Easiest Way to Stream Kafka Data to Iceberg Tables
AutoMQ Table Topic represents a significant advancement in data streaming technology, offering a streamlined approach to integrate Kafka data streams with Apache Iceberg tables. This feature eliminates traditional ETL processes while providing robust schema management and seamless integration with cloud storage solutions like AWS S3. Since its announcement in late 2023, AutoMQ has successfully transformed Apache Kafka's architecture, resulting in at least 50% cost savings for major companies including JD.com, Zhihu, REDnote, and others.
AutoMQ's approach represents the latest evolution in data architecture paradigms:
-
Shared-Nothing Architecture : Traditional on-premise systems where each node operates independently with its own memory and disk, designed for horizontal scaling but creating complexity in data consistency
-
Shared-Storage Architecture : Evolution leveraging cloud-based object storage (like Amazon S3) for improved scalability, durability, and cost efficiency
-
Shared-Data Architecture : The latest advancement addressing limitations of previous architectures, enabling real-time analytics and decision-making by providing immediate access to data as it's generated
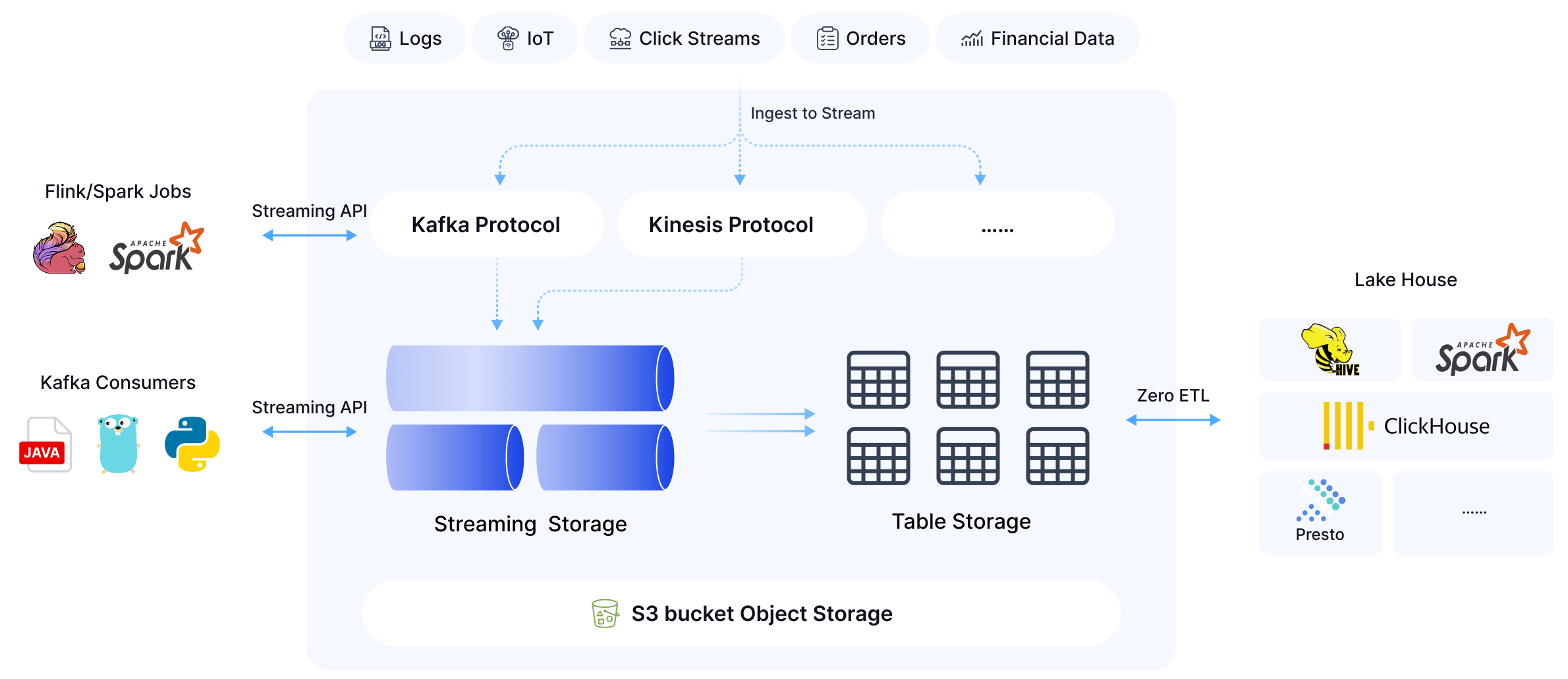
AutoMQ Table Topic exemplifies the shared-data architecture by natively supporting Apache Iceberg, bridging the gap between batch and stream processing, and enabling enterprises to analyze data in real-time.
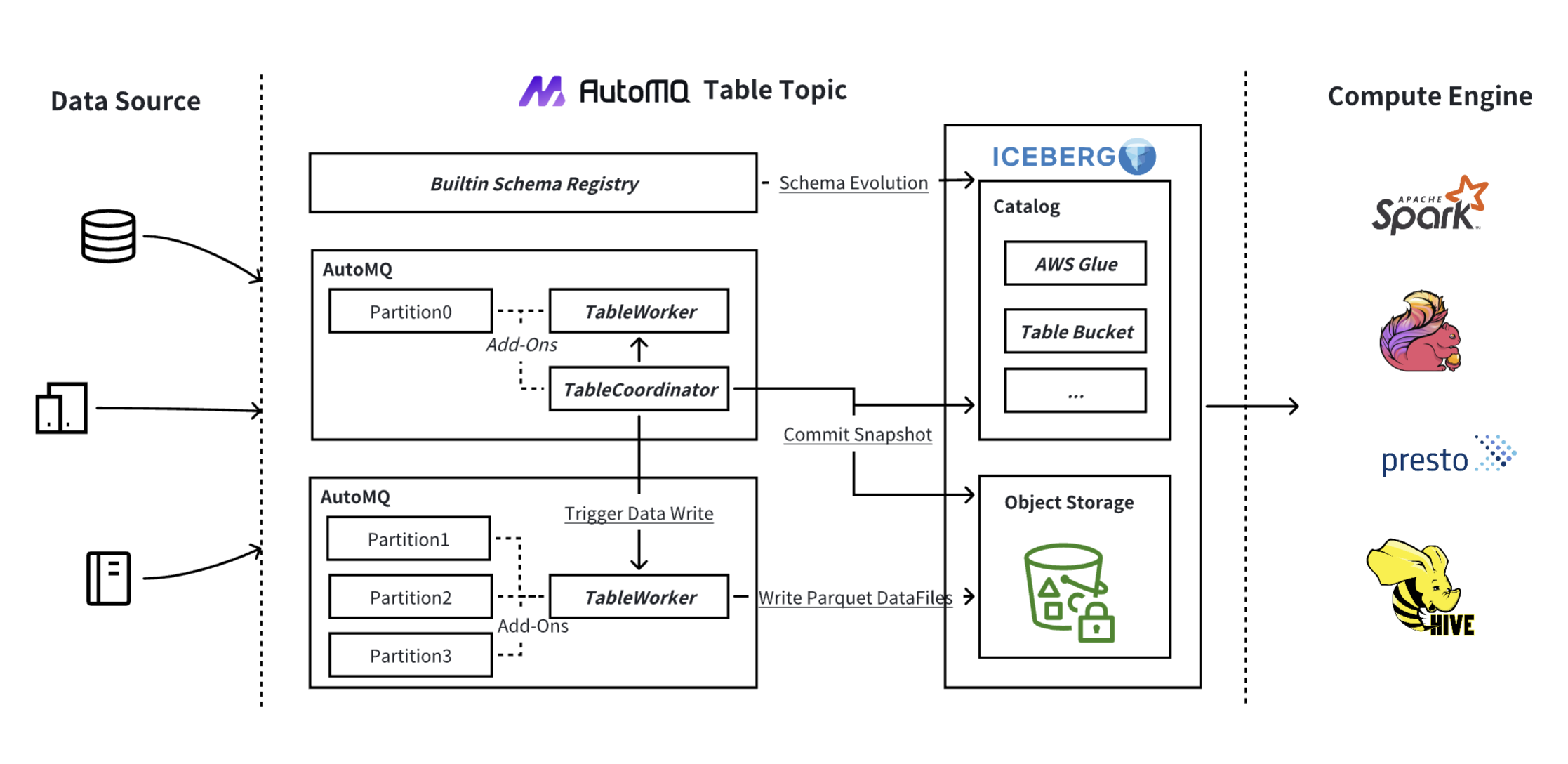
AutoMQ Table Topic includes a built-in Kafka Schema Registry that automatically synchronizes with Iceberg's Catalog Service, including AWS Glue, AWS Table Bucket, and Iceberg Rest Catalog Service. This integration provides:
-
Direct use of Schema Registry endpoint by Kafka clients
-
Automatic synchronization between Kafka schemas and Iceberg catalogs
-
Support for automatic schema evolution without manual intervention
The architecture includes several key components:
-
Table Coordinator : Each topic has a dedicated coordinator that centralizes all nodes for Iceberg Snapshot submissions, reducing commit frequency and avoiding conflicts
-
Table Worker : Each AutoMQ node contains an embedded Table Worker responsible for writing data from all partitions on that node to Iceberg
-
Configurable Submission Intervals : The system allows customizable intervals for data submission to Iceberg, enabling users to balance real-time processing needs with cost efficiency
AutoMQ Table Topic provides seamless integration with AWS S3 Tables, leveraging their catalog service and maintenance capabilities including:
-
Compaction services
-
Snapshot management
-
Unreferenced file removal
-
Direct compatibility with AWS Athena for large-scale data analysis
AutoMQ Table Topic offers significant advantages over traditional Kafka Connect-based approaches:
-
Single-Click Enablement : Stream data into Iceberg tables with just one click
-
Ready-to-Use Schema Registry : Built-in registry works out-of-the-box without additional configuration
-
Automatic Table Creation : Leverages registered schemas to automatically create Iceberg Tables in catalog services like AWS Glue
One of the most significant advantages is the elimination of traditional ETL processes:
-
Direct Data Streaming : No intermediaries like Kafka Connect or Flink required
-
Reduced Complexity : Significantly simplifies data pipeline architecture
-
Cost Reduction : Lower operational and infrastructure costs by eliminating additional processing layers
The architecture provides robust scaling features:
-
Stateless and Elastic : AutoMQ brokers can scale up or down seamlessly
-
Dynamic Partition Reassignment : Partitions can be reassigned on-the-fly
-
Adaptive Throughput : Handles data ingestion rates from hundreds of MiB/s to several GiB/s without manual intervention
The implementation begins with subscribing to AutoMQ on AWS Marketplace:
-
Navigate to AutoMQ page on AWS Marketplace
-
Click "Subscribe" button
-
Follow instructions to install AutoMQ in your VPC using BYOC (Bring Your Own Cloud) model
Configure the necessary storage and AutoMQ instance:
-
Create a new S3 table bucket for storing table data
-
Record the bucket's ARN for later use
-
Log in to AutoMQ BYOC Console with provided credentials
-
Set up a new instance with the latest AutoMQ version
-
Link the instance to your S3 bucket ARN during setup
-
Create a test topic and activate the Table Topic feature for it
Connect your data sources to the configured Table Topic:
-
Obtain endpoints for your AutoMQ instance and Schema Registry from the BYOC Console
-
Use Kafka clients to connect to your AutoMQ instance
-
Send data (such as clickstream data) to the established Table Topic
Access and analyze the streamed data:
-
AutoMQ Table Topic automatically creates tables in your AWS S3
-
Open AWS Athena in the AWS Management Console
-
Use Athena to query the data stored in tables created by AutoMQ
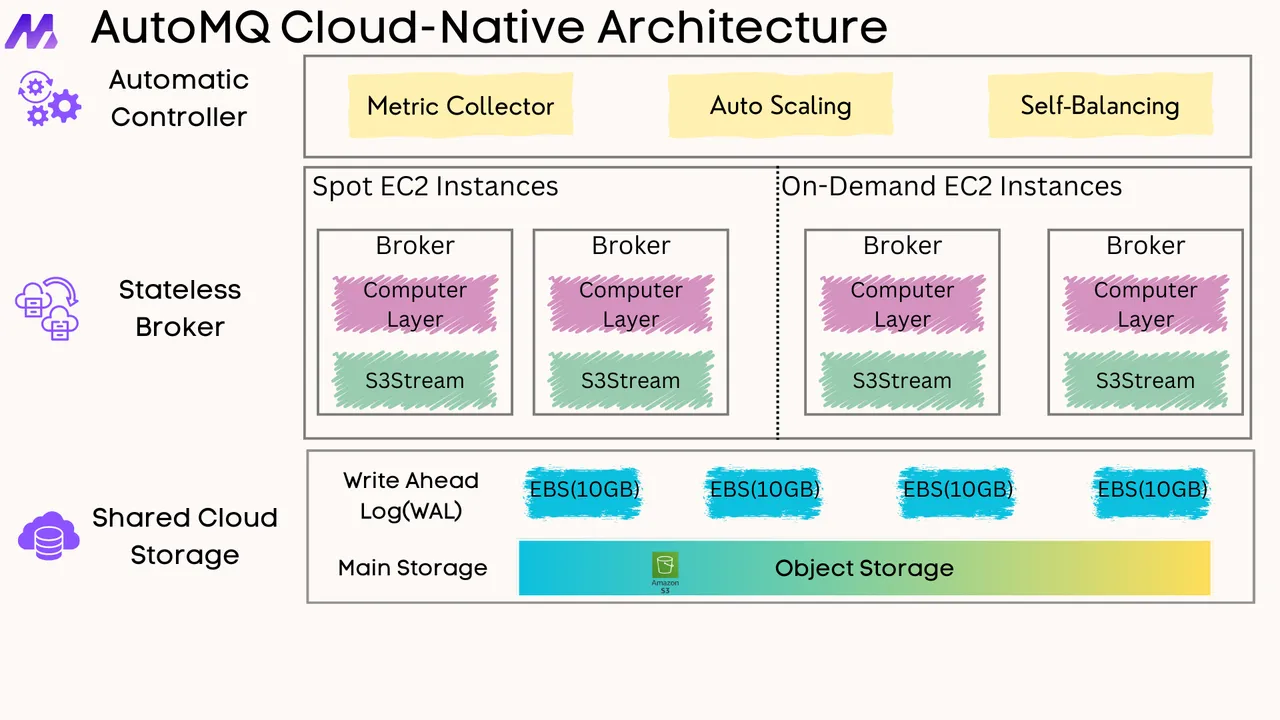
AutoMQ Table Topic is fully integrated into AutoMQ's core architecture, maintaining simplicity without requiring additional nodes. This approach aligns with Amazon CTO Werner Vogels' concept of embracing "Simplexity".
The architecture comprises three main components:
-
Schema Management Module : Handles schema registry and evolution
-
Table Coordinator : Centralizes coordination for efficient commits
-
Table Workers : Distribute data writing tasks across nodes
This integrated approach offers several key benefits:
-
Cohesive System : Table Topic functions as a core feature rather than an add-on
-
Reduced Complexity : Fewer components mean fewer failure points
-
Optimized Resource Utilization : Shared resources between Kafka and Table Topic functionalities
AutoMQ's approach provides substantial financial benefits:
-
Over 50% Cost Reduction : Compared to traditional Apache Kafka-based solutions
-
Optimized Cloud Resource Utilization : Leverages object storage, Spot instances, and other cloud services
-
Pay-as-you-go Model : Auto-scaling aligns costs with actual workload
The platform offers true serverless functionality:
-
Auto Scaling : Monitors cluster metrics to automatically scale in/out
-
Rapid Scaling : Computing layer (broker) can scale within seconds
-
Unlimited Storage : Cloud object storage eliminates capacity concerns
AutoMQ Table Topic represents a significant advancement in streaming data to Iceberg tables, offering a streamlined, cost-effective approach that eliminates traditional ETL processes. By combining a built-in schema registry, efficient table coordination, and seamless AWS integration, it provides a comprehensive solution for organizations looking to simplify their data pipelines while maintaining real-time analytics capabilities.
The ability to enable streaming with a single click, coupled with automatic schema evolution and dynamic scaling, makes AutoMQ Table Topic an attractive option for enterprises seeking to unify their streaming and analytics workflows. As data volumes continue to grow, solutions like AutoMQ that bridge the gap between real-time data processing and analytical workloads will become increasingly valuable in the modern data ecosystem.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging