Cloud Native Kafka Alternatives: Apache Kafka vs. NATS
Apache Kafka and NATS represent two distinct approaches to message-oriented middleware for distributed systems. This article provides a detailed comparison of these technologies to help you understand their strengths, differences, and optimal use cases. As modern applications increasingly adopt event-driven and microservices architectures, choosing the right messaging system becomes crucial for system performance, scalability, and reliability.
Apache Kafka is a distributed event streaming platform built with a focus on durability, scalability, and high throughput. Originally developed at LinkedIn and later open-sourced, Kafka has evolved into a robust ecosystem for handling massive data streams[2].
NATS is a lightweight, high-performance data layer designed for simplicity and operational efficiency across environments. It consists of two main components: Core NATS (the base messaging framework) and JetStream (which adds persistence capabilities)[2][11].

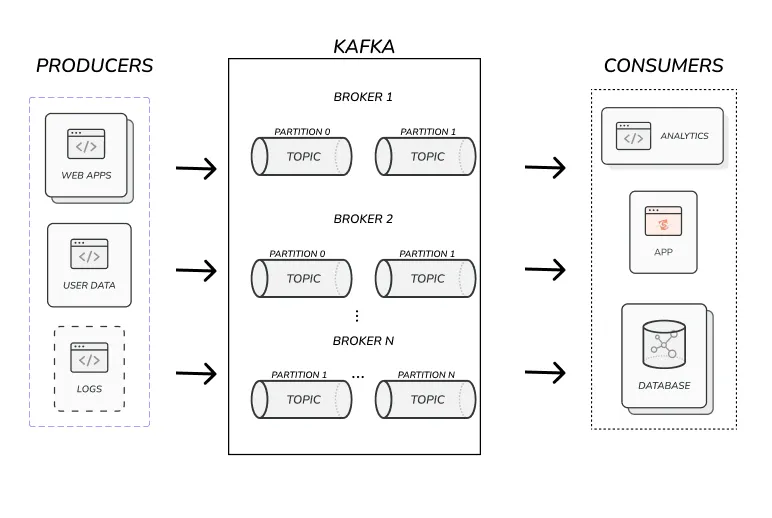
Kafka's architecture is built around logs – an append-only, immutable data structure. It organizes data into topics with multiple partitions distributed across brokers. Historically, Kafka required Zookeeper for coordination, though newer versions support KRaft mode without this dependency[1][2].
NATS emphasizes simplicity with a clean, straightforward design:
"Even if you take the zookeepers out of the picture, NATS remains much 'lighter' to run than Kafka. There are a lot of things that NATS does 'out of the box' for which with Kafka you would have to deploy Kafka Streams, connectors, and mirror maker or Replicator nodes on top of your broker nodes."[1]
|
Aspect |
Kafka |
NATS |
|---|---|---|
| Implementation Language |
Java (JVM-based) |
Go |
| Binary Size |
JVM plus JARs (larger) |
Single binary <15MB |
| Infrastructure Requirements |
Higher |
Lower |
| Coordination |
Zookeeper/KRaft |
Self-contained |
| Configuration Complexity |
Higher |
Lower |
Kafka excels in scenarios requiring high throughput data processing. Its design prioritizes handling massive volumes of data, making it suitable for batch and stream processing applications[2][9].
NATS prioritizes low latency messaging, making it ideal for scenarios where speed is critical:"Performance wise, NATS is much faster than Kafka... for microservice intercommunication, NATS makes more sense as there isn't too much data and NATS can handle easily."[1]
A significant difference between the two systems is their resource consumption profile:
-
Disk I/O : NATS typically uses fewer disk IOPS compared to Kafka, which can translate to lower operational costs in cloud environments[1].
-
Memory Usage : NATS has a smaller memory footprint, making it suitable for resource-constrained environments.
-
CPU Efficiency : NATS' Go implementation and thread-per-core architecture can be more CPU-efficient for certain workloads.
Both systems approach scalability differently:
Kafka scales through partition distribution across brokers, enabling parallel processing. However, this requires careful planning and management of partition distribution[2][7].
NATS offers simpler horizontal scaling through its cluster capabilities and automatically balances connections across servers[11].
Kafka primarily supports a publish/subscribe model focused on durable, ordered message logs. NATS provides more flexibility with several communication patterns:"NATS has built-in support for Request-Response model of messaging. To achieve similar thing in Kafka you have to build from scratch."[1]
|
Delivery Guarantee |
Kafka |
NATS |
|---|---|---|
| At-most-once |
No |
Yes (Core NATS) |
| At-least-once |
Yes |
Yes (JetStream) |
| Exactly-once |
Yes |
Yes (JetStream) |
NATS provides flexibility through its dual nature:
-
Core NATS : Fast, non-persistent messaging with at-most-once delivery
-
JetStream : Adds persistence with stronger delivery guarantees[14]
Both platforms implement consumer groups differently:"The concept of consumer group in Kafka is much cleaner than the same in NATS. In NATS it's a bit convoluted and not easily grasped by beginners."[1]
Kafka is particularly well-suited for:
-
Big Data Processing : Handling high-volume data streams with persistence requirements
-
Event Sourcing : Maintaining an immutable log of events
-
Analytics Pipelines : Supporting data science and analytics workflows
-
Log Aggregation : Centralizing logs from distributed systems[2][9]
NATS excels in:
-
Microservices Communication : Low-latency service-to-service messaging
-
IoT and Edge Computing : Lightweight protocol for constrained devices
-
Real-time Applications : Chat, gaming, and other applications requiring immediate response
-
Cloud-native Architectures : Containerized environments where simplicity is valuable[2][9][11]
Some organizations use both systems together:"I have seen various companies using both Kafka and NATS with Kafka for more data and NATS for messaging."[1]
Both platforms offer robust but different security approaches:
Kafka leverages:
-
Kerberos and TLS for authentication
-
JAAS and ACLs for authorization
-
ZooKeeper/KRaft for storing security configurations[14]
NATS provides:
-
Multiple authentication options: TLS, NATS credentials, NKEYS, username/password, tokens
-
Account-level isolation with configurable limits
-
Rich authorization capabilities with publish/subscribe permissions[14]
NATS has a significant advantage in multi-tenant scenarios:"NATS supports true multi-tenancy and decentralized security through accounts and defining shared streams and services."[14]
Kafka, by comparison, does not natively support multi-tenancy[14].
Kafka uses file-based persistence with a log-structured approach. Messages are retained based on configurable policies (time or size-based)[14].
NATS JetStream supports:
-
Memory or file-based storage
-
Message replay by time, count, or sequence number
-
Configurable retention policies[14]
Both systems allow message replay, but with different approaches:
-
Kafka : Replay from a specific offset
-
NATS JetStream : Replay by time, count, or sequence number[14]
Kafka traditionally used Zookeeper for cluster coordination, with newer versions supporting KRaft. Its architecture includes:
-
Leader-follower replication for partitions
-
Configurable replication factor
-
Automatic leader election[14]
NATS uses a full mesh clustering approach with:
-
Self-healing capabilities
-
Automatic server discovery
-
Built-in mirroring in JetStream[14]
Both systems handle failures differently:"Core NATS supports full mesh clustering with self-healing features to provide high availability to clients. NATS streaming has warm failover backup servers with two modes (FT and full clustering). JetStream supports horizontal scalability with built-in mirroring."[14]
NATS offers a simpler operational model:"NATS is easy to deploy, configure, and manage. Yea 'no zookeeper' was one of their biggest selling points, in terms of simplicity."[1]
Kafka requires more operational expertise, especially in large-scale production environments[1][11].
Kafka provides:
-
Various management tools and consoles
-
Metrics exporters for monitoring systems
-
Command-line tools for administration[14]
NATS offers:
-
Prometheus metrics export
-
Grafana dashboards
-
CLI tools for management
-
Separation of operations from security[14]
NATS generally offers a simpler developer experience:Connecting to NATS and publishing messages is much simpler than Kafka. For Kafka you have to set certain knobs and gears before you are able to publish a message."[1]
However, some concepts like consumer groups are considered clearer in Kafka[1].
Both systems offer client libraries for multiple programming languages, but their maturity varies:"Kafka and the client libraries seems to be much more stable. We had and still have issues on NATS Jetstream with Consumers..."[1]
Kafka has a more established ecosystem:"Kafka has much mature eco system and community support than NATS, maybe because it's more popular and have been in industry to much longer time."[1]
Both platforms offer integration options:
-
Kafka : Rich ecosystem of connectors, Kafka Connect, Kafka Streams
-
NATS : Growing ecosystem, NATS-Kafka bridge for interoperability[4][5]
Production experience shows that both systems have trade-offs:"We have a project using Kafka and one using NATS Jetstream. For us there was not much difference in the effort for hosting the two. Main difference is for us the stability, especially about the client libraries."[1]
NATS may offer cost advantages in cloud environments:"For an equivalent workload NATS uses many less disk IOPS compared to Kafka, which if you are running on public clouds can make a very noticeable difference in your costs."[1]
When deciding between Kafka and NATS, consider:
-
Data volume and retention needs : Kafka for higher volumes with longer retention
-
Latency requirements : NATS for lowest latency messaging
-
Operational complexity tolerance : NATS for simpler operations
-
Integration requirements : Kafka for richer ecosystem
-
Resource constraints : NATS for more efficient resource usage
For some organizations, using both technologies can provide the best of both worlds:"I think when you have lots of data coming in, Kafka is better suited for the Job. For microservices communication, NATS is more suited where small bursts of messages, or many small messages."[1]
Apache Kafka and NATS represent different philosophies in distributed messaging systems. Kafka excels in high-throughput scenarios with complex data processing needs, while NATS shines in simplicity, low latency, and operational efficiency.
The choice between them should be guided by your specific use case requirements, operational constraints, and performance needs. In some situations, using both technologies together might provide the most comprehensive solution.
As distributed systems continue to evolve, both platforms are likely to develop new capabilities while maintaining their core strengths, offering developers increasingly powerful tools for building resilient, scalable applications.
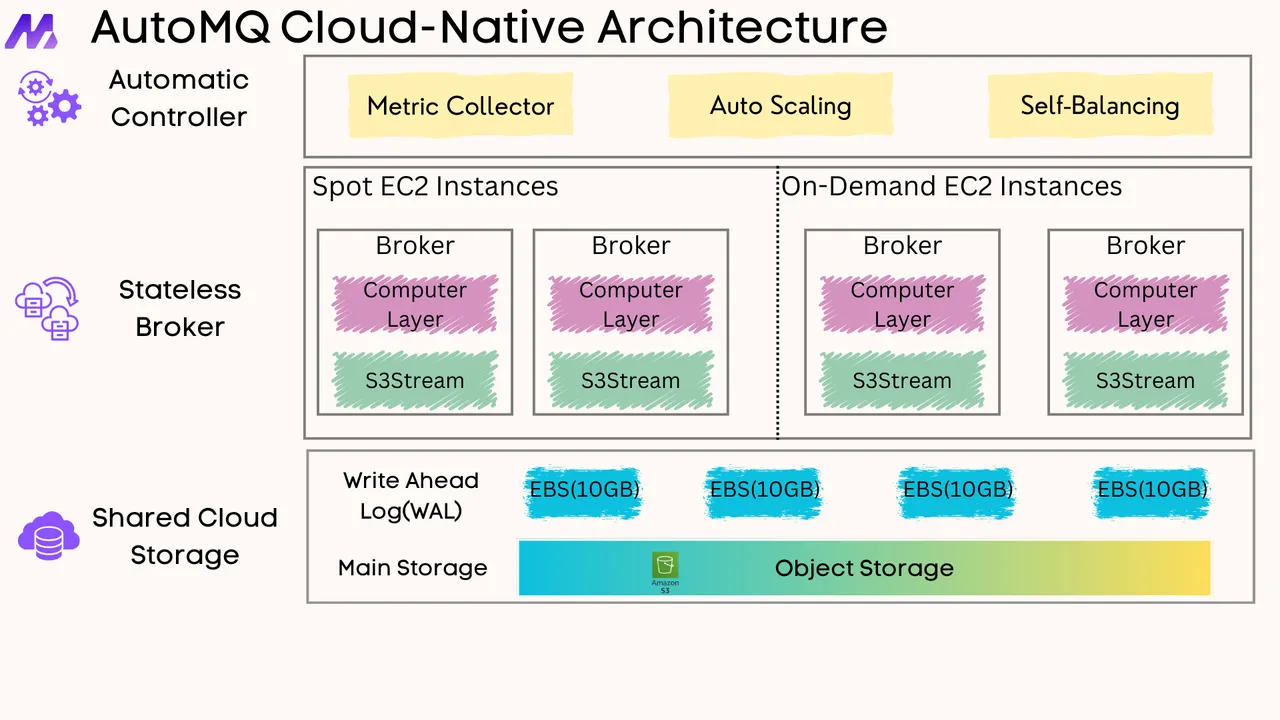
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging