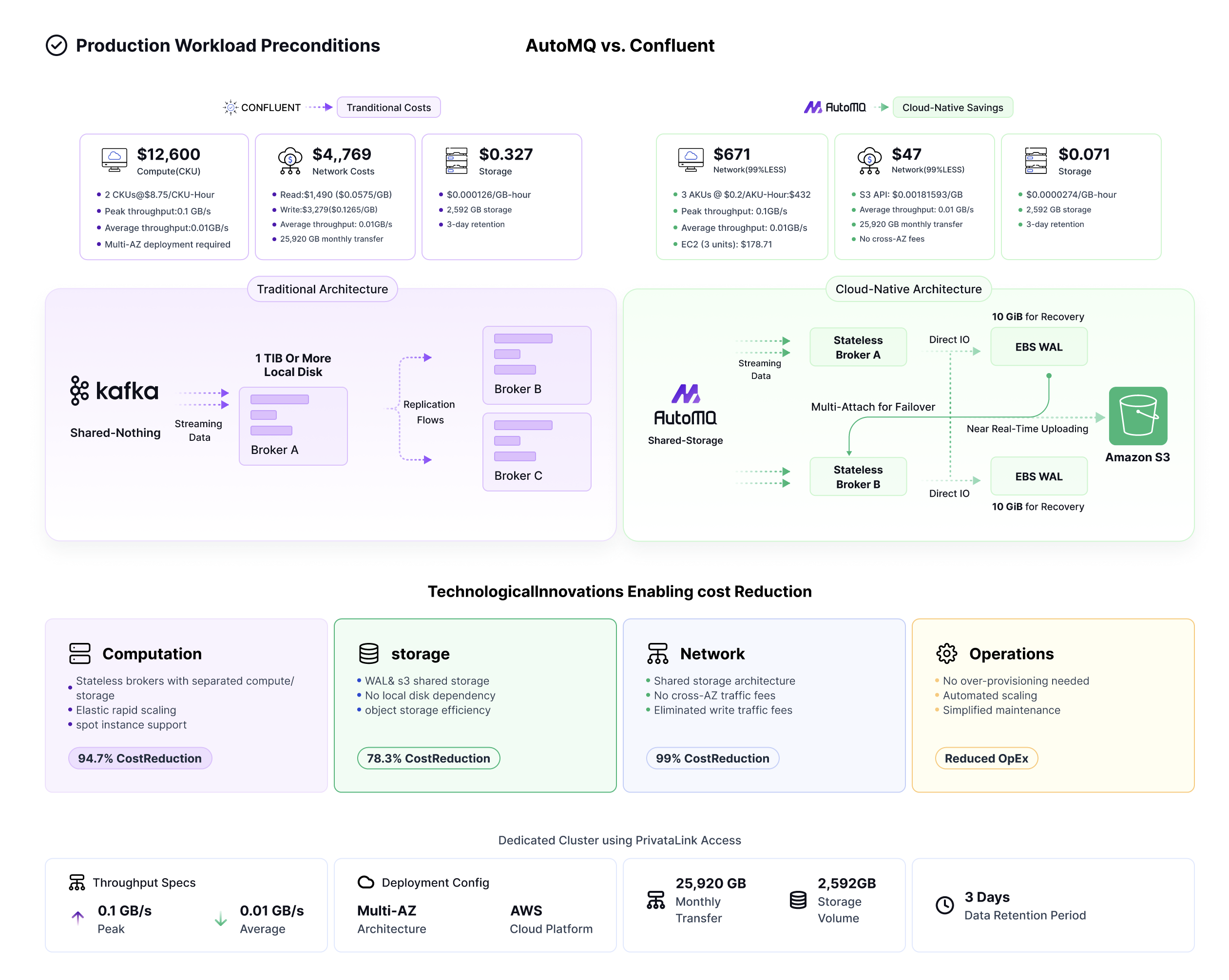
AutoMQ vs. Confluent: Pricing Comparison
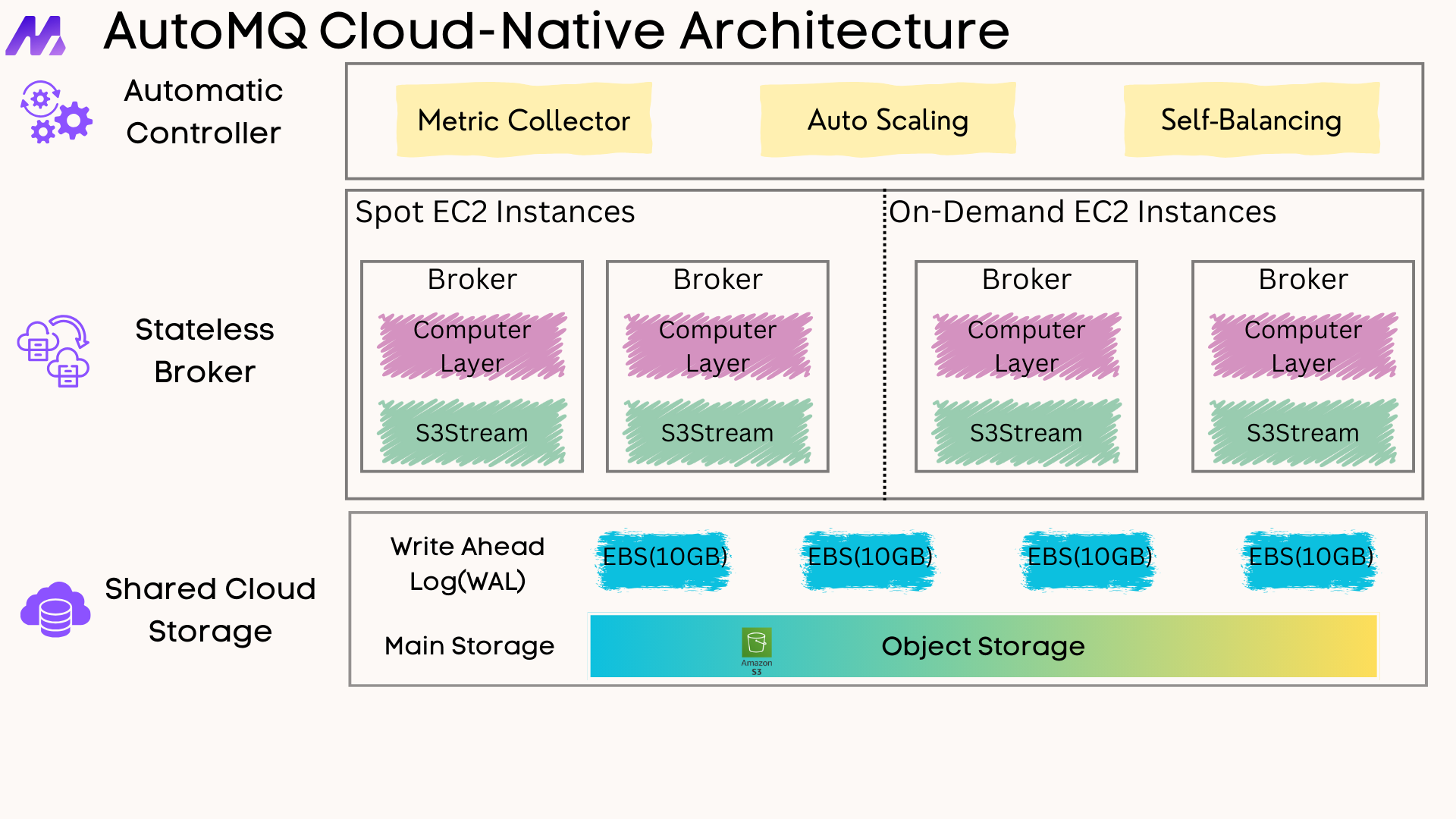
AutoMQ is a next-generation Kafka built for the cloud. The source code for the community version is available on GitHub(https://github.com/AutoMQ/automq). With an innovative architecture based on EBS WAL and S3 shared storage architecture, AutoMQ offers better cost efficiency, scalability, and performance compared to Kafka.
Confluent is an enterprise-grade stream data platform built on Apache Kafka, created by the original development team of Kafka. It aims to extend Kafka's capabilities, providing a more comprehensive data stream processing solution. Its core products, Confluent Platform and Confluent Cloud, enhance the Kafka ecosystem by integrating features like the stream processing database ksqlDB, enterprise-grade connectors, Schema Registry, and support for multi-language development. Additionally, it offers elastic scalability and hybrid cloud deployment, while strengthening security controls (such as SSL and RBAC) and ensuring exactly-once processing semantics.
The following diagram illustrates how AutoMQ leverages technical innovations to reduce costs by over 90% compared to Confluent, without any performance degradation, under typical production workloads. These technical innovations primarily include:
-
Stateless Brokers decouple computing from storage
-
Resource optimization can be achieved by using elastic scaling or spot instances.
-
Shared Storage eliminates cross AZ Traffic Fees
-
Minimize network overhead with optimized S3 writes.
-
Save time and money with Amazon S3 Write-Ahead logging (WAL), shared storage, and Amazon S3 .
-
It eliminates the need for costly local disks.
-
Automated scaling eliminates over-provisioning.
-
Simplified maintenance reduces operating overhead.