Kafka Linking: Migration Kafka with Zero Downtime
AutoMQ Kafka Linking represents a significant advancement in Kafka migration technology, offering organizations the ability to transfer their data and metadata from existing Kafka deployments to AutoMQ with zero downtime. This report examines the key features, advantages, and workflow of AutoMQ Kafka Linking based on technical documentation.
AutoMQ Kafka Linking is built directly into the AutoMQ platform, eliminating the need for additional components like Connectors or third-party tools. This integration makes the migration process fully automated and significantly reduces the operational complexity typically associated with Kafka migrations1. The fully managed nature of the solution means that organizations can initiate migrations with minimal technical overhead or specialized knowledge.
One of the most powerful capabilities of AutoMQ Kafka Linking is its ability to migrate both data and metadata from source Kafka clusters. The solution provides Offset-Preserving Replication, ensuring that all consumer offsets are maintained during the transition1. This comprehensive approach allows for the smooth transition of consumers, Flink jobs, Spark jobs, and other infrastructure to the new clusters without disruption or data loss.
Perhaps the most significant feature of AutoMQ Kafka Linking is its support for zero-downtime migration. Unlike alternative solutions that require stopping producers and consumers during the migration process, AutoMQ allows for continuous operation throughout the transition1. This capability is particularly valuable for mission-critical applications where even brief outages can have significant business impacts.
When compared to other Kafka migration solutions such as Confluent's Cluster Linking and Mirror Maker 2 (MM2), AutoMQ Kafka Linking demonstrates several notable advantages:
|
Feature |
AutoMQ Kafka Linking |
Confluent Cluster Linking |
Mirror Maker 2 |
|---|---|---|---|
| Zero-downtime Migration |
Yes |
No |
No |
| Offset-Preserving |
Yes |
Yes |
Limited |
| Fully Managed |
Yes |
No |
No |
The comparative analysis reveals that AutoMQ Kafka Linking provides a more comprehensive migration solution, particularly for organizations prioritizing business continuity during migrations1. Neither Confluent's Cluster Linking nor Mirror Maker 2 can achieve zero-downtime migration like AutoMQ, as they typically require stopping producers or consumers while the target cluster synchronizes all data and metadata.
The migration process with AutoMQ Kafka Linking follows a well-defined workflow designed to minimize risk and ensure data integrity:
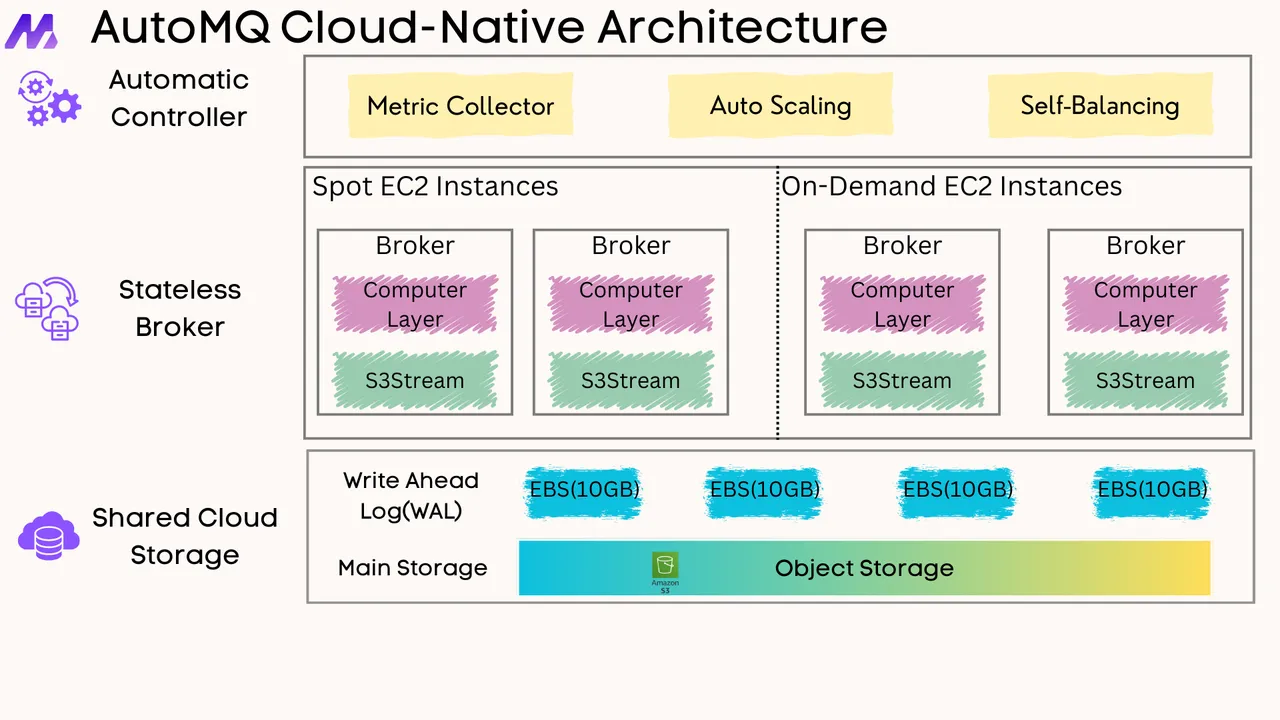
The process begins with configuring a Kafka Linking migration task in the AutoMQ console. During this initial setup, administrators need to:
-
Add source cluster access points, ACL, and other connection information
-
Select topics for migration (with support for wildcard selection and rule-based renaming)
-
Specify initial synchronization points
-
Provide consumer group ID information for the cluster being migrated1
This preparation phase establishes the foundation for a successful migration by defining the scope and parameters of the operation.
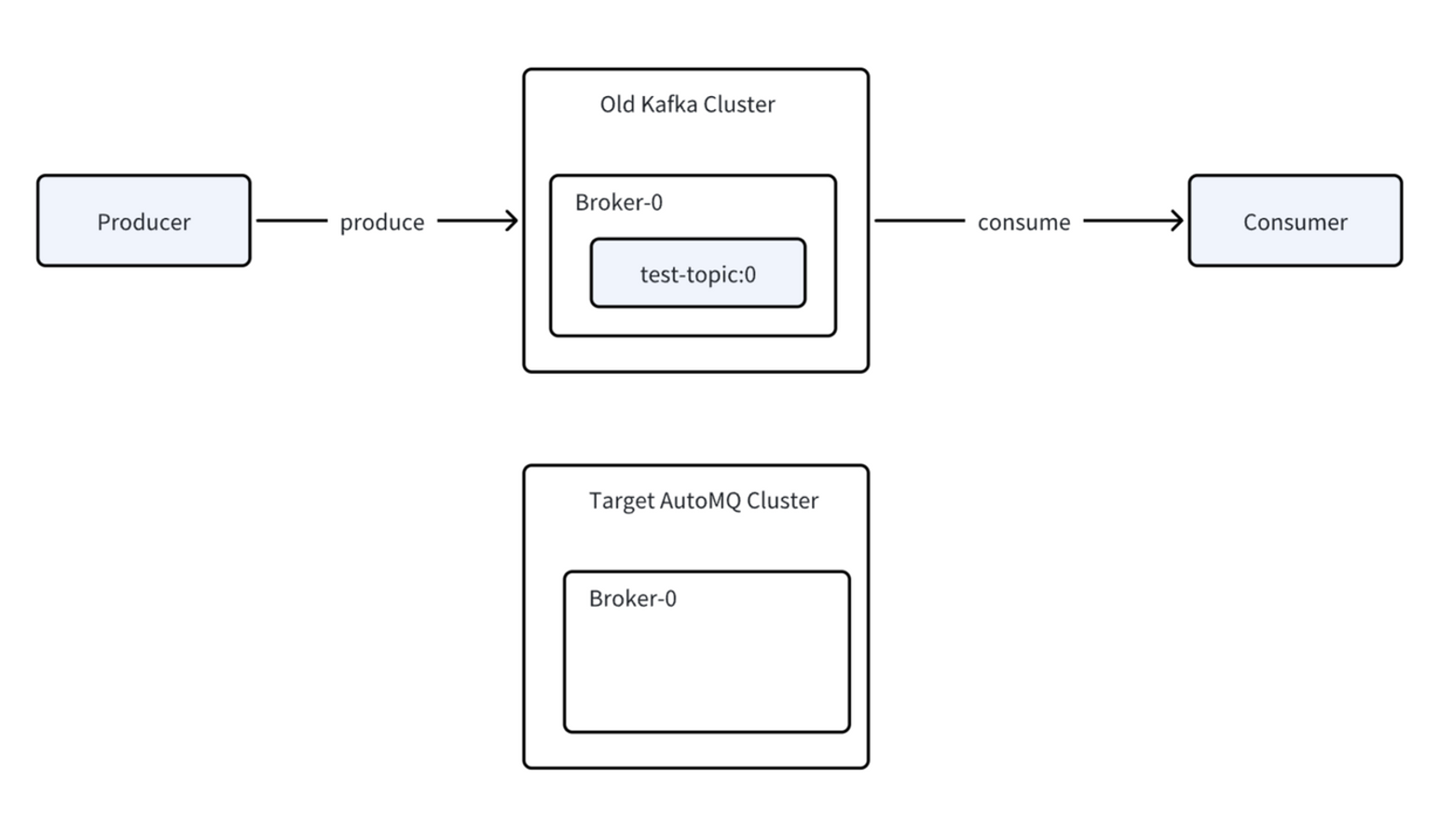
Once configured, the migration task is started through the console. During this phase, Kafka Linking automatically creates the necessary topics and consumer groups on the target cluster. The built-in migration task then begins automatically migrating data and offsets between clusters1. This automation eliminates many of the manual steps typically required in traditional migration approaches.
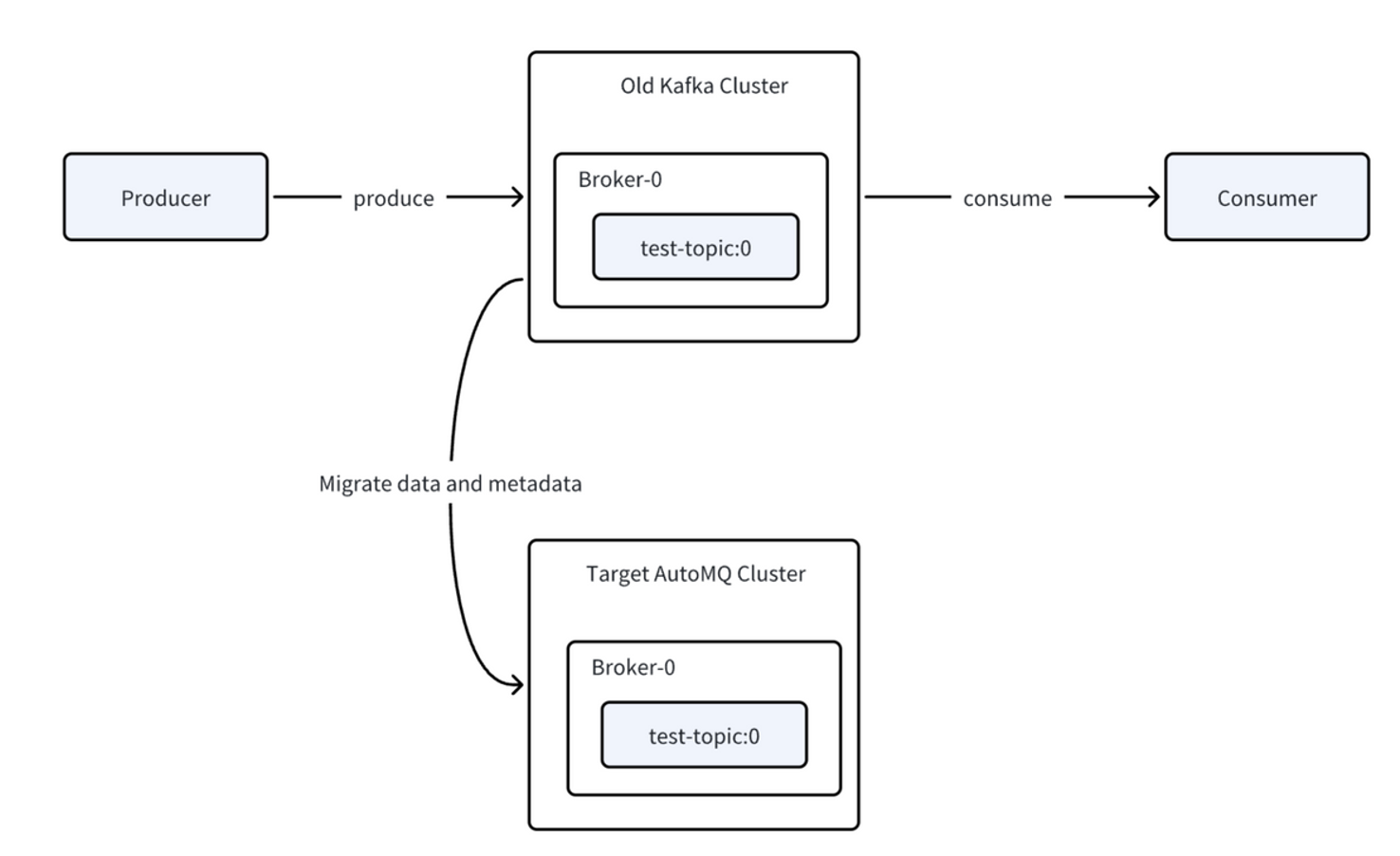
Users can choose whether to migrate producers or consumers first, though the documentation recommends starting with producers for easier rollback if issues arise. When producers are migrated to the new cluster, their data is automatically forwarded to the old cluster1. This means the AutoMQ cluster initially acts as a proxy, forwarding writes to the original cluster rather than writing directly to its own partitions, which preserves data ordering and integrity.
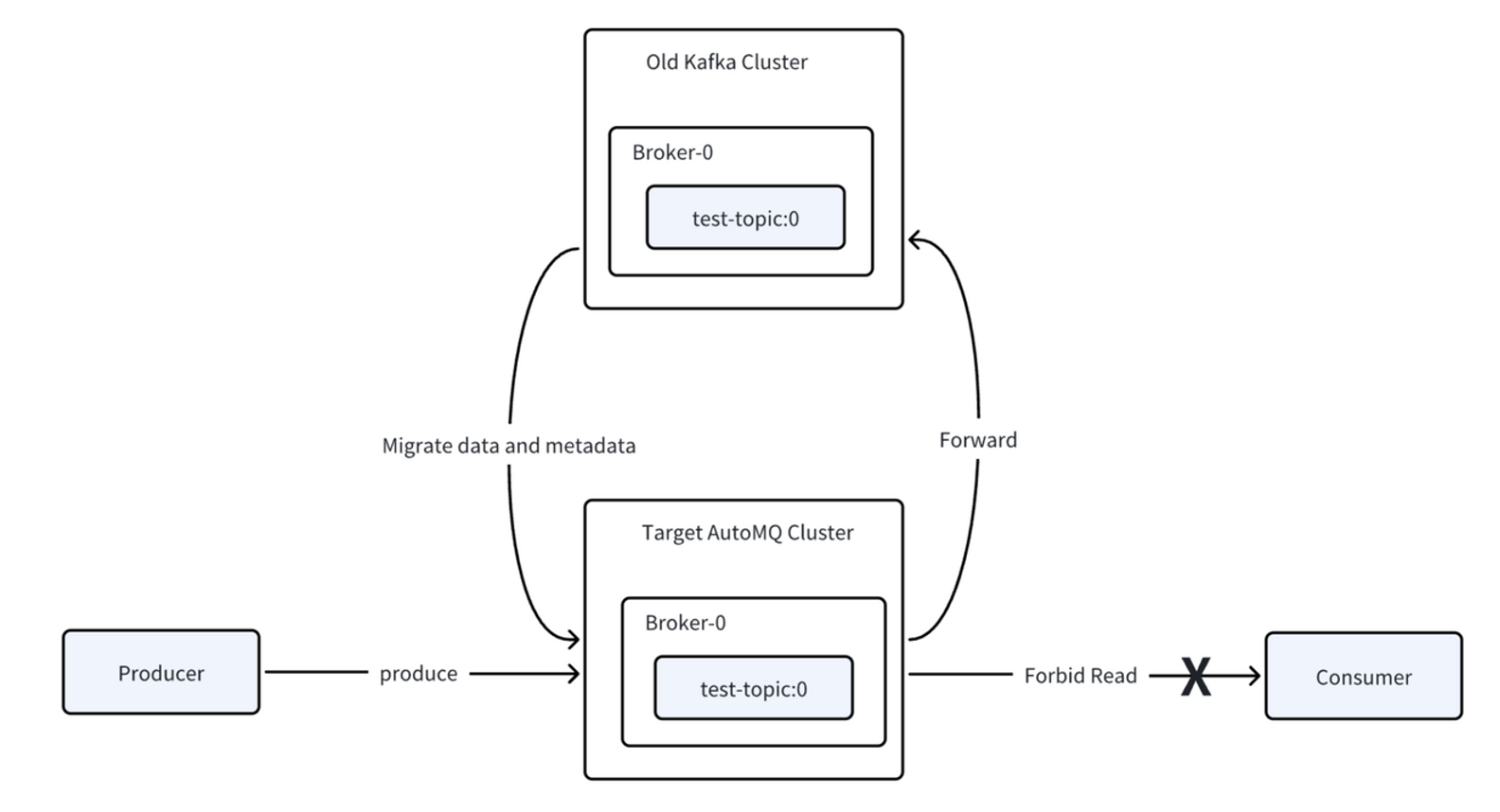
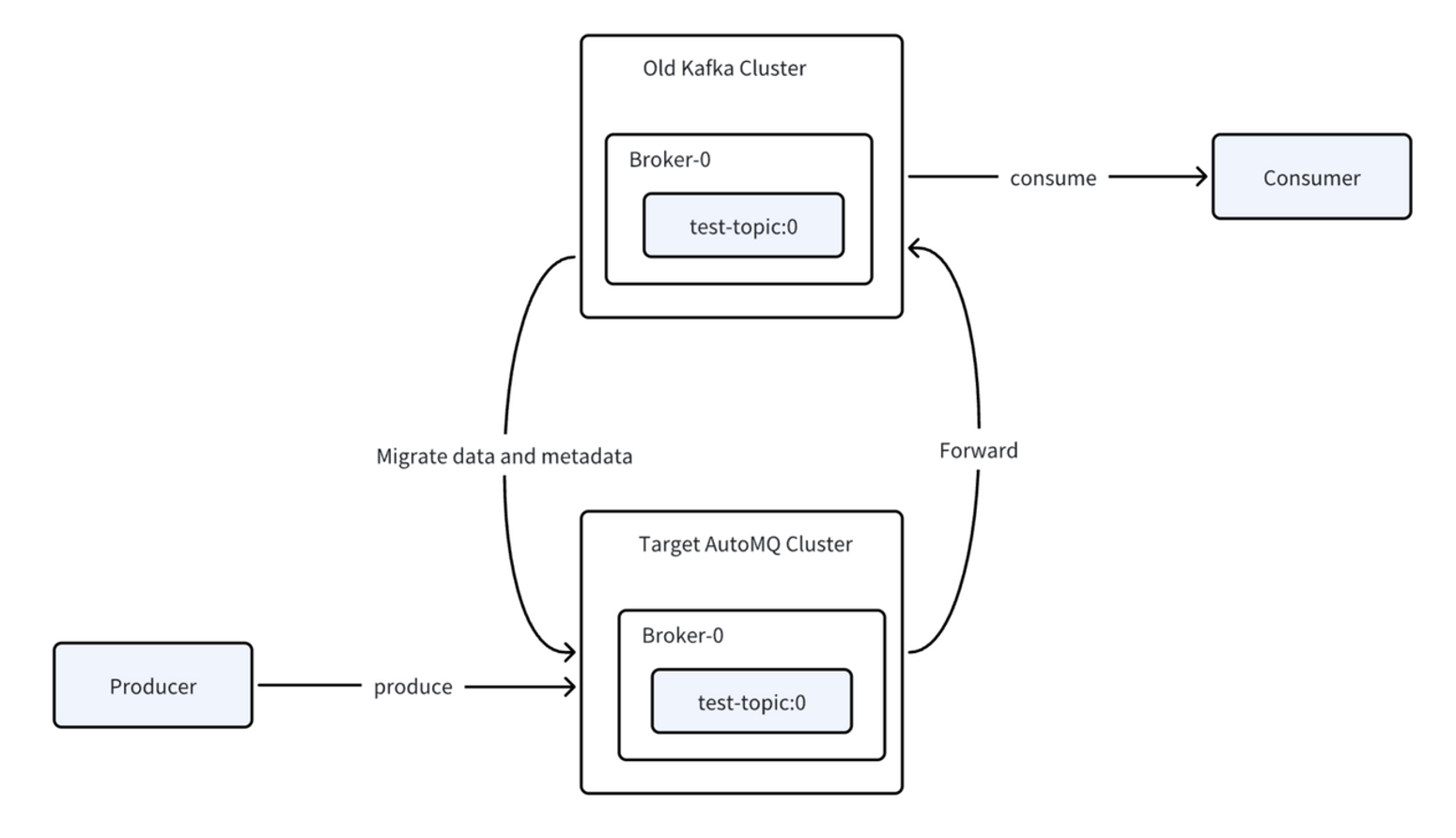
After confirming that producers are functioning properly, organizations can perform a rolling upgrade of consumer applications to connect them to the new cluster. At this stage, consumers connect to the new cluster but don't immediately begin consuming data1. Kafka Linking automatically monitors for specific preconditions before enabling consumption, ensuring that all consumer group members from the old cluster have successfully migrated to the new environment.
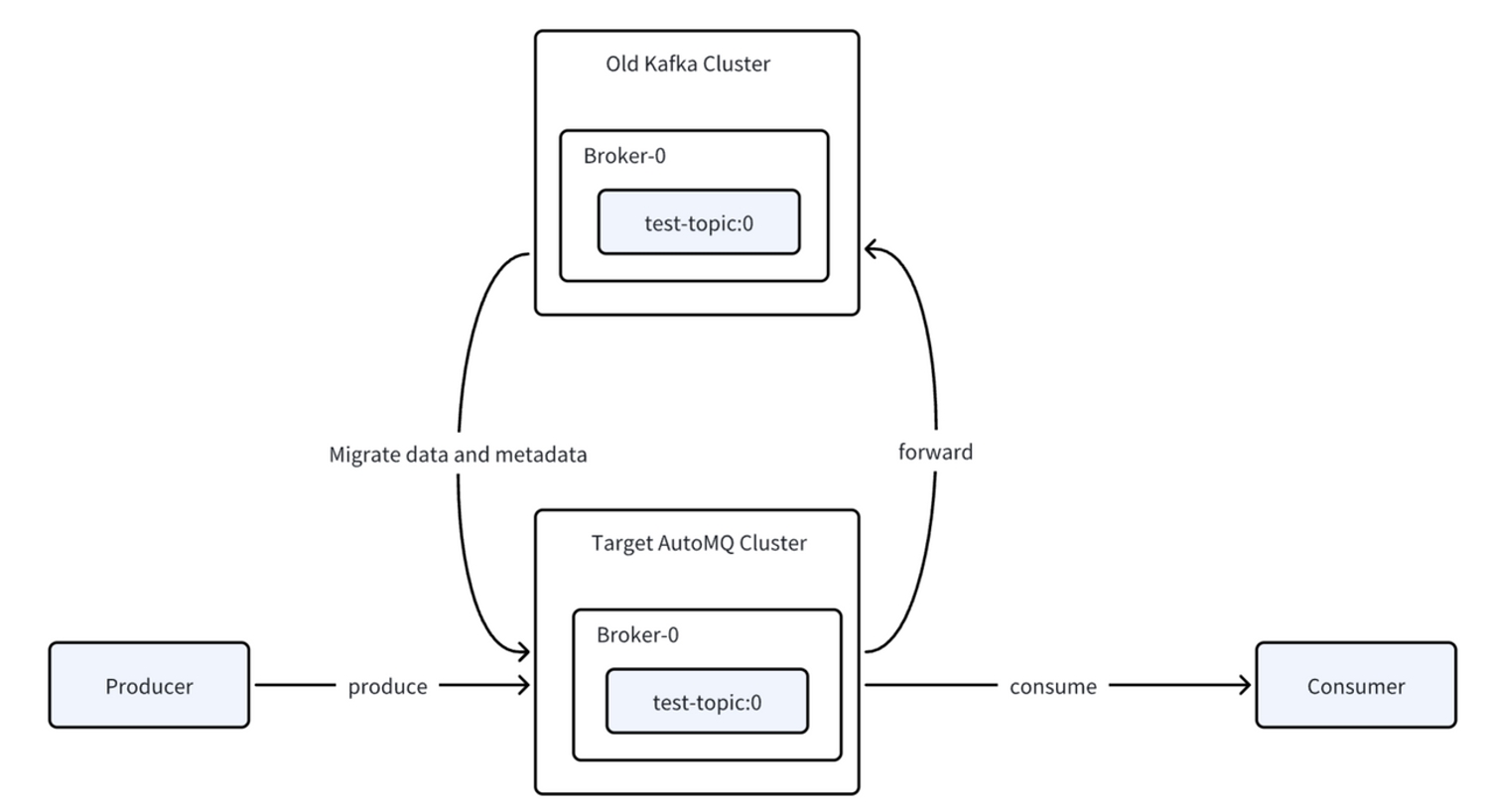
Once the migration preconditions are met, AutoMQ Kafka Linking automatically executes "group promotion," allowing consumers to begin actively consuming data from the new cluster1. This contrasts with Confluent's Cluster Linking, which requires manual intervention to trigger promotion after ensuring producers and consumers are stopped and mirroring lag reaches zero.
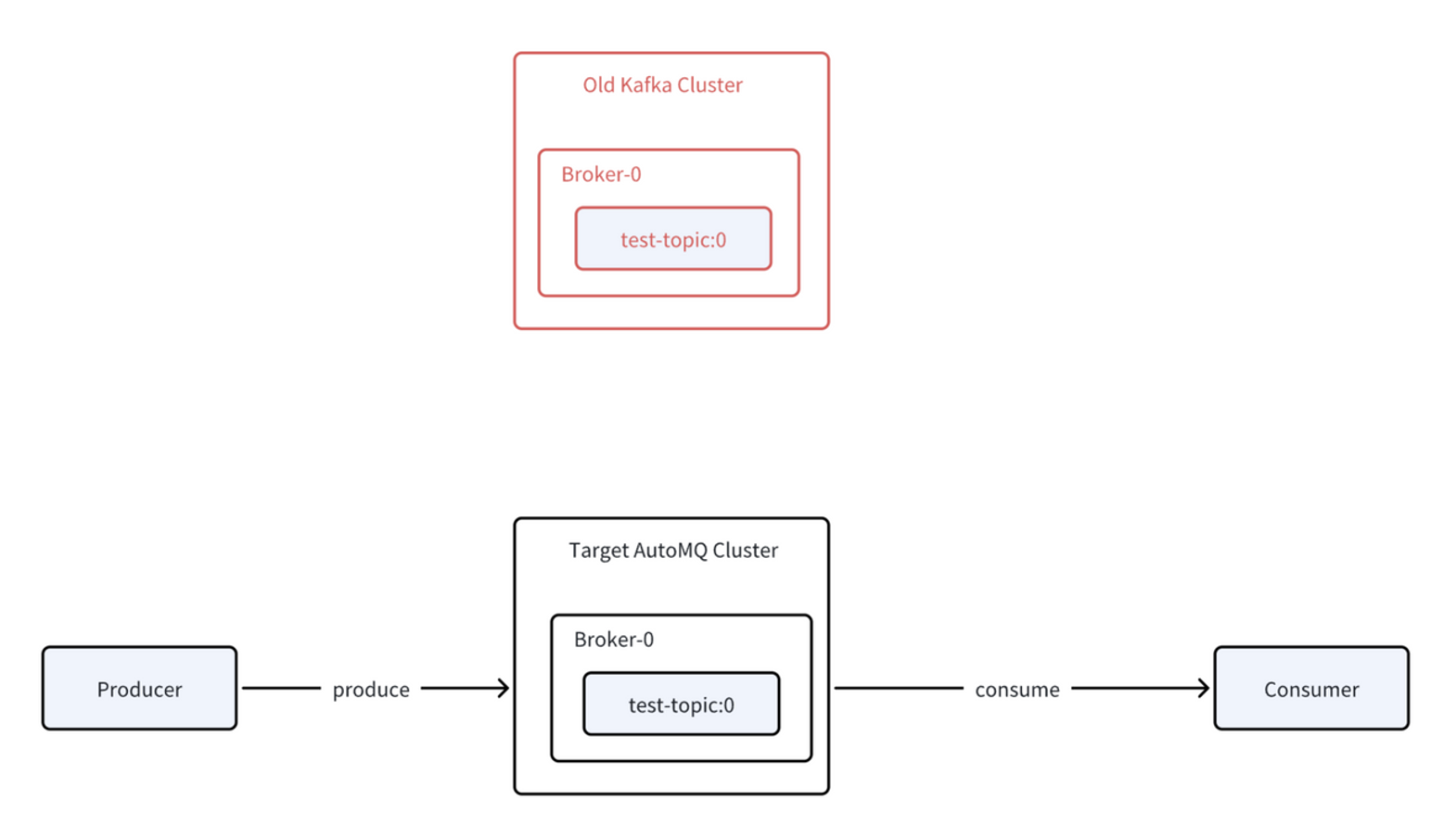
In the final phase, users can choose when to stop the migration task and disconnect synchronization between the old and new clusters. This operation, called "topic promotion" in Kafka Linking's implementation, automatically migrates any remaining data and metadata1. After this disconnection, the data and metadata on the AutoMQ cluster begin to truly serve client requests rather than acting as a proxy, and the old cluster can be safely decommissioned.
AutoMQ emphasizes that their solution is 100% compatible with Apache Kafka, meaning that existing Kafka migration work should apply equally to AutoMQ1. This compatibility helps reduce the risk of integration challenges when implementing AutoMQ Kafka Linking. The documentation notes that the solution has been successfully implemented with large enterprises like Grab and JD, providing evidence of its scalability and reliability in production environments.
AutoMQ Kafka Linking represents a significant advancement in Kafka migration technology, offering organizations a fully managed, zero-downtime approach to migrating Kafka workloads. By preserving offsets and providing automatic handling of migration complexities, it addresses many of the challenges typically associated with Kafka migrations. The clearly defined workflow and built-in automation reduce operational risk and technical complexity, making it a compelling option for organizations looking to migrate their Kafka deployments with minimal business disruption.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging