests (#8227).
- Slurm tests enabled in nightly builds (#8875).
- Release workflow support for RC process (#8710).
- Fixed critical OpenSSL vulnerability in Docker image (#8756).
- Numerous test reliability and flakiness fixes.
Contributors
Thank you to all contributors who made this release possible!
@aflah02, @alex000kim, @andylizf, @atoniolo76, @aylei, @bilelomrani1, @Bokki-Ryu, @cblmemo, @cg505, @concretevitamin, @dan-blanchard, @DanielZhangQD, @haimmarko-lgtm, @hentt30, @huksley, @ibrahimnd2000, @Jayachander123, @Jobarion, @kevinmingtarja, @kevinzwang, @kyuds, @liuwb, @lloyd-brown, @lucamanolache, @m-braganca, @Michaelvll, @nakinnubis, @ngi, @oelachqar, @oliviert, @otutukingsley, @panf2333, @Philmod, @php-workx, @qicz, @rohansonecha, @romilbhardwaj, @SalikovAlex, @seahyinghang8, @SeungjinYang, @smwaqas89, @williamsnell, @wurambo, @zpoint
New Contributors:
- @Bokki-Ryu made their first contribution in #8134
- @aflah02 made their first contribution in #8093
- @qicz made their first contribution in #7890
- @dan-blanchard made their first contribution in #8037
- @nakinnubis made their first contribution in #8401
- @otutukingsley made their first contribution in #8289
- @seahyinghang8 made their first contribution in #8503
- @hentt30 made their first contribution in #8546
- @php-workx made their first contribution in #8175
- @Philmod made their first contribution in #8556
- @liuwb made their first contribution in #8614
- @m-braganca made their first contribution in #8481
- @atoniolo76 made their first contribution in #8224
- @oelachqar made their first contribution in #8653
- @panf2333 made their first contribution in #8657
- @Jayachander123 made their first contribution in #8683
- @Jobarion made their first contribution in #8827
- @bilelomrani1 made their first contribution in #8930
- @oliviert made their first contribution in #8645
- @ibrahimnd2000 made their first contribution in #8893
- @huksley made their first contribution in #8180
- @ngi made their first contribution in #8987
- @wurambo made their first contribution in #9000
- @smwaqas89 made their first contribution in #8998
- @williamsnell made their first contribution in #9059
- @haimmarko-lgtm made their first contribution in #9041
Special thanks to the community for bug reports, feature requests, and pull requests that helped improve SkyPilot!
Full Changelog
For a complete list of changes, see the commit history.