Cloud Native Kafka with Cost and Performance
As the world's first next-generation streaming data platform fully compatible with Apache Kafka®, AutoMQ inherits all the features of native Kafka and has achieved groundbreaking improvements in cost and performance. With an innovative cloud-native architectural design, AutoMQ can reduce the cost of using Kafka on the cloud by up to 90% while providing minute-level elasticity, significantly enhancing data flow efficiency.

Since its release, the open-source AutoMQ project has attracted widespread attention and high recognition from developers worldwide. It has frequently appeared on the GitHub Trending list, accumulating over 4, 200 stars to date. These numbers are more than mere statistics; they represent votes of confidence from global developers in the cloud-native Kafka technology transformation. This not only demonstrates its technical advantages and broad market acceptance but also reflects the developer community's high expectations for the future potential of AutoMQ.
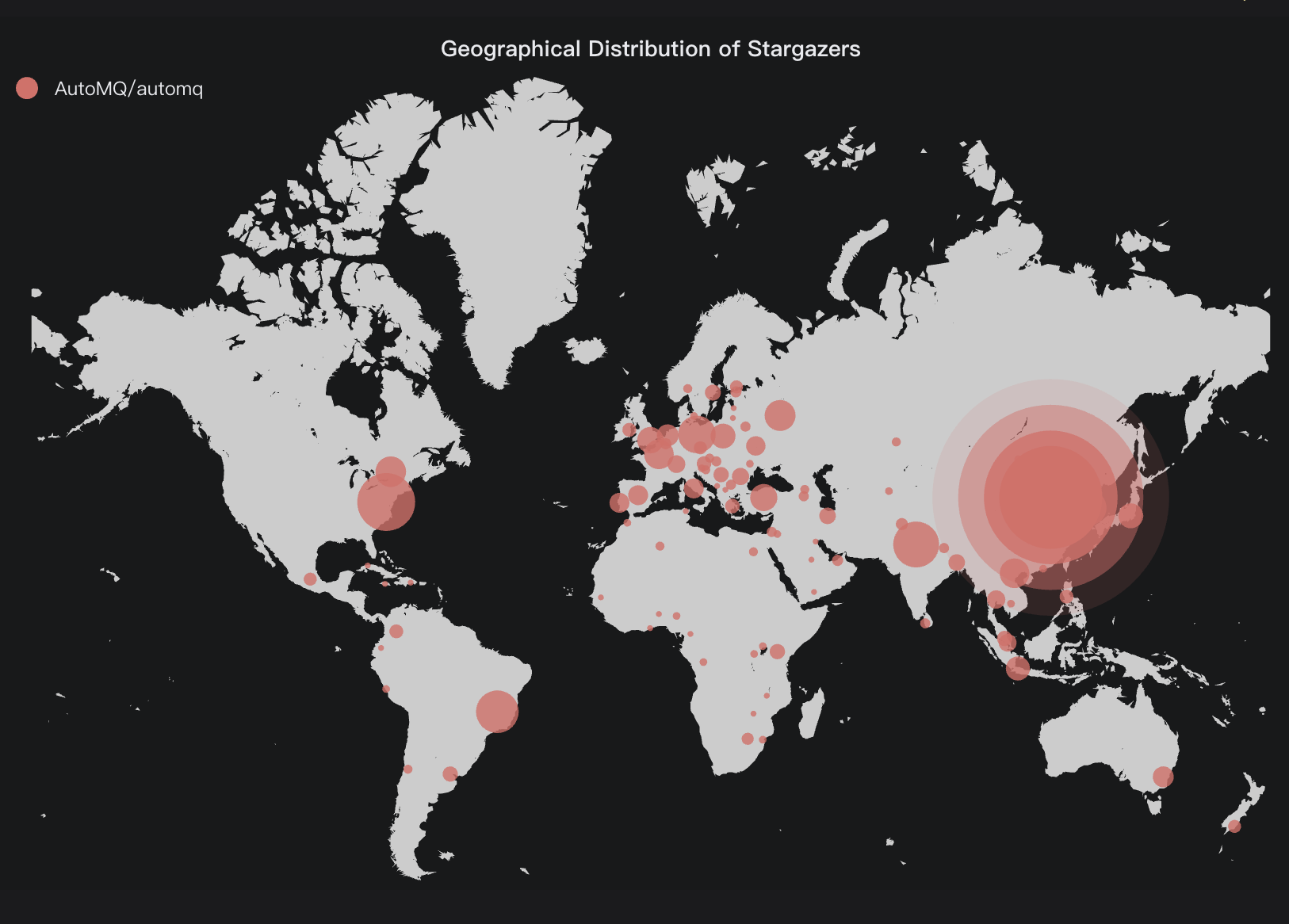
AutoMQ's global technical deployment is continuously expanding, now covering key regions in North America, Europe, and Asia. User distribution heatmap data indicates that the project performs particularly well in North America, which has the highest activity in the open-source ecosystem, and Asia, where there is a strong demand for digital transformation. Currently, AutoMQ serves renowned enterprises across eight industries, including Xiaohongshu (social e-commerce), Grab (Southeast Asian ride-hailing service), Geely Auto (smart manufacturing), JDQ (retail technology), and Cao Cao Mobility (smart transportation). These production-level practices validate its technological versatility.

Choosing AutoMQ means:
🌟 Seamless Migration: Fully compatible with Kafka protocols, requiring no modifications to existing code.
🌟 Cost Revolution: Decoupled Storage-Compute Architecture Reduces Storage Costs by Over 80%
🌟 Intelligent Scalability: Auto-expansion during peak traffic and automatic resource reclamation during idle times.
This is not just an upgrade of technical tools but an evolution in the paradigm of streaming data processing. We invite you to join the AutoMQ Developer Initiative, where you can contribute code, optimize documentation, and share practical cases to collectively build a Kafka ecosystem that aligns with the cloud-native era. Whether you are a seasoned Kafka developer or a newcomer exploring streaming data processing, there is a place for your technical expertise here!
Want to contribute to the AutoMQ open source project? Don't worry about a lack of experience; we have designed a clear participation path for every contributor:
1️⃣ **Get Started Easily: ** Visit the AutoMQ GitHub repository's Issues list and use the "good first issue" filter to pick tasks marked as newcomer-friendly. These are low-threshold issues designed specifically for first-time contributors, ranging from documentation improvements to small feature optimizations. These issues help you get started, build experience, and familiarize yourself with our contribution process.
2️⃣ Claim a Task in 30 Seconds: Once you find a task you like, simply comment /assign in the corresponding Issue's comment section. A maintainer will confirm the assignment within 24 hours. Upon confirmation, you can start working on the issue.
3️⃣ **Full Support Provided: ** Stuck during development? You can @ the maintenance team in the Issue comments or initiate a technical discussion in the Discussions section. Experienced maintainers will guide you through the debugging process.
Visit the AutoMQ GitHub repository now and start your open-source contribution journey!
AutoMQ, as a mature open-source project in the cloud-native streaming storage field, provides developers with a unique platform for learning and practice:
🔧 **Deep involvement in cutting-edge technology architecture: ** By contributing code, you'll directly participate in building a highly available, low-cost cloud-native streaming storage engine. Learn to design core mechanisms like elastic scaling and tiering of hot and cold data. Hundreds of companies have already verified scenarios processing trillions of messages daily based on AutoMQ.
👨💻 Collaborate and evolve with industry experts: The project's core Maintainers come from Alibaba's mobile internet and cloud computing teams, with over ten years of experience in distributed systems development. Contributors can receive one-on-one guidance from senior architects through Code Reviews and participate in technical solution discussions, learning how to balance engineering practice and theoretical models.
🌍 **Driven by real commercial scenarios: ** Every optimization you submit will be validated in real production environments. For example, the Xiaohongshu technical team improved recommendation system latency using AutoMQ’s delay optimization strategies, and Geely Auto reduced car networking data costs based on storage compression solutions. This feedback from top enterprises will guide your technical growth direction.
🎉 Become a Recognized AutoMQ Committer: Simply resolve issues and successfully merge your code to earn the title of AutoMQ Committer. Your profile picture will be featured in the contributors list on the GitHub Readme.
Every commit you make will be a cornerstone in shaping the future of cloud-native Kafka. We particularly value:
✅ Submit a PR with unit test coverage exceeding 80%
✅ Follow the Conventional Commits specification for commit messages
✅ Initiate technical solution discussions for complex design decisions
Select a task from the "good first issue" on GitHub now, and earn your first Merged PR achievement!
Join the AutoMQ developer community now to connect and learn with other developers, and together witness and drive the next technological leap in the cloud-native field!
🚀 How to participate
- Slack Community: Join the AutoMQ Slack Channel to interact with technical teams in North America and Asia in real-time.