Apache Kafka Tutorial: Introduction for Beginners
Apache Kafka has established itself as a cornerstone technology for building real-time data pipelines and streaming applications. This comprehensive guide explores the fundamentals of Kafka, its architecture, core concepts, and practical implementation details to help beginners understand and work with this powerful distributed streaming platform.
Apache Kafka is an open-source distributed event streaming platform designed to handle high-throughput, real-time data feeds. Originally developed at LinkedIn to process massive amounts of user interaction data, Kafka has since evolved into a robust solution used by over 80% of Fortune 100 companies[1]. It serves as a central nervous system for modern data-driven organizations, enabling them to collect, store, process, and analyze streams of events at scale.
Kafka provides three key capabilities that make it uniquely powerful:
-
Publishing and subscribing to streams of records (similar to a message queue)
-
Storing streams of records durably and reliably
-
Processing streams of records as they occur or retrospectively[2]
Unlike traditional messaging systems that typically delete messages after consumption, Kafka maintains a configurable retention period for all published records, making it possible to replay data streams and reprocess information when needed. This fundamental design choice enables Kafka to serve both real-time applications and batch processing systems with the same underlying infrastructure.

Understanding Kafka's architecture requires familiarity with several key concepts:
At the heart of Kafka is the concept of an event (also called a message or record). An event represents something that happened in the world - such as a payment transaction, website click, sensor reading, or any other noteworthy occurrence. In Kafka, events are typically represented as key-value pairs, often serialized in formats like JSON, Avro, or Protocol Buffers[1].
Topics function as logical channels or categories to which events are published. They serve as the fundamental organizing principle in Kafka, allowing producers and consumers to focus only on relevant data streams. For example, a retail application might have separate topics for "orders," "inventory-updates," and "user-signups."[1].
Learn More : What is a Kafka Topic ? All You Need to Know & Best Practices▸
Each topic in Kafka is divided into partitions, which are ordered, immutable sequences of records. Partitions serve two critical purposes: they enable parallel processing by allowing multiple consumers to read from a topic simultaneously, and they distribute data across multiple servers for scalability and fault tolerance[8].
When messages have no specified key, they are distributed across partitions in a round-robin fashion. Messages with the same key are guaranteed to be sent to the same partition, ensuring ordered processing within that key[8].
Learn More: What is a Kafka Partition ? All You Need to Know & Best Practices▸
Brokers are the servers that form a Kafka cluster. Each broker hosts some of the partitions from various topics and handles requests from producers, consumers, and other brokers. A Kafka cluster typically consists of multiple brokers for redundancy and load distribution[9].
Learn More: Learn Kafka Broker: Definition & Best Practices▸
Producers are applications that publish events to Kafka topics. They can choose to specify which partition to send messages to or allow Kafka to handle distribution based on the message key[10].
Consumers are applications that subscribe to topics and process the published events. They maintain an offset (position) in each partition they consume, allowing them to control their position in the event stream[10].
Learn More: Apache Kafka Clients: Usage & Best Practices▸
Consumer groups allow a group of consumers to collaborate in processing messages from one or more topics. Kafka ensures that each partition is consumed by exactly one consumer in the group, facilitating parallel processing while maintaining ordered delivery within each partition[9].
Learn more: What is Kafka Consumer Group?▸
Traditionally, Kafka relied on Apache ZooKeeper for cluster coordination, metadata management, and leader election. However, recent versions of Kafka have introduced KRaft (Kafka Raft) mode, which eliminates the ZooKeeper dependency by implementing the coordination layer within Kafka itself[5][6].
Learn More:
Kafka's operation can be understood through several key mechanisms:
Kafka stores all published messages on disk, maintaining them for a configurable retention period regardless of whether they've been consumed. This persistence layer uses a highly efficient append-only log structure, allowing Kafka to deliver high throughput even with modest hardware[2].
To ensure fault tolerance, Kafka replicates partition data across multiple brokers. Each partition has one broker designated as the leader, handling all reads and writes, while other brokers maintain replicas that stay in sync with the leader. If a leader fails, one of the in-sync replicas automatically becomes the new leader[9].
When a producer publishes a message, it connects to any broker in the cluster, which acts as a bootstrap server. The broker provides metadata about topic partitions and their leaders, allowing the producer to route subsequent requests directly to the appropriate leaders.
Consumers operate similarly, first connecting to a bootstrap server to discover partition leaders, then establishing connections to those leaders to stream messages. Consumers track their position in each partition using offsets, which they periodically commit back to Kafka to enable resumption after failures[10].
Once your Kafka environment is running, you can begin producing and consuming messages:
The following command starts a console producer that allows sending messages to a topic:
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic myfirsttopic
>my first message
>my second message
Alternatively, you can write a producer application using Kafka's client libraries. Here's a simple Java example:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class SimpleProducer {
public static void main(String[] args) {
String topicName = "myfirsttopic";
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>(topicName, "key-"+i, "value-"+i));
}
producer.close();
}
}
This producer sends ten messages with keys and values to the specified topic[10].
To consume messages using the console consumer:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic myfirsttopic --from-beginning
For programmatic consumption, here's a simple Java consumer example:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class SimpleConsumer {
public static void main(String[] args) {
String topicName = "myfirsttopic";
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topicName));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Offset = %d, Key = %s, Value = %s%n",
record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
}
}
This consumer continuously polls for new messages and processes them as they arrive[10].
Implementing Kafka effectively requires adherence to several best practices:
-
Create topics with an appropriate number of partitions based on your throughput needs and consumer parallelism requirements
-
Use descriptive topic names that reflect the data they contain
-
Consider topic compaction for key-based datasets where only the latest value per key is needed
-
Set appropriate acknowledgment levels (
acks) based on your durability requirements:-
acks=0for maximum throughput with no durability guarantees -
acks=1for confirmation from the leader (potential data loss if leader fails) -
acks=allfor confirmation from all in-sync replicas (highest durability)
-
-
Enable idempotent producers to prevent duplicate messages
-
Configure batch size and linger time to optimize throughput
-
Design consumer groups carefully, considering throughput requirements and processing semantics
-
Implement proper error handling for consumer applications
-
Manage offsets explicitly for critical applications instead of relying on automatic commits
-
Set appropriate values for
max.poll.recordsandmax.poll.interval.msbased on your processing requirements
-
Monitor consumer lag to identify processing bottlenecks
-
Track broker health metrics including disk usage, CPU, and memory
-
Implement alerting for critical conditions such as under-replicated partitions
-
Regularly review and adjust partition counts as your application scales
Kafka's versatility makes it suitable for numerous applications:
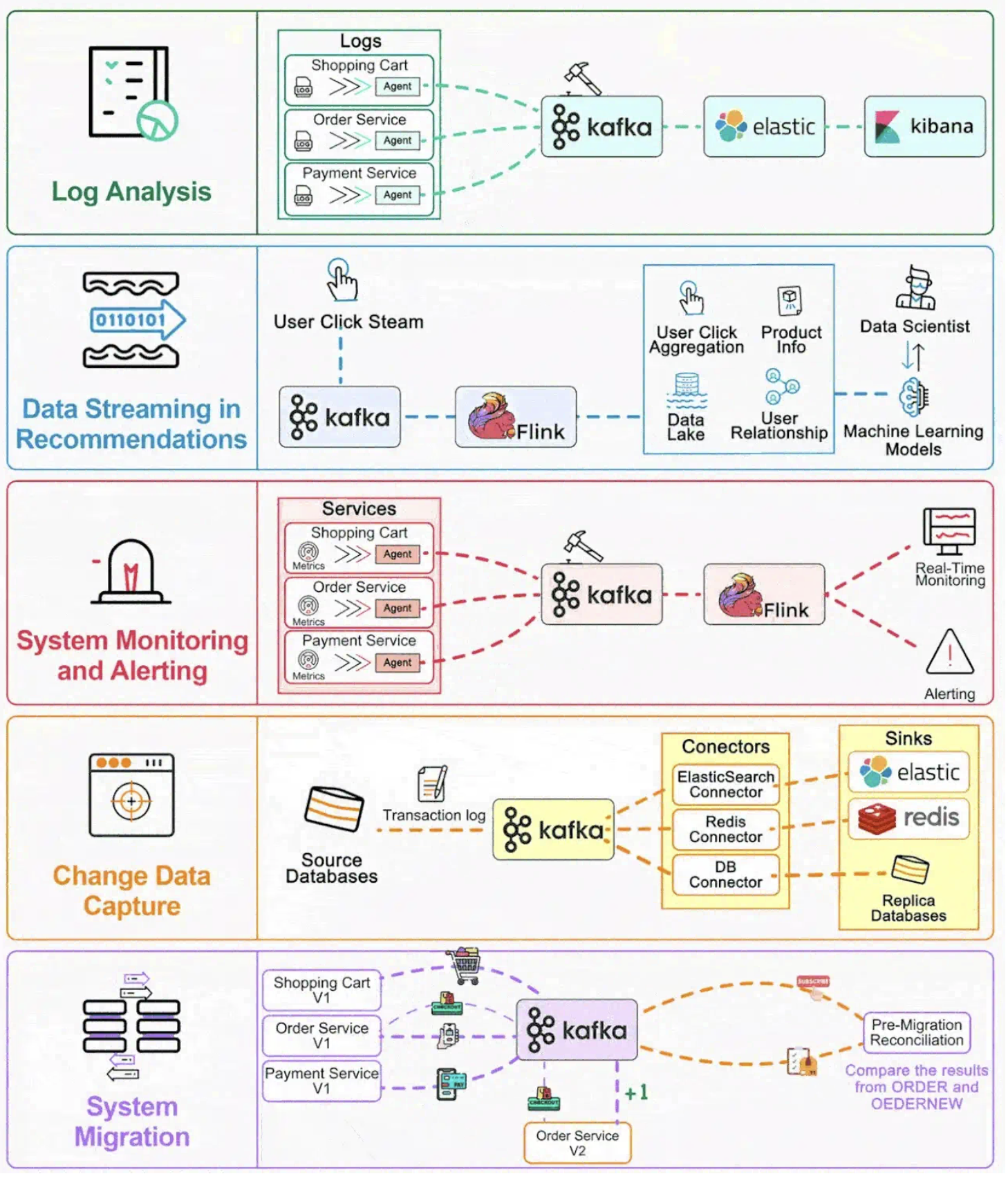
Kafka excels at moving data between systems in real-time, serving as the backbone for ETL processes, change data capture, and data integration patterns.
Organizations use Kafka to facilitate communication between microservices while maintaining loose coupling and enabling system-wide event sourcing.
Combined with processing frameworks like Kafka Streams or Apache Flink, Kafka enables real-time analytics, complex event processing, and continuous transformation of data streams.
Kafka's ability to handle high-volume event streams makes it ideal for collecting user activity data, application metrics, logs, and system telemetry.
Apache Kafka provides a robust foundation for building real-time data systems. Its unique combination of high throughput, scalability, and durability enables applications that were previously impractical with traditional messaging systems.
This tutorial has introduced the fundamental concepts, architecture, and practical aspects of working with Kafka. As you continue exploring Kafka, consider diving deeper into topics like security configuration, advanced stream processing with Kafka Streams, and integration with other data systems.
By mastering Kafka, you'll unlock powerful capabilities for building modern, event-driven applications that can process vast amounts of data with reliability and efficiency.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
