Guide to Kafka Retention and Best Practices
Here's a comprehensive guide to Kafka retention and best practices, covering key concepts, strategies, and considerations for effective data management in Kafka.
Kafka retention refers to the duration for which messages are stored in Kafka topics before they are eligible for deletion. It is crucial for managing storage, ensuring data availability, and meeting compliance requirements.
-
Time-Based Retention : Configured using
log.retention.hours,log.retention.minutes, orlog.retention.ms. This policy deletes messages after a specified time period, with a default of 168 hours (7 days). -
Size-Based Retention : Configured using
log.retention.bytes. This policy limits the size of a partition before old segments are deleted, with a default of -1 (infinite).
-
Align with Business Needs : Adjust retention periods based on data consumption patterns and business requirements.
-
Monitor Disk Usage : Regularly check disk space to avoid running out of storage.
-
Policy : Set
log.cleanup.policy=compactto retain the latest version of each key, ideal for stateful applications. -
Benefits : Reduces storage usage while maintaining the latest state.
-
Customization : Use topic-level configurations to fine-tune retention policies based on specific topic needs.
-
Example : Set a specific retention period for a topic using
kafka-configscommand.
-
Strategy : Move older segments to cheaper storage systems while keeping recent data on faster disks.
-
Benefits : Balances storage costs with data freshness.
-
Regular Reviews : Periodically review topic configurations to align with changing business needs and compliance regulations.
-
Dynamic Adjustments : Adjust retention settings based on storage usage and data age metrics.
-
Regulatory Needs : Ensure retention settings comply with legal and regulatory obligations.
-
Auditing Mechanisms : Implement proper auditing to ensure compliance.
- Storage Needs : Predict and allocate sufficient storage capacity to accommodate desired retention durations.
- Cost-Effective Strategies : Explore tiered storage or data lifecycle management to manage costs while retaining essential data.
- Thresholds : Define thresholds for retention-related metrics to trigger timely adjustments.
- Compliance : Ensure data retention aligns with legal obligations to avoid risks.
By following these best practices and understanding the challenges associated with Kafka retention, you can effectively manage your Kafka cluster, ensuring optimal performance, compliance, and data integrity.
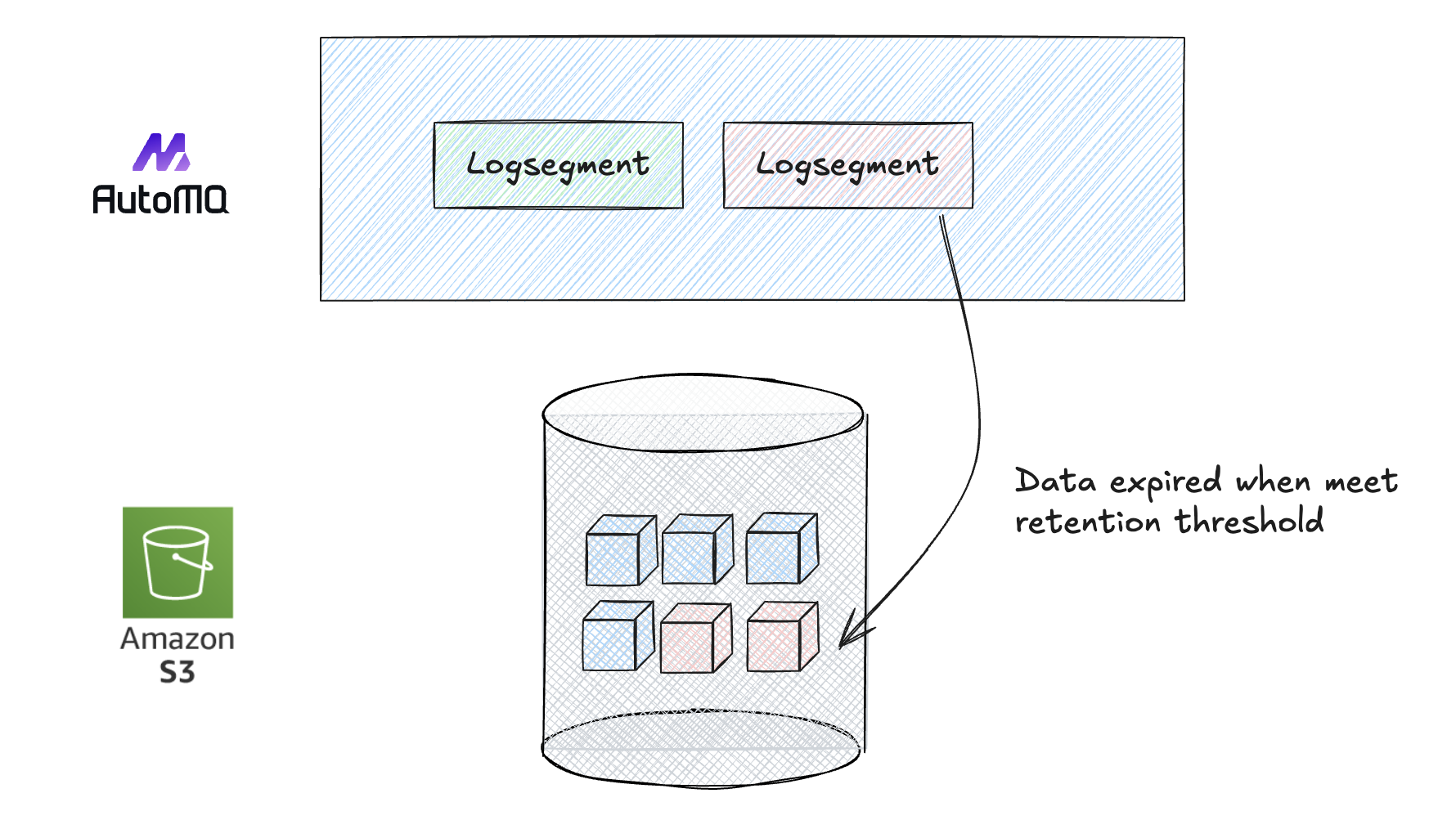
AutoMQ is a next-generation Kafka that is 100% fully compatible and built on top of S3. Due to the compatibility between AutoMQ and Kafka, you can use all retention configurations supported by Apache Kafka. When data expires, AutoMQ will actively delete the data stored on S3.