Self Hosted Kafka vs Managed Kafka: Differences in Deploye
Apache Kafka has become a cornerstone technology for real-time data streaming and event processing. Organizations must choose between self-hosting Kafka or utilizing fully managed services—a decision with significant implications for operations, performance, security, and costs. This comprehensive comparison examines both approaches through five critical dimensions to help you make an informed choice for your specific needs.
Apache Kafka deployments fall into two primary categories: self-hosted and fully managed. Self-hosted Kafka involves complete responsibility for infrastructure, configuration, and maintenance, while managed services offload these responsibilities to a third-party provider[1].
Self-hosted (or "do-it-yourself") Kafka deployment puts you in full control of your infrastructure. You're responsible for setting up hardware, installing and configuring Kafka, maintaining the system, and handling all operational aspects[2]. This approach requires significant expertise but offers maximum control over your environment.
Managed Kafka services provide automated provisioning, maintenance, and scaling of Kafka clusters. Providers like Confluent Cloud, AWS MSK, Google Managed Service for Apache Kafka, and Redpanda manage the underlying infrastructure so you can focus on building data pipelines rather than operational details[1][3].

The initial setup and ongoing management requirements differ significantly between self-hosted and managed Kafka.
|
Aspect |
Self-Hosted Kafka |
Managed Kafka |
|---|---|---|
| Initial Setup |
Complex setup requiring hardware provisioning and configuration |
Simplified setup with automated provisioning |
| Infrastructure Management |
Complete responsibility for hardware, networking, and cluster infrastructure |
Managed by provider with minimal infrastructure overhead |
| Scaling |
Manual scaling requiring additional hardware and configuration |
On-demand or automatic scaling with simple UI/API controls |
| Maintenance & Upgrades |
Full responsibility for patches, updates, and upgrades |
Automatic updates and maintenance managed by the provider |
| Version Control |
Complete control over versioning decisions |
Updates controlled by provider with limited version selection |
| Configuration Flexibility |
Highly customizable with complete control over all parameters |
Limited to provider-supported configurations and parameters |
| Monitoring & Alerts |
Requires additional tools for comprehensive monitoring |
Built-in monitoring dashboards and alerting systems |
| Support Options |
Community support, optional enterprise support contracts |
Included technical support with tiered SLAs based on plan |
Self-hosted Kafka provides complete control but requires significant expertise to set up and maintain. Organizations must handle everything from broker configuration to disaster recovery planning. In contrast, managed services automate these processes, allowing teams to create clusters in minutes rather than days or weeks[1].
Performance considerations vary significantly between deployment models, with important tradeoffs in control versus convenience.
|
Aspect |
Self-Hosted Kafka |
Managed Kafka |
|---|---|---|
| Performance Control |
Full control over hardware and performance tuning |
Limited to provider-offered instance types and settings |
| Latency |
Potentially lower with optimized hardware and network |
May be higher due to multi-tenancy and cloud networking |
| Throughput |
Dependent on deployed hardware capabilities |
Easily scalable based on provider capabilities |
| Scalability Limits |
Limited by available hardware and operational expertise |
Typically higher with elastic infrastructure |
| Multi-Region Support |
Possible but requires complex configuration and management |
Often simpler with provider's global infrastructure |
| Hardware Optimization |
Can be specifically optimized for workload characteristics |
Limited to available instance types from provider |
| Network Optimization |
Full control over network configuration and optimization |
Subject to provider's network architecture |
| Resource Utilization |
Often lower due to overprovisioning for peak loads |
Often higher with pay-per-use and autoscaling capabilities |
Self-hosted Kafka often outperforms cloud-based deployments in terms of latency, particularly for real-time applications where milliseconds matter[8]. A benchmark conducted by UpCloud showed significant performance variations across cloud providers, with AWS MSK delivering 280,000 messages/second compared to 535,000 messages/second on UpCloud at comparable configurations[14].
Security and compliance requirements significantly influence deployment choices, especially for organizations in regulated industries.
|
Aspect |
Self-Hosted Kafka |
Managed Kafka |
|---|---|---|
| Access Control |
Custom implementation of ACLs and security policies |
Pre-configured security controls with simplified management |
| Data Encryption |
Manual configuration of TLS/SSL and encryption settings |
Built-in encryption often enabled by default |
| Authentication Options |
Flexible but requires manual setup (SASL, OAuth, etc.) |
Pre-integrated authentication mechanisms |
| Network Security |
Full control but requires expertise to implement properly |
Provider-managed security with limited customization |
| Compliance Certifications |
Self-certification requiring extensive documentation |
Provider maintains certifications (SOC2, ISO, etc.) |
| Audit Logging |
Requires additional tooling for comprehensive logging |
Built-in audit logging and retention |
| Vulnerability Management |
Manual patching and security updates |
Automatic security patches and updates |
| Data Sovereignty |
Complete control over data location and governance |
Limited to provider's available regions |
For organizations with strict regulatory requirements, self-hosted Kafka offers greater control over data residency and compliance measures[8]. However, managing security properly requires significant expertise, while managed services provide pre-configured security controls and maintain industry-standard certifications[9].
Cost structures differ fundamentally between self-hosted and managed Kafka deployments.
|
Aspect |
Self-Hosted Kafka |
Managed Kafka |
|---|---|---|
| Cost Model |
Capital expenditure (CAPEX) focused |
Operational expenditure (OPEX) focused |
| Initial Investment |
High upfront costs for hardware and infrastructure |
Low to no upfront costs |
| Operational Costs |
Ongoing costs for infrastructure, maintenance, and operations |
Subscription or usage-based pricing |
| Staffing Requirements |
Requires specialized expertise and dedicated operations team |
Reduced need for specialized operations staff |
| Scaling Costs |
Step costs with hardware purchases and scaling operations |
Linear costs based on usage with no step costs |
| Cost Predictability |
More predictable for stable workloads |
Less predictable with variable usage patterns |
| Resource Efficiency |
Often lower with properly sized deployments |
Pay-for-use model can be more efficient |
| Total Cost of Ownership |
Lower for very large scale and long-term stable deployments |
Lower for small-to-medium deployments and variable workloads |
Self-hosted Kafka involves significant upfront investment but can be more cost-effective for stable, predictable workloads over the long term[8]. Google Cloud's managed Kafka service costs approximately $1.1K/month for 10 MiB/s bandwidth and $11K/month for 100 MiB/s bandwidth[4], while Confluent claims TCO savings of up to 60% with their managed service compared to self-hosted deployments[16].
For managed services, optimizing costs requires careful monitoring and resource planning. Amazon MSK customers can reduce costs by leveraging sustained-use discounts, optimizing instance types, using storage tiering, and implementing effective monitoring[13].
The optimal deployment model depends on your specific use case and organizational requirements.
|
Scenario |
Recommended Option |
Rationale |
|---|---|---|
| Small development team with limited ops resources |
Managed Kafka |
Reduces operational burden and eliminates need for specialized expertise |
| Large enterprise with existing datacenter |
Self-Hosted Kafka (with dedicated team) |
Leverages existing infrastructure and may have lower TCO at scale |
| High compliance requirements with strict data sovereignty |
Self-Hosted Kafka (for maximum control) |
Provides complete control over data location and security practices |
| Startups and growing businesses |
Managed Kafka |
Allows focus on product development rather than infrastructure |
| Variable/unpredictable workloads |
Managed Kafka (for elasticity) |
Autoscaling capabilities handle traffic spikes without overprovisioning |
| Stable, predictable workloads |
Self-Hosted Kafka (for cost efficiency) |
Optimized infrastructure utilization for known workload patterns |
| Multi-region deployment requirements |
Managed Kafka (for simplified global deployment) |
Simplified configuration for global replication and disaster recovery |
| Businesses with limited Kafka expertise |
Managed Kafka |
Reduces learning curve and risk of misconfiguration |
Many organizations adopt a hybrid approach, combining self-hosted and managed Kafka to leverage the strengths of both models[7]. This strategy enables:
-
Running latency-sensitive workloads on-premises while using the cloud for scalable, less sensitive tasks
-
Cost optimization by utilizing on-premises resources for steady-state operations and cloud for handling peak loads
-
Enhanced disaster recovery with redundancy across both environments
-
Gradual migration to the cloud while maintaining control over critical data and processes
Whether self-hosted or managed, operating Kafka comes with challenges that should inform your decision-making[9].
-
Scalability and Resource Management - Determining proper sizing and scaling horizontally to meet demand
-
Performance Tuning - Balancing throughput and latency requirements
-
Data Retention and Management - Implementing effective storage policies
-
Monitoring and Observability - Setting up comprehensive monitoring systems
-
Broker Management and Failures - Handling broker failures and resource allocation
-
Security and Access Control - Implementing proper authentication and authorization
-
Schema Management - Managing schema evolution across applications
-
Data Governance and Compliance - Implementing data governance frameworks
-
Upgrades and Maintenance - Managing upgrades without downtime
-
Multi-Cluster Deployments - Coordinating across multiple clusters for geo-redundancy
Managed services address many of these challenges but introduce new considerations around integration, cost management, and vendor lock-in[10].
The choice between self-hosted and managed Kafka depends on your organization's specific requirements, expertise, and resources. Self-hosted Kafka offers maximum control, customization, and potential cost savings for stable workloads but requires significant operational expertise. Managed Kafka services provide simplicity, reduced operational overhead, and flexibility but may incur higher costs for large-scale deployments.
For organizations with existing data center infrastructure and specialized expertise, self-hosted Kafka may be more cost-effective in the long run. For startups, small teams, or organizations prioritizing development speed over infrastructure management, managed services offer a compelling alternative.
Many organizations are now adopting hybrid approaches, combining the benefits of both models to optimize for performance, cost, and operational efficiency. As Kafka continues to evolve, weighing these tradeoffs carefully will ensure you select the deployment model that best aligns with your organizational goals and constraints.
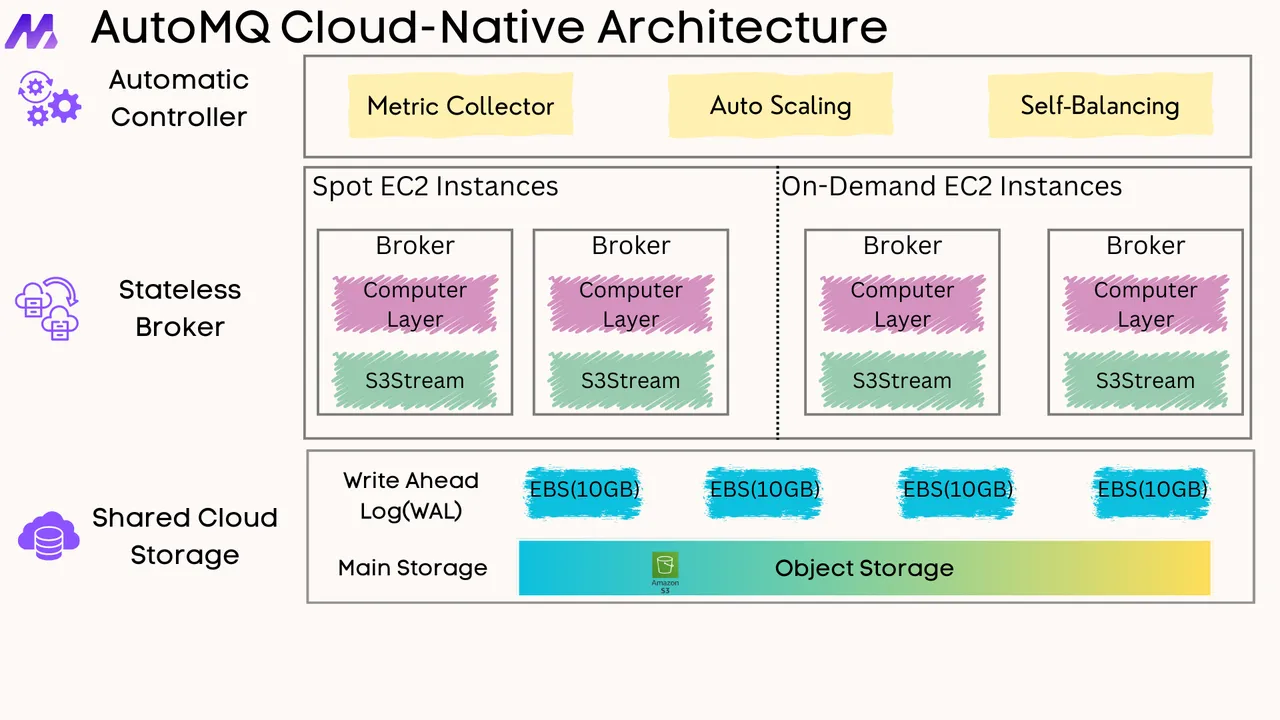
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
[1] Kafka Cloud vs Managed Kafka Guide
[2] Kafka on Kubernetes: DIY or Managed Option?
[3] Confluent Kafka vs Apache Kafka
[4] Google Cloud Managed Service for Apache Kafka Pricing
[5] Apache Kafka Cluster: Key Components and Building Your First Cluster
[6] Kafka Architecture and Cluster Guide
[7] Kafka Cloud vs On-Premise: Weighing the Pros and Cons
[8] The Continued Relevance of On-Premises Apache Kafka
[9] Top 10 Operational Challenges in Managing Kafka
[10] Re-evaluating Kafka: Issues and Alternatives for Real-time
[11] Getting Started with Confluent Cloud: A Beginner's Guide
[12] Confluent Cloud vs Amazon MSK: Comparing Managed Kafka Services
[13] Amazon MSK vs Redpanda: TCO Comparison
[14] Benchmarking Kafka with Aiven: Cloud Provider Comparison
[15] Migrating from On-Premise to Cloud with Cloudera
[16] Improving Kafka ROI and TCO with Confluent Cloud
[17] Running Confluent on Google Kubernetes Engine
[18] Using Conduktor with Aiven for Apache Kafka
[19] Redpanda vs Kafka Comparison
[20] 12 Kafka Best Practices: Run Kafka Like the Pros
[21] Common Confluent Operator Deployment Patterns
[22] Conduktor Platform: Kafka GUI and Management Tool
[23] Redpanda vs Kafka: A Detailed Comparison
[24] Kafka on Kubernetes: Integration Strategies and Best Practices
[25] Deployment Options for Apache Kafka
[26] Confluent Platform Deployment Guide
[27] Conduktor Platform Configuration Example
[28] Redpanda vs Kafka: In-depth Analysis
[29] Apache Kafka Best Practices for Deployment Optimization
[30] Confluent vs Apache Kafka vs Aiven Comparison
[31] Understanding Apache Kafka
[32] Apache Kafka vs Conduktor Comparison
[33] Will Redpanda Replace Apache Kafka?
[34] Post-deployment Tasks for Confluent Platform
[35] Apache Kafka Case Studies
[36] Dedicated Servers for Apache Kafka
[37] Enterprise Eventing Platform Using Kafka: Case Study
[38] When Not to Choose Google Apache Kafka for BigQuery
[39] Apache Kafka on AWS: Features, Pricing, and Best Practices
[40] Confluent Cloud: Fully Managed Kafka Streaming
[41] Solving Complex Kafka Issues: Enterprise Case Studies
[42] Confluent Cloud on Microsoft Azure
[43] Kafka Edge Infrastructure Deployment Guide
[44] Optimizing Costs for AWS Managed Kafka
[45] Comparing Apache Kafka Distributions
[46] Kafka Edge Computing Use Cases
[47] Choosing Between Pub/Sub and Kafka
[48] Apache Kafka Documentation
[50] Understanding Kafka ZooKeeper
[51] Red Hat AMQ Streams KRaft Mode Guide
[52] Hardware Requirements for Production
[54] What Is an Apache Kafka Cluster?
[55] Apache Kafka KRaft Mode Setup
[56] Confluent Platform System Requirements
[57] Apache Kafka Architecture
[58] Should ZooKeeper Be Run on Independent Machines?
[60] Hardware Requirements for Apache Kafka
[61] Apache Kafka Architecture: What You Need to Know
[62] Understanding Kafka Clusters