Kafka vs Quix: Comparing Data Streaming Technologies
Apache Kafka and Quix represent complementary technologies in the data streaming ecosystem, serving different but synergistic roles. While Kafka is a robust distributed streaming platform, Quix is a cloud-native library for processing data in Kafka, particularly tailored for Python developers. This analysis compares their architectures, features, performance profiles, and use cases to help you understand how they differ and potentially work together.
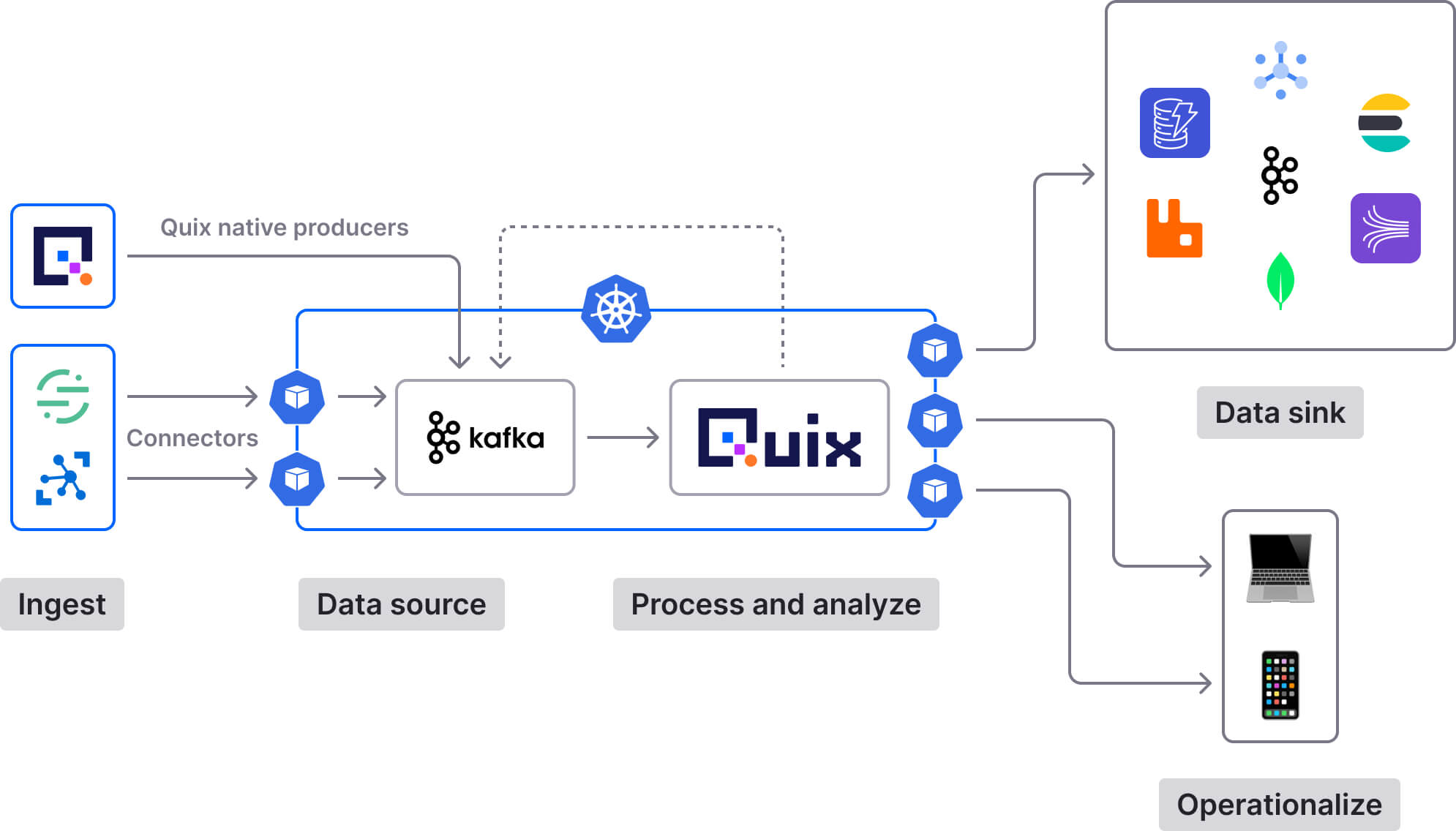
Apache Kafka is an open-source distributed event streaming platform designed to handle real-time data feeds with high throughput and low latency[10]. Originally developed by LinkedIn and later open-sourced, Kafka has become the foundation of many modern data architectures.
The Kafka architecture consists of these key components:
-
Producers : Applications that publish data to Kafka topics
-
Consumers : Applications that subscribe to topics and process the published data
-
Brokers : Servers that store data and serve client requests
-
Topics : Categories to which records are published
-
Partitions : Subdivisions of topics that enable parallelism
At its core, Kafka functions as a distributed commit log, where producers generate data and send it to brokers, while consumers read this data[7]. Each broker stores the actual data in topics, which can be divided into multiple partitions for scalability and fault tolerance.
Historically, Kafka relied on ZooKeeper for cluster management, but there's an ongoing effort to replace it with KRaft (Kafka Raft), which moves metadata management into Kafka itself[7]. This simplifies the architecture, reduces operational complexity, and improves scalability.
Kafka offers several distinctive features:
-
Distributed and Fault-Tolerant : Designed to scale horizontally across multiple nodes with data replication across brokers for high availability[10]
-
High Throughput and Low Latency : Optimized for processing hundreds of megabytes per second with millisecond latency[9]
-
Persistent Storage : Messages are persisted to disk, providing durability and enabling replay capabilities[10]
-
Stream Processing : Supports real-time data processing through Kafka Streams API[10]
-
Extensive Integration : Robust connector ecosystem for integrating with various data sources and sinks[10]
Kafka delivers exceptional performance compared to alternatives. In benchmark tests, Kafka achieved a peak throughput of 605 MB/s, significantly outperforming Pulsar (305 MB/s) and RabbitMQ (38 MB/s)[9]. At 200 MB/s load, Kafka maintained just 5 ms p99 latency, compared to Pulsar's 25 ms[9].
This performance advantage stems from Kafka's heavily optimized architecture, which leverages:
-
Linux page cache for efficient memory management
-
Zero-copy mechanism to minimize data copying
-
Sequential disk I/O patterns for high throughput
-
Efficient consumer implementation[9]
For optimal Kafka deployments, industry experts recommend:
-
Broker Configuration :
-
Configure appropriate log retention policies[16]
-
Properly size your cluster (typically 3+ brokers with 64 GB RAM each for production)[17]
-
Set up replication and redundancy correctly[16]
-
Carefully plan partition counts (more is not always better)[5]
-
-
Client Configuration :
-
For producers: Set
retriesto a high value,delivery.timeout.msto 60+ seconds, andacks=allfor durability[18] -
For consumers: Tune fetch settings and consumer count based on workload[6]
-
-
Common Optimizations :
-
Use compression for producers[5]
-
Adjust replication factors based on durability needs[5]
-
Tune network and I/O thread counts[5]
-
Monitor and address consumer lag proactively[6]
-
Quix Streams is a cloud-native library designed to make processing data in Kafka more accessible, particularly for Python developers[1]. It combines the scalability and resiliency features of Kafka in a highly abstracted interface.
The Quix architecture consists of:
-
Quix Streams : An open-source library that combines a Kafka client with stream processing capabilities
-
Quix Cloud : A managed platform for deploying and monitoring stream processing applications (optional)
In a typical implementation, Quix works as a complementary layer on top of Kafka:
-
Kafka serves as the messaging backbone, handling data ingestion and storage
-
Quix processes this data, transforming it on the fly and publishing results back to Kafka topics[4]
Quix offers several distinctive advantages:
-
Simplified Developer Experience : Provides a "Pythonic" DataFrame-like API similar to pandas for stream processing[15]
-
No Server-Side Engine : Eliminates the need for a separate orchestration layer[1]
-
Enhanced State Management : Backed by Kubernetes PVC for improved resiliency[1]
-
Flexible Data Support : Native handling for structured, semi-structured (time-series), and unstructured (binary) data[1]
-
Time-Centric Design : Treats time as a first-class citizen for real-time applications[1]
-
Processing Capabilities : Supports windowing, aggregations, filtering, and stateful operations[4]
Since Quix Streams wraps Confluent's Python Kafka client, its base performance characteristics for producing and consuming are similar[15]. However, Quix adds value through its stream processing capabilities rather than raw throughput.
Built by Formula 1 engineers with extensive experience in high-performance streaming systems, Quix can handle millions of messages per second with consistently low latencies in the millisecond range[15].
Configuring Quix applications primarily happens through the quixstreams.Application class with these key parameters:
-
Kafka Connection : Configure broker addresses or authentication details[12]
-
Consumer Group : Define group name for coordinated consumption[12]
-
Processing Guarantees : Choose between "at-least-once" or "exactly-once" semantics[12]
-
Commit Settings : Control frequency and conditions for offset commits[12]
-
Error Handling : Configure callbacks and recovery strategies[12]
Common issues to watch for include:
-
Kafka disconnections (monitor and implement appropriate reconnection logic)[13]
-
Configuration conflicts between broker address and SDK tokens[13]
-
Message size limitations[13]
|
Aspect |
Apache Kafka |
Quix |
|---|---|---|
|
Primary Role |
Distributed messaging platform and storage |
Stream processing library on top of Kafka |
|
Relationship |
Foundation layer |
Complementary processing layer |
|
Integration Model |
N/A |
Built to work directly with Kafka |
Rather than competitors, these technologies form a synergistic stack. Kafka excels at reliable message delivery and storage, while Quix adds powerful stream processing capabilities, particularly for Python developers[2][4].
|
Aspect |
Apache Kafka |
Quix |
|---|---|---|
|
Primary Language Support |
Java/Scala native, clients for many languages |
Python-focused |
|
API Style |
Varies by client (often low-level) |
High-level, DataFrame-like API |
|
Learning Curve |
Steep (especially configuration) |
Gentler for Python developers |
|
Documentation Quality |
Extensive but complex |
Detailed with many tutorials |
|
Development Speed |
Varies by ecosystem components |
Faster for Python developers |
Quix provides a significantly more accessible experience for Python developers compared to raw Kafka clients[15]. Its pandas-like API feels familiar to data scientists and engineers already working in the Python ecosystem.
|
Feature |
Apache Kafka |
Quix |
|---|---|---|
|
Core Purpose |
Distributed messaging |
Stream processing |
|
Storage Model |
Persistent, log-based |
Uses Kafka for storage |
|
Processing Capabilities |
Basic with Kafka Streams (Java) |
Rich processing in Python |
|
State Management |
Through Kafka Streams |
Simplified with RocksDB |
|
Time Handling |
Basic event/processing time |
First-class citizen |
|
Scalability Approach |
Topic partitioning |
Streaming Context |
|
Python Support |
Via third-party clients |
Native, optimized experience |
|
Metric |
Apache Kafka |
Quix |
|---|---|---|
|
Throughput |
Very high (600+ MB/s)[9] |
Inherits from Kafka, adds processing overhead |
|
Latency |
Very low (milliseconds)[9] |
Low, but dependent on processing complexity |
|
Scalability |
Horizontal via partitioning |
Horizontal via Streaming Context |
|
Resource Efficiency |
Highly efficient |
Dependent on processing logic |
|
Durability |
Very high with replication |
Inherits from Kafka |
|
Use Case |
Best Solution |
|---|---|
|
High-throughput messaging only |
Kafka alone |
|
Stream processing in Java/Scala |
Kafka with Kafka Streams |
|
Stream processing in Python |
Kafka with Quix |
|
Real-time ML/AI pipelines |
Kafka with Quix |
|
Time-series analytics |
Kafka with Quix |
|
Event-driven microservices |
Depends on language (Kafka for Java, Kafka+Quix for Python) |
Apache Kafka and Quix serve distinct but complementary roles in the data streaming ecosystem. Kafka provides the robust messaging foundation with unparalleled throughput, durability, and scalability. Quix builds on this foundation to simplify stream processing for Python developers through its intuitive API and comprehensive feature set.
For organizations implementing real-time data processing:
-
If you need a reliable message broker with broad language support, choose Kafka as your foundation.
-
If you work primarily with Python and need stream processing capabilities, add Quix on top of Kafka.
-
For ML/AI applications requiring real-time data processing in Python, the Kafka+Quix combination offers an especially powerful solution.
Understanding these technologies as complementary rather than competitive allows you to leverage the strengths of both: Kafka's unmatched messaging performance and Quix's developer-friendly stream processing capabilities.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging