Lessons Learned from Confluent Kafka Kora
Kora represents Confluent's evolution of Apache Kafka into a truly cloud-native event streaming platform. As the engine powering Confluent Cloud, Kora has transformed how organizations deploy, manage, and scale Kafka in cloud environments. This blog examines the architecture, capabilities, and lessons learned from Confluent's development of Kora.
When Confluent Cloud launched in 2017, it was essentially open-source Kafka running on a Kubernetes-based control plane with basic billing and operational controls[1][5]. However, Confluent recognized that achieving their vision for Kafka in the cloud required building a platform specifically designed for cloud environments rather than simply adapting the existing technology.
Kora emerged as a response to these challenges, engineered from the ground up as a cloud-native event streaming platform. Today, Kora powers over 30,000 Confluent Cloud clusters across AWS, Google Cloud, and Azure, serving thousands of customers with diverse workloads[5][8].
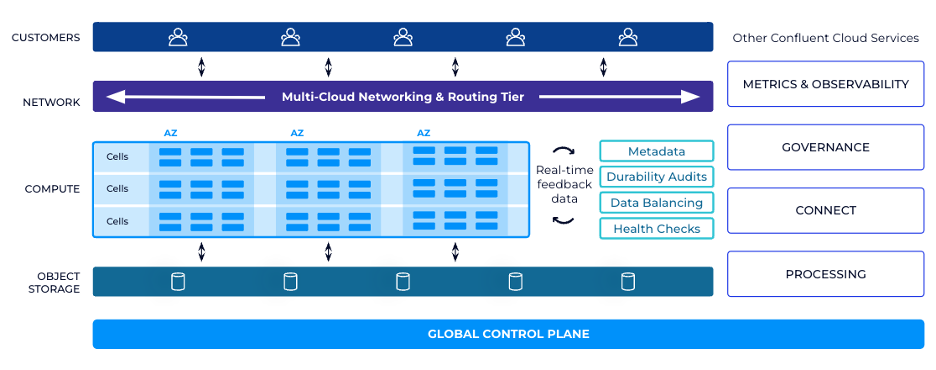
One of Kora's foundational design principles is the clear separation between control plane and data plane:
-
Control Plane : Centralized, running on Kubernetes, responsible for provisioning physical resources and initializing clusters across availability zones[2][4]
-
Data Plane : Decentralized, consisting of independent Physical Kafka Clusters (PKCs) that handle actual data processing[2]
This separation enhances scalability, reliability, and resource management by isolating operational concerns from data processing functions.
Kora was built with "multi-tenant first" as a core principle, supporting thousands of customers with strong isolation capabilities[5]:
-
The user-visible unit of provisioning is a Logical Kafka Cluster (LKC)
-
A single Physical Kafka Cluster (PKC) may host multiple LKCs
-
Each tenant receives proper isolation through authentication, authorization, and encryption[4]
This approach enables efficient resource utilization while maintaining performance boundaries between tenants.
Kora's network architecture significantly departs from traditional Kafka:
-
A stateless proxy layer in each PKC routes to individual brokers using Server Name Identification (SNI)
-
The proxy scales independently from brokers, preventing bottlenecks like port exhaustion
-
Network access rules and connection limits are enforced at the proxy layer[2][4]
Kora introduced two fundamental architectural changes that distinguish it from traditional Apache Kafka:
|
Component |
Apache Kafka |
Confluent Kora |
|---|---|---|
| Metadata Management |
ZooKeeper (or KRaft in newer versions) |
Internal topic using KRaft consensus |
| Storage Architecture |
Single-layer storage |
Tiered storage (memory, SSD, object storage) |
| Network Layer |
Direct broker connections |
Proxy-based routing with SNI |
| Cluster Management |
Manual or basic automation |
Fully automated with elastic scaling |
| Tenant Isolation |
Limited (separate clusters needed) |
Built-in multi-tenancy |
In traditional Kafka, a centralized controller manages cluster metadata and broker coordination, using ZooKeeper (or KRaft in newer versions) for leader election and configuration storage. Kora enhances this approach by:
-
Incorporating telemetry to collect fine-grained information about cluster load
-
Replacing ZooKeeper with an internal topic using the Kafka Raft (KRaft) protocol
-
Enabling faster leader election during failures[4]
Perhaps the most significant innovation in Kora is its tiered storage approach:
-
Replaces Kafka's traditional single-layer storage model with multiple tiers (memory, SSD, object storage)
-
Keeps hot data in memory or local storage for low latency
-
Tiers out older data to object storage in chunks
-
Retains data on SSD as a cache for some period
-
Dramatically reduces data movement during scaling operations[4][5]
Confluent developed the CKU resource model to provide consistent performance across diverse hardware configurations in different cloud providers. This abstraction allows customers to focus on their workload requirements rather than underlying infrastructure details[2][5].
Kora enables 30x faster scale-up and scale-down compared to traditional Kafka deployments[5]. This remarkable improvement comes from:
-
Tiered storage : Minimizing the amount of data that needs to be moved during scaling
-
Self-Balancing Clusters (SBC) : A component that collects metrics about load and rebalances by assigning new replicas
-
Dynamic resource allocation : Automatically adjusting resources based on workload demands[2][4]
Kora implements comprehensive monitoring with:
-
Component-level telemetry for key performance indicators
-
External health check monitors that track client-observed performance
-
Distinction between cluster-wide and fleet-wide metrics
-
A degradation detector that continuously monitors metrics and initiates mitigation actions when necessary[4]
Confluent claims that Kora delivers significantly better performance than traditional Apache Kafka on identical hardware:
-
Up to 10x faster tail latencies
-
Ability to handle GBps+ workloads and peak customer demands 10x faster
-
99.99% uptime SLA compared to typical self-managed Kafka deployments[7]
The operational efficiency gain is substantial—Confluent estimates they are approximately 1000x more efficient at operations than the average Kafka team[5].
Kora runs across more than 85 regions in three major clouds (AWS, GCP, and Azure)[5]. This multi-cloud capability required specific design considerations:
-
Unified experience across different cloud providers
-
Abstraction of cloud-specific differences
-
Standardized deployment and management processes
Kora employs sophisticated algorithms for tenant placement:
-
When creating a new tenant, Kora selects two available cells at random and assigns the tenant to the one with lower load
-
This approach avoids hotspots and balances load across infrastructure
-
When tenants grow and reach a cell's capacity, one or more tenants are migrated to less-loaded cells[5]
Kora implements advanced data durability protections:
-
Cluster Link : Enables replication between Kafka clusters, allowing for all data and metadata to be replicated without mapping consumer offsets[2]
-
Storage health manager : Monitors metrics around storage operations on each broker
-
Degradation detector : Continuously monitors cluster metrics and initiates mitigation actions
-
Backup and restore : Leverages object storage to provide data recovery capabilities[4]
As Kora utilizes KRaft mode for metadata management, here's a sample configuration:
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker
# The node id associated with this instance's roles
node.id=2
# The connect string for the controller quorum
controller.quorum.voters=1@controller1:9093,3@controller3:9093,5@controller5:9093
For production deployments, typical resource requirements include:
|
Component |
Nodes |
Memory |
|---|---|---|
| Broker |
3 |
64 GB RAM |
| KRaft controller |
5-Mar |
4 GB RAM |
| Control Center (Normal mode) |
1 |
32 GB RAM (JVM default 6 GB) |
| Control Center (Reduced infrastructure) |
1 |
8 GB RAM (JVM default 4 GB) |
In production environments, you should have a minimum of three brokers and three controllers for reliability[3].
-
Multi-AZ Deployment : Ensure replicas are distributed across availability zones for fault tolerance
-
Proper Sizing : Use the CKU model to appropriately size your clusters based on workload requirements
-
Monitoring : Implement comprehensive monitoring of both cluster-wide and tenant-specific metrics
-
Quota Management : Configure appropriate quotas to prevent "noisy neighbor" problems in multi-tenant environments
-
Network Configuration : Pay attention to network configuration, especially when implementing cross-region replication
For effective health monitoring:
-
Use Control Center to view processing status
-
Check the Administration menu
-
Monitor "About Control Center" for Processing Status (Running or Not Running)
-
Security configuration issues : Verify security configuration for all brokers, metrics reporters, client interceptors, and Control Center
-
Data corruption : Watch for InvalidStateStoreException, which typically indicates data corruption in the configured data directory
-
Insufficient resources : Monitor for resource constraints across brokers and controllers
Recent developments suggest Kora may continue to evolve significantly. Confluent's acquisition of Warpstream, another cloud-native Kafka solution, indicates potential changes in Kora's future trajectory[9]. Industry observers speculate that Kora might evolve to incorporate Warpstream technologies while maintaining compatibility with existing deployments.
The development of Kora demonstrates several critical lessons for cloud-native event streaming platforms:
-
Separation of concerns between control and data planes enables better scalability
-
Multi-tenancy by design is essential for efficient cloud resource utilization
-
Tiered storage provides significant advantages for elasticity and cost optimization
-
Cloud-native architecture requires rethinking fundamental components rather than simply adapting existing solutions
-
Performance optimization for cloud environments demands different approaches than on-premise deployments
These lessons continue to influence the evolution of event streaming platforms, with Kora setting new benchmarks for cloud-native Kafka deployments.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
-
Paper Notes: Kora - A Cloud-Native Event Streaming Platform for Kafka
-
Introducing Kora: The Cloud-Native Data Streaming Engine Powering Confluent Cloud
-
Current 2023: Deep Dive into Kora - The Cloud Native Kafka Engine
-
Kora: A Cloud-Native Event Streaming Platform for Kafka (VLDB Paper)
-
Kora: A Cloud-Native Event Streaming Platform for Kafka (ACM)
-
Kora: A Cloud-Native Event Streaming Platform for Kafka - Daily.dev