What is the Zookeeper in Kafka All You Need to Know
Apache Kafka ZooKeeper is a critical component of the traditional Kafka architecture that provides distributed coordination services essential for managing and maintaining Kafka clusters. This guide explores ZooKeeper's role in Kafka, its configuration, best practices, common issues, and the industry's ongoing transition away from ZooKeeper dependency.
Apache ZooKeeper is a centralized coordination service for distributed workloads that performs essential coordination tasks within a Kafka cluster. It serves as a reliable, high-performance coordination kernel that enables Kafka brokers to work together efficiently in a distributed environment.
ZooKeeper provides several fundamental services for distributed systems, including primary server election, group membership management, configuration information storage, naming, and synchronization at scale. Its primary aim is to make distributed systems like Kafka more straightforward to operate by providing improved and reliable change propagation between replicas in the system[3].
In the Kafka ecosystem, ZooKeeper maintains consistent metadata across the cluster, ensuring that all brokers have a unified view of the system state. This metadata includes information about topics, partitions, brokers, and other critical configuration data necessary for Kafka's operation[11].
ZooKeeper plays several vital roles in the traditional Kafka architecture, serving as the backbone for cluster management and coordination. The controller broker in a Kafka cluster is responsible for communicating with ZooKeeper and relaying relevant information to other brokers[8]. This hierarchical relationship ensures efficient metadata management and cluster coordination.
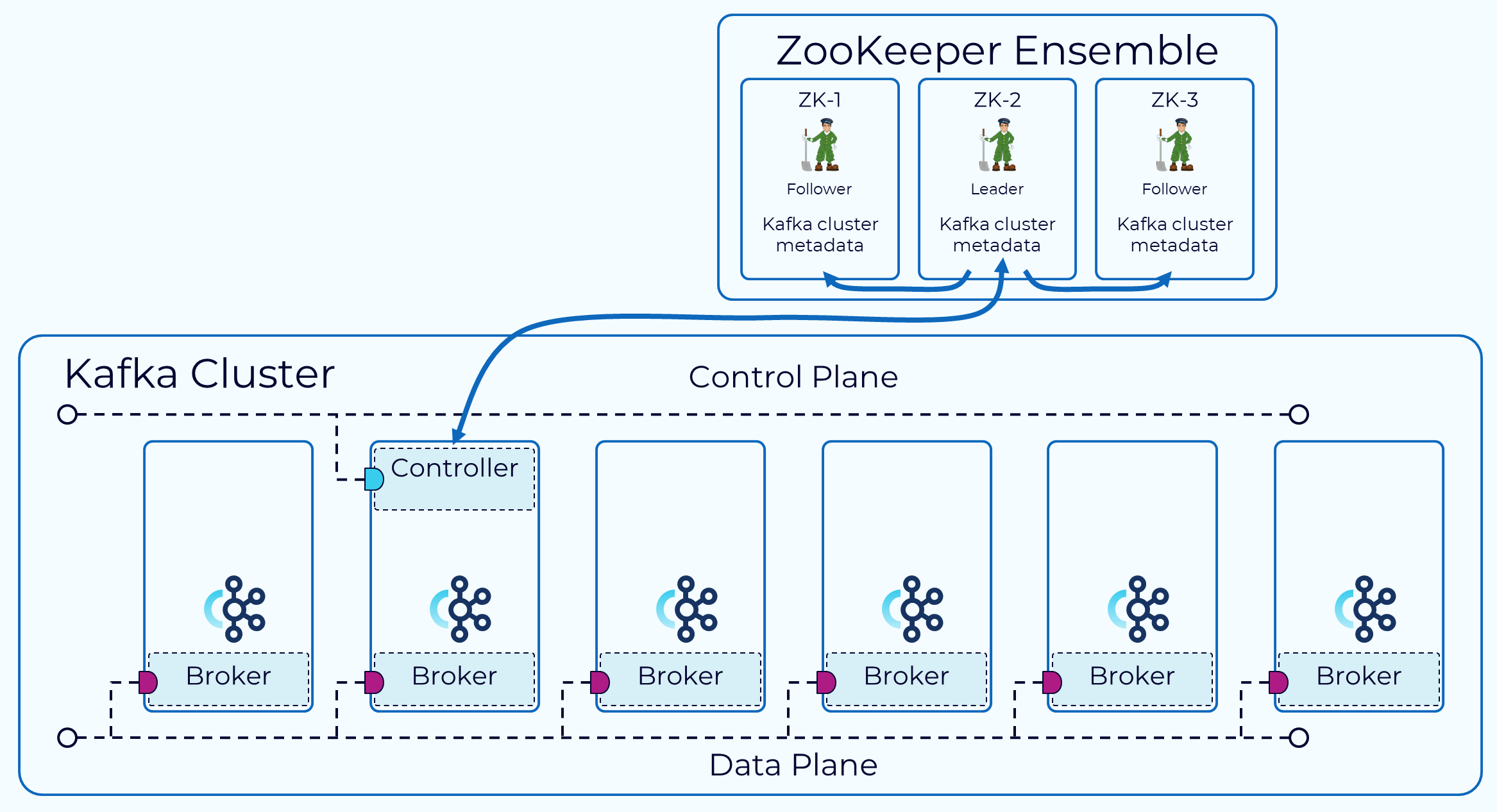
One of ZooKeeper's primary functions is to maintain and store metadata for the Kafka cluster. This metadata includes information about topics, partitions, brokers, consumer offsets, and overall cluster configuration[4]. By storing this information in a centralized and reliable system, Kafka ensures that all components have access to the same system state, enabling consistent operation across the distributed environment.
ZooKeeper stores this metadata in a hierarchical namespace organized as ZNodes, each serving a specific function:
-
/controllerManages controller leader election -
/clusterContains the unique Kafka cluster identifier -
/brokersStores broker metadata -
/kafka-aclHouses SimpleAclAuthorizer ACL storage -
/adminContains Kafka admin tool metadata -
/isr_change_notificationTracks changes to In-Sync Replicas -
/log_dir_event_notificationNotifies the controller about log directory events -
/delegation_tokenStores delegation tokens -
/controller_epochTracks controller changes -
/consumersLists Kafka consumers -
/configMaintains entity configuration[6]
ZooKeeper manages the brokers in a Kafka cluster by maintaining a list of active brokers and coordinating operations between them. Brokers send heartbeat messages to ZooKeeper to confirm they are functioning correctly. These heartbeats allow ZooKeeper to identify when a broker becomes unavailable, enabling it to initiate recovery processes[9].
When a partition leader fails, ZooKeeper coordinates the election of a new leader from among the available follower replicas. The leadership transition is managed by the controller broker, which monitors ZooKeeper to detect changes in broker availability. This mechanism ensures that Kafka can maintain high availability even when individual brokers fail[9].
In earlier versions of Kafka, ZooKeeper stored consumer offsets, enabling consumers to track their progress through topic partitions. While newer Kafka versions store offsets in internal Kafka topics, ZooKeeper still provides essential coordination services for consumer groups, facilitating proper partition assignment and balancing among consumers[16].
Setting up ZooKeeper properly is crucial for a reliable Kafka deployment. The configuration must balance performance, reliability, and resource utilization to ensure optimal operation.
The most important ZooKeeper configuration options include:
-
tickTime: ZooKeeper's basic time unit in milliseconds, used for heartbeats and session timeouts. Default is typically 2000 ms. -
dataDir: The directory where ZooKeeper stores transaction logs and snapshots of its in-memory database. -
clientPort: The port where clients connect to ZooKeeper, defaulting to 2181[11].
A basic ZooKeeper configuration file might look like:
tickTime=2000 dataDir=/var/lib/zookeeper/ clientPort=2181
For production environments, deploying a cluster of replicated ZooKeeper instances (known as an ensemble) is strongly recommended. ZooKeeper clusters typically consist of an odd number of nodes to facilitate majority-based decision making[11].
The cluster's fault tolerance depends on its size:
-
A 3-node cluster can tolerate 1 node failure
-
A 5-node cluster can tolerate 2 node failures
-
A 7-node cluster can tolerate 3 node failures[11]
For proper cluster configuration, additional parameters are necessary:
initLimit=10 syncLimit=5 server.1=zk1-hostname:2888:3888 server.2=zk2-hostname:2888:3888 server.3=zk3-hostname:2888:3888
Where:
-
initLimitdefines the time for ZooKeeper followers to connect to the leader -
syncLimitspecifies how long followers can be out of sync with the leader -
server.xentries define the cluster members with their communication ports[11]
Proper performance tuning of ZooKeeper is essential for maintaining a healthy Kafka cluster. Poor ZooKeeper performance can lead to instability across the entire Kafka ecosystem.
Several key parameters affect ZooKeeper performance in a Kafka environment:
-
zookeeper.session.timeout.ms: Determines how long ZooKeeper waits for heartbeat messages before considering a broker unavailable. Setting this too high delays failure detection, while setting it too low may cause unnecessary leadership reassignments. -
jute.maxbuffer: A Java system property controlling the maximum size of data a ZNode can contain. The default is one megabyte, but production environments may require higher values. -
maxClientCnxns: Limits the number of concurrent connections from a client IP. This may need to be increased in environments with high connection demands[16].
Cloudera recommends using a dedicated 3-5 machine ZooKeeper ensemble solely for Kafka, as co-locating ZooKeeper with other applications can cause service disruptions[16].
Implementing best practices for ZooKeeper deployment and management can significantly enhance the stability and performance of a Kafka cluster.
-
Dedicated Hardware : Deploy ZooKeeper on dedicated machines separate from Kafka brokers to prevent resource contention and ensure performance isolation.
-
Appropriate Sizing : Use an odd number of ZooKeeper instances (typically 3, 5, or 7) based on your required fault tolerance level.
-
Storage Configuration : Place the ZooKeeper
dataDiron a separate disk device to minimize latency, preferably using SSDs for better performance[11]. -
Network Configuration : Ensure low-latency, reliable network connections between ZooKeeper nodes and between ZooKeeper and Kafka brokers.
-
ACL Implementation : Configure appropriate access control lists (ACLs) for ZooKeeper paths used by Kafka, following the principle of least privilege.
-
Enable ZooKeeper ACLs : Set the
zookeeper.set.aclproperty totruein secure Kafka clusters to enforce access controls[6]. -
Secure Credentials : Use SASL authentication to secure the connection between Kafka and ZooKeeper, particularly in production environments.
-
Regular Monitoring : Continuously monitor ZooKeeper health metrics, including latency, request rates, and connection counts.
-
Consistent Configuration : Ensure all ZooKeeper nodes have identical configuration to prevent operational inconsistencies.
-
Backup Strategy : Implement regular backups of ZooKeeper data to facilitate recovery from catastrophic failures.
Several common issues can affect the ZooKeeper-Kafka relationship, requiring specific troubleshooting approaches.
One frequent issue is cluster ID inconsistency, which produces errors like "The Cluster ID doesn't match stored clusterId in meta.properties." This typically occurs when Kafka logs are stored in a persistent folder while ZooKeeper data is in a temporary folder, or vice versa. After system restarts, temporary data gets cleared, causing configuration mismatches[7].
To resolve this issue:
-
Delete the
meta.propertiesfile in the Kafka log directory -
Ensure both Kafka logs and ZooKeeper data are stored in similar directory types (both temporary or both persistent)
-
Restart ZooKeeper first, then Kafka[7]
ZooKeeper downtime can cause a Kafka cluster to enter a non-consensus state that can be difficult to recover from. In severe cases, it may be necessary to restart all ZooKeeper nodes followed by all Kafka nodes to restore proper operation[17].
To minimize the impact of ZooKeeper failures:
-
Implement robust monitoring to detect ZooKeeper issues early
-
Use appropriate timeout settings to balance between quick failure detection and avoiding false positives
-
Have clear recovery procedures documented and tested before incidents occur
Connection problems between Kafka and ZooKeeper are common, especially in containerized environments or complex network setups. These can manifest as broker failures, topic creation failures, or consumer group coordination issues.
When troubleshooting connection problems:
-
Verify network connectivity between Kafka brokers and ZooKeeper nodes
-
Check firewall rules and security group settings
-
Ensure hostname resolution works correctly in both directions
-
Validate that configured timeouts are appropriate for the network environment
The Kafka community has been working to remove the ZooKeeper dependency through KIP-500 (Kafka Improvement Proposal 500), which introduces a new consensus protocol called KRaft (Kafka Raft Metadata mode).
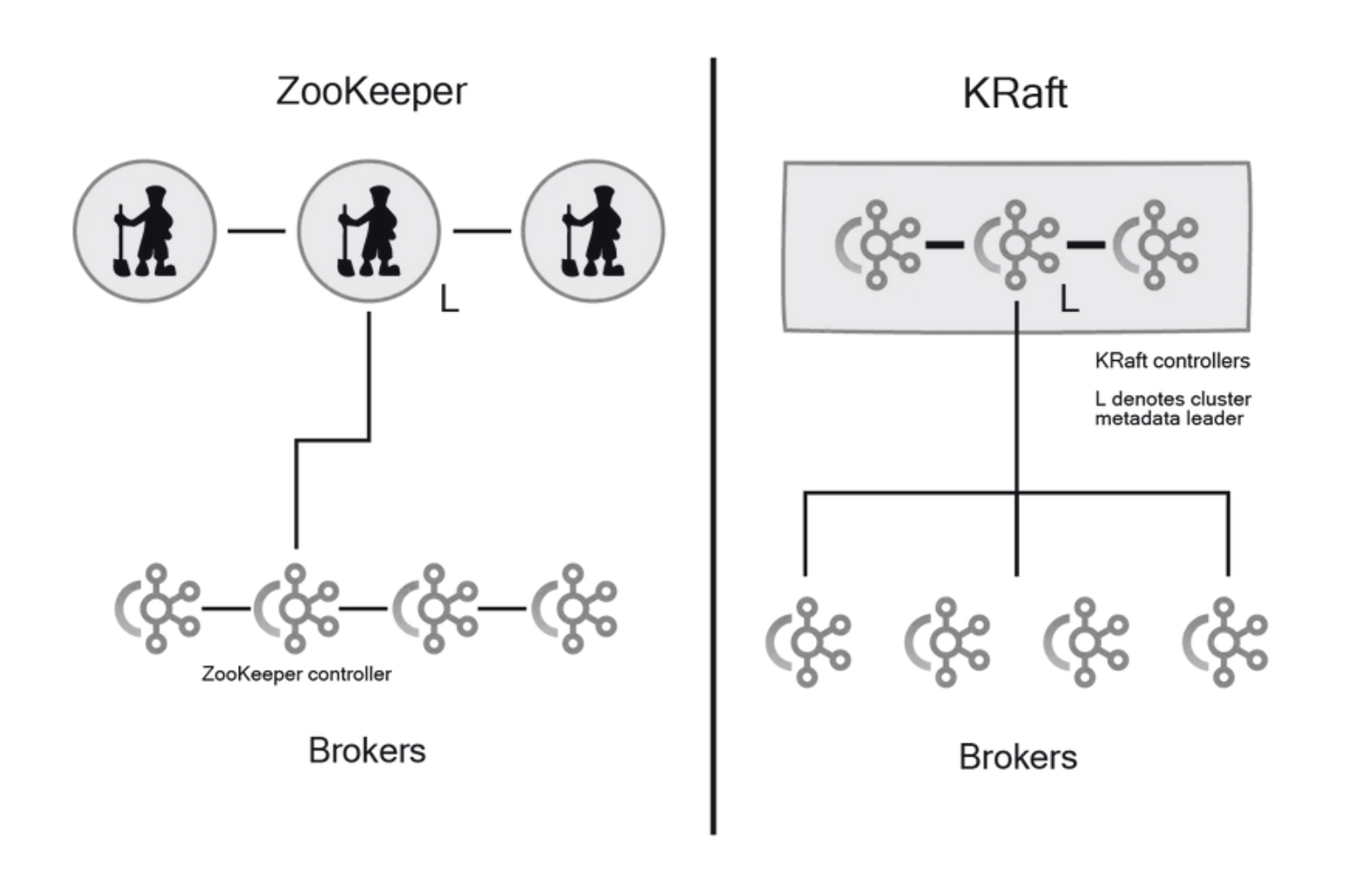
KRaft is Kafka's implementation of the Raft consensus protocol, designed to replace ZooKeeper for metadata management. With KRaft, Kafka stores metadata in internal topics and manages consensus through dedicated controller nodes, eliminating the need for an external ZooKeeper cluster[8].
KRaft was marked as production-ready with the release of Apache Kafka 3.3.1 in October 2022, representing a significant milestone in Kafka's architectural evolution[8].
The transition to KRaft offers several significant advantages:
-
Simplified Architecture : KRaft eliminates the need to manage a separate ZooKeeper cluster, reducing operational complexity.
-
Improved Scalability : KRaft can handle significantly more partitions per cluster—potentially millions compared to hundreds of thousands with ZooKeeper.
-
Better Performance : By optimizing the consensus protocol specifically for Kafka's requirements, KRaft provides faster metadata operations and quicker recovery from failures.
-
Reduced Resource Usage : Consolidating components reduces the overall resource footprint of a Kafka deployment[14].
KRaft supports two deployment modes:
-
Dedicated Mode : Some nodes are designated exclusively as controllers (with
process.roles=controller), while others function solely as brokers (withprocess.roles=broker). -
Shared Mode : Some nodes perform both controller and broker functions (with
process.roles=controller,broker)[8].
The appropriate mode depends on the cluster size and expected workload.
ZooKeeper has been a fundamental component of Apache Kafka's architecture since its inception, providing essential coordination services that enable Kafka's distributed operation. Understanding ZooKeeper's role, proper configuration, and best practices is crucial for maintaining a reliable Kafka deployment.
While ZooKeeper has served Kafka well, the industry is moving toward the KRaft consensus protocol, which offers improved scalability, performance, and operational simplicity. As Kafka continues to evolve, organizations should prepare for this architectural shift while ensuring their current ZooKeeper deployments follow best practices to maintain stability and performance.
Whether using the traditional ZooKeeper-based architecture or transitioning to KRaft, a deep understanding of these coordination mechanisms remains essential for successfully operating Kafka in production environments.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays