How to select Go clients for Kafka, and compatibility
The Go programming language has emerged as a strong contender for building high-performance, scalable Kafka-based systems. Several client libraries are available, each with distinct design philosophies and trade-offs. This section evaluates the major options, their features, and suitability for different use cases.
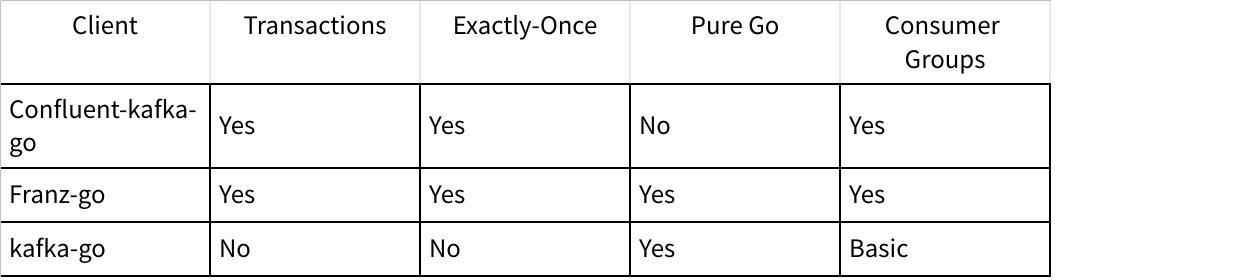
Built atop the battle-tested librdkafka C library, this client offers robust support for producer/consumer operations, transactional messaging, and administrative functions. Its performance is unmatched for high-throughput scenarios, but reliance on CGO introduces deployment complexities for static binaries and cross-platform builds.
A pure Go implementation emphasizing idiomatic design and modern Kafka features like exactly-once semantics. Benchmarks show throughput comparable to librdkafka while avoiding CGO dependencies. Its API surface closely mirrors Kafka protocol primitives, making it ideal for developers requiring fine-grained control.
Designed for simplicity, this client abstracts low-level protocol details into reader/writer interfaces reminiscent of Go's io package. While lacking advanced features like transactions, its opinionated design reduces boilerplate for basic pub-sub workflows.
kafka-go is currently tested with Kafka versions 0.10.1.0 to 2.7.1. While it should also be compatible with later versions, newer features available in the Kafka API may not yet be implemented in the client.
AutoMQ positions itself as a cloud-native Kafka alternative with 100% protocol compatibility. This section validates those claims through architectural and functional testing.
AutoMQ retains Kafka's compute layer while replacing the storage engine with S3Stream. This implementation strategy ensures:
-
Full API Support: AutoMQ implements 73/74 Kafka APIs vs. WarpStream's 26, missing only
StopReplica(made redundant by S3 durability). -
Test Suite Validation: Passes all Apache Kafka test cases, with failures primarily in Zookeeper-dependent scenarios (AutoMQ uses KRaft mode).
-
Client Transparency: No code changes are required for Confluent, Franz-go, or other compliant clients. Message ordering, delivery semantics, and offset management behave identically.
While protocol-compatible, AutoMQ optimizes for cloud environments:
-
Stateless Brokers: Enable instant scaling using spot instances without data relocation.
-
Cross-AZ Cost Reduction: By persisting directly to S3, eliminates inter-AZ replication traffic (major cost in traditional Kafka).
-
Storage Efficiency: Single-replica durability via S3/EBS reduces storage costs by 10x compared to Kafka's 3x replication.
For Go developers building on Kafka, Franz-go and Confluent-kafka-go provide the most robust feature sets, with AutoMQ offering compelling cloud advantages:
-
Cost: 70% reduction in cloud spend via S3 storage and spot instances.
-
Resilience: Survives AZ outages through S3's 11-nines durability.
-
Simplicity: No partition management or capacity planning.
Organizations adopting AutoMQ should:
-
Validate client compatibility using the kafka-protocol test suite
-
Tune batch sizes and timeouts for S3 characteristics
-
Implement cross-cloud monitoring for S3-specific metrics
The combination of mature Go clients and AutoMQ's cloud-native architecture enables building elastic, cost-effective streaming systems without sacrificing Kafka compatibility.