ETL vs. ELT vs. Zero ETL: Differences and Comparisons
-
ETL (Extract, Transform, Load) : A traditional data integration process that extracts data from sources, transforms it into a consistent format, and loads it into a target system like a data warehouse or data lake.
-
ELT (Extract, Load, Transform) : A variation of ETL where data is extracted, loaded into a target system, and then transformed within that system. This approach leverages the processing power of modern data platforms.
-
Zero-ETL : An emerging approach that eliminates traditional ETL processes by providing real-time access to data across independent sources without the overhead of data movement and transformation.
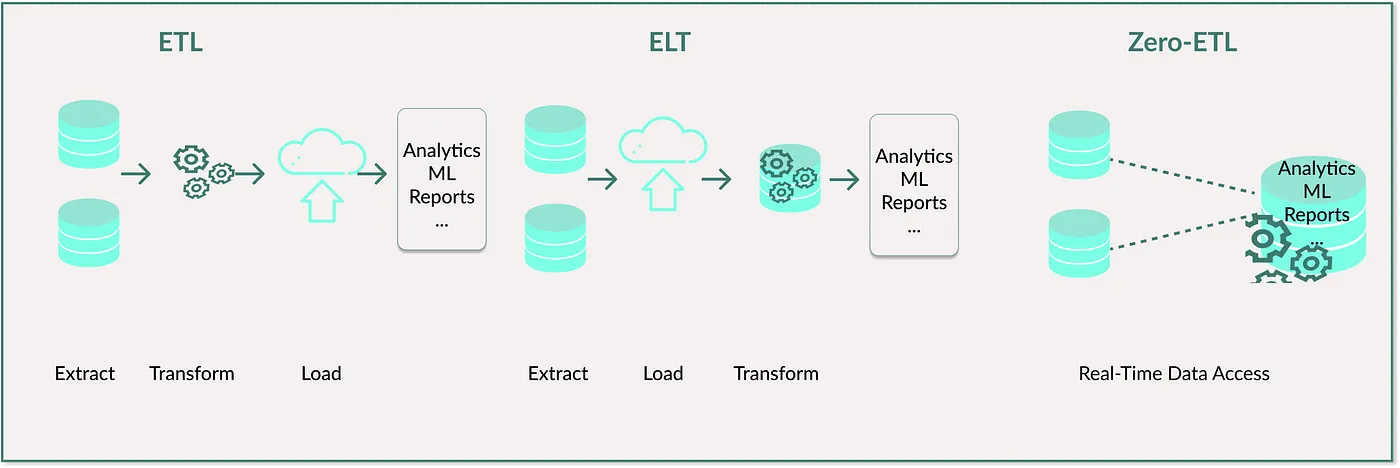

-
ETL is traditional and widely used but can be time-consuming and less flexible.
-
ELT is more efficient for large data volumes and leverages target system processing power.
-
Zero-ETL offers real-time data access without traditional ETL overhead, ideal for scenarios requiring immediate insights.
-
ETL is best for scenarios requiring complex transformations or strict data governance.
-
ELT is suitable for handling large volumes of data and leveraging modern data platforms.
-
Zero-ETL is ideal for real-time analytics and applications where data freshness is critical.
In summary, while ETL and ELT are established methods with specific strengths, Zero-ETL represents a modern approach focused on speed and efficiency, eliminating traditional data integration complexities.
AutoMQ is a next-generation Kafka that's 100% compatible and built on top of S3. Its Table Topic capability efficiently converts Kafka stream data directly into modern data lake table formats like Apache Iceberg or Paimon, simplifying the transformation from stream processing to data lakes. AutoMQ includes a fully functional schema registry that intelligently recognizes and manages data structures. This component automatically converts various stream data formats according to predefined schema rules, creating standardized data lake tables efficiently stored on S3 or other object storage systems. This automation eliminates the need for complex Flink jobs or ETL tasks for data format conversions, reducing both operational costs and technical complexity. Through the Table Topic feature, AutoMQ integrates seamlessly with mainstream data lake architectures, offering users an end-to-end data processing solution.

[1] Why ETL-Zero? Understanding the Shift in Data Integration: https://medium.com/towards-data-science/why-etl-zero-understanding-the-shift-in-data-integration-as-a-beginner-d0cefa244154