Apache Kafka 4.0: KRaft, New Features, and Migration
Apache Kafka 4.0, released on March 18, 2025, represents a significant milestone in the evolution of this popular distributed event streaming platform. This major release introduces architectural transformations, feature enhancements, and performance improvements while marking the end of legacy components. The most prominent change is the complete removal of ZooKeeper dependency, with KRaft (Kafka Raft) becoming the exclusive metadata management solution. This comprehensive guide explores the new features, changes, and best practices for Apache Kafka 4.0.

The most significant change in Kafka 4.0 is the complete removal of Apache ZooKeeper dependency[8][9]. After serving as Kafka's backbone for over a decade, ZooKeeper is being replaced by KRaft (Kafka Raft) mode as the sole metadata management protocol[1][7][8]. This architectural shift streamlines Kafka's deployment and management processes by eliminating the need to maintain a separate ZooKeeper ensemble[8][14].
KRaft mode, which became production-ready in Kafka 3.6, offers several advantages:
-
Simplified cluster management and deployment
-
Enhanced scalability for larger clusters
-
Improved reliability and metadata management
-
Reduced operational overhead
The transition to KRaft represents a fundamental paradigm shift in how Kafka manages its distributed coordination and metadata storage[17]. By integrating these functions directly into Kafka, the system becomes more self-contained and easier to manage[8].
For users planning to upgrade to Kafka 4.0, migration from ZooKeeper-based clusters to KRaft mode is mandatory[16][15]. The migration path depends on your current Kafka version:
-
If running Kafka 3.3.x through 3.9.x in KRaft mode: Direct upgrade to 4.0 is possible
-
If running Kafka 3.3.x through 3.9.x in ZooKeeper mode: Migrate to KRaft first, then upgrade to 4.0
-
If running Kafka versions older than 3.3.x: Upgrade to version 3.9.x first, then migrate to KRaft, before upgrading to 4.0[16]
The dynamic KRaft quorums introduced in Kafka 3.9 serve as a "bridge release" to Kafka 4.0, enabling the addition or removal of controller nodes without downtime[1].
Kafka 4.0 delivers the general availability of KIP-848, which introduces a powerful new consumer group protocol designed to dramatically improve rebalance performance[8][18]. This enhancement addresses one of the long-standing pain points in Kafka deployments, particularly in large-scale systems. Benefits include:
-
Significantly reduced downtime during rebalances
-
Lower latency for consumer operations
-
Enhanced reliability and responsiveness of consumer groups
-
Improved scalability for large consumer group deployments[8]
An exciting addition to Kafka 4.0 is the early access to Queues for Kafka (KIP-932), which enables Kafka to support traditional queue semantics directly[8][18]. This feature extends Kafka's versatility beyond its traditional pub/sub model:
-
Support for point-to-point messaging patterns
-
Compatibility with traditional queue-based applications
-
Broader range of use cases without requiring additional messaging systems[8]
Several KIPs (Kafka Improvement Proposals) enhance client reliability and protocol functionality:
-
KIP-1102 : Enables clients to rebootstrap based on timeout or error code, enhancing resilience by proactively triggering metadata rebootstrap when updates don't occur within a timeout period[8]
-
KIP-896 : Removes old client protocol API versions, requiring broker version 2.1 or higher before upgrading Java clients to 4.0[8][16]
-
KIP-1124 : Provides a clear Kafka Client upgrade path for 4.x, outlining the upgrade process for Kafka Clients, Streams, and Connect[8]
Kafka 4.0 raises the minimum Java version requirements across its components:
-
Kafka Clients and Kafka Streams now require Java 11
-
Kafka Brokers, Connect, and Tools now require Java 17[8]
These changes align Kafka with modern Java development practices and security requirements.
The Log4j appender, deprecated in earlier versions, is completely removed in Kafka 4.0, completing the transition to Log4j2[1][14][15]. This change:
-
Addresses security vulnerabilities such as Log4Shell
-
Aligns with modern logging practices
-
Improves logging performance and capabilities[1]
MirrorMaker 1, which was deprecated in Kafka 3.0, is officially removed in Kafka 4.0[1][15]. Users must migrate to MirrorMaker 2 or alternative mirroring tools before upgrading to version 4.0.
KIP-1104 enhances Kafka Streams by allowing foreign keys to be extracted directly from both record keys and values[8]. This removes the need to duplicate keys into values for foreign-key joins, providing:
-
Simplified joins
-
Reduced storage overhead
-
More intuitive developer experience[8]
The introduction of the ProcessorWrapper interface (KIP-1112) simplifies the application of cross-cutting logic in Kafka Streams[8]. This feature:
-
Enables seamless injection of custom logic around Processor API and DSL processors
-
Eliminates redundancy
-
Reduces maintenance overhead from manually integrating logic into each processor[8]
Additional enhancements to Kafka Streams include:
-
KIP-1065 : Adds a "RETRY" option to
ProductionExceptionHandler, allowing users to break retry loops with customizable error handling[8] -
KIP-1091 : Improves Kafka Streams operator metrics, adding state metrics for each StreamThread and client instance for detailed visibility into application state[8]
|
Parameter |
Description |
Recommendation |
|---|---|---|
| replica.lag.time.max.ms |
Controls when replicas are considered out of sync |
Balance between reliability and performance; tune based on network conditions[11] |
| num.network.threads |
Number of threads for network requests |
Increase for high-throughput scenarios[11] |
| num.io.threads |
Number of threads for disk I/O |
Adjust based on storage performance[11] |
| segment.ms |
Time before rolling to a new log segment |
Avoid setting too low to prevent "Too many open files" errors[6] |
| request.timeout.ms |
How long clients wait for broker response |
Default is 30 seconds; setting too low can cause unnecessary failures[6] |
-
Setting **
request.timeout.ms** too low : This can cause unnecessary client failures when brokers are under load[6] -
Misunderstanding producer retries : Configure retries appropriately to ensure message delivery reliability[6]
-
Excessive partitioning : While more partitions enable parallelism, they increase replication latency and server overhead[11]
-
Setting **
segment.ms** too low : This creates many small segment files, potentially causing file handle exhaustion and performance degradation[6] -
Unmonitored broker metrics : Regularly monitor key metrics like network throughput, open file handles, and JVM stats[2]
When designing Kafka applications, a common question is whether to use a single topic for multiple entities or create separate topics. The best practice is typically to use a single topic with appropriate partitioning rather than creating many topics[12]. This approach:
-
Avoids hitting limits on the number of topics
-
Reduces file handle consumption
-
Improves overall cluster performance
-
Simplifies management and monitoring[12]
The number of partitions directly impacts performance and scalability:
-
More partitions : Greater parallelization and throughput
-
Too many partitions : Increased replication latency, longer rebalances, more open server files[2]
A balanced approach based on throughput requirements and consumer parallelism is recommended.
Spring for Apache Kafka is being updated to support Kafka 4.0:
-
Spring for Apache Kafka 4.0.0-M1 is available, compatible with Spring Framework 7.0.0-M3[10]
-
Spring for Apache Kafka 3.3.4 is compatible with Kafka Client 3.9.0[10]
-
Spring Boot users can override Kafka Client versions as needed[10]
Redpanda, a Kafka-compatible alternative written in C++, offers a different implementation with similar capabilities:
|
Feature |
Kafka |
Redpanda |
|---|---|---|
| Protocol Compatibility |
Native |
Compatible with Kafka protocol |
| Language |
Java |
C++ |
| Metadata Management |
KRaft (formerly ZooKeeper) |
Built-in Raft consensus |
| Messaging Capabilities |
Pub/sub with partition-level ordering |
Same as Kafka |
| Ecosystem |
Large, mature ecosystem |
Compatible with Kafka ecosystem |
| Stream Processing |
Kafka Streams, ksqlDB |
Limited native capabilities |
While Redpanda aims to be compatible with the Kafka protocol, there's no guarantee that all Kafka components will behave the same way when used with Redpanda[5].
Apache Kafka 4.0 represents a significant evolution of the platform, with the removal of ZooKeeper dependency being the most transformative change. The adoption of KRaft mode simplifies deployment while improving scalability and reliability. Other enhancements like the new consumer group protocol, queue support, and Streams API improvements further expand Kafka's capabilities.
Organizations planning to upgrade should carefully assess their current deployments, ensure compatibility with the new requirements, and consider a phased migration approach. With these changes, Kafka continues to evolve as a central component in modern data architectures, maintaining its position as the leading distributed event streaming platform.
As with any major release, testing in a non-production environment before upgrading production systems is strongly recommended, with particular attention to the ZooKeeper to KRaft migration process for existing clusters.
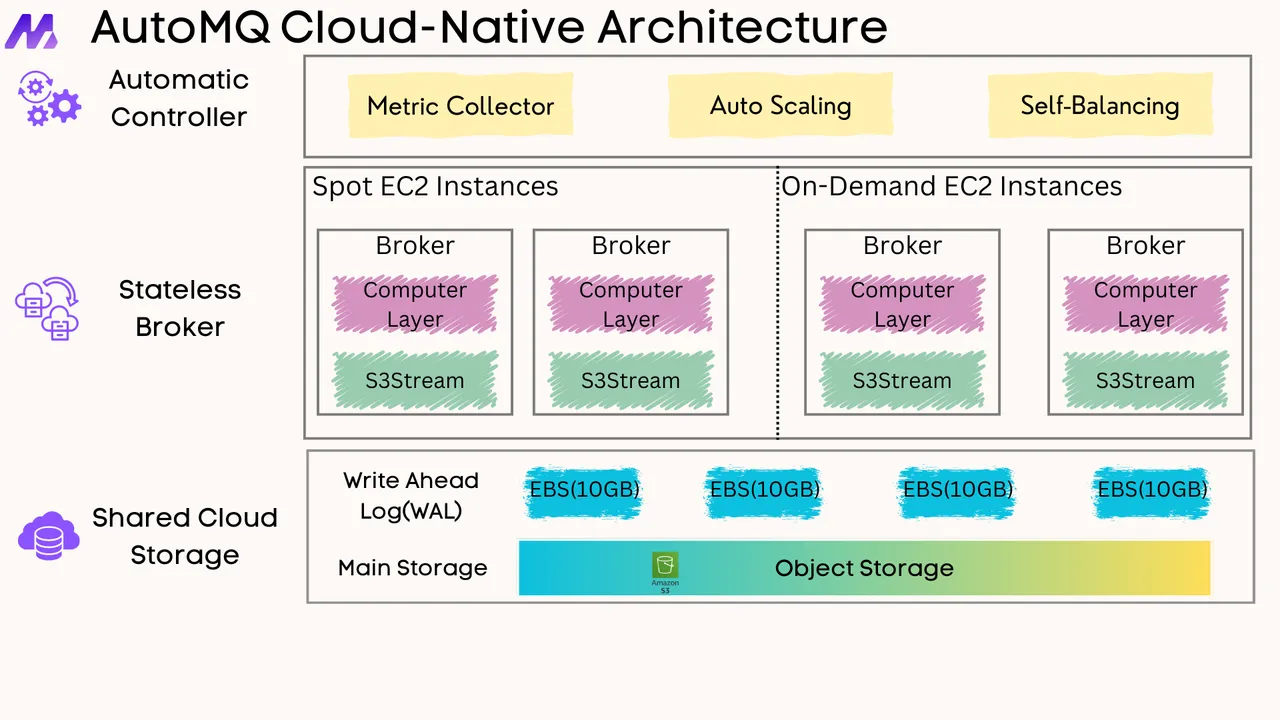
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging