Apache Kafka vs. ActiveMQ: Differences & Comparison
ActiveMQ and Kafka are two powerful open-source messaging technologies, but they serve different purposes and excel in different scenarios. This blog provides a detailed comparison of these technologies to help you make informed decisions about which one best suits your specific requirements.
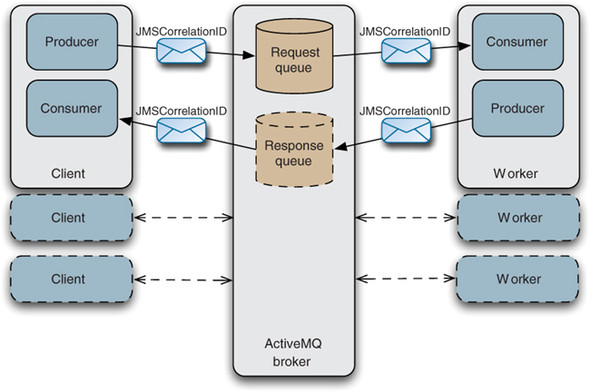
Apache ActiveMQ is a traditional message broker that implements the Java Message Service (JMS) API. It's designed for flexible asynchronous messaging with support for various messaging protocols[1][2]. ActiveMQ comes in two flavors:
-
ActiveMQ Classic : The original implementation
-
ActiveMQ Artemis : A newer, more performant implementation[1]
Apache Kafka is a distributed event streaming platform designed for high-throughput, fault-tolerant, publish-subscribe messaging. It's optimized for handling real-time data feeds and building scalable data pipelines[1][3].
One of the fundamental differences between these technologies lies in their architectural approach:
-
ActiveMQ follows a "complex broker, simple consumer" model. The broker handles message routing, maintains consumer state, tracks message consumption, and manages redelivery[1].
-
Kafka employs a "simple broker, complex consumer" approach. The broker's responsibilities are minimized, while consumers manage more complex functionality like tracking offsets and handling message processing logic[1].
|
Feature |
ActiveMQ |
Kafka |
|---|---|---|
| Messaging Pattern |
Supports both point-to-point (queues) and publish-subscribe (topics) |
Primarily publish-subscribe with topics and partitions |
| Message Delivery |
Push and pull mechanisms |
Pull-based consumption (long polling) |
| Consumption Model |
Messages typically consumed once |
Messages remain available for multiple consumers |
| Message Retention |
Usually short-term |
Can store data indefinitely |
Kafka outperforms ActiveMQ in terms of raw throughput capacity:
-
ActiveMQ provides good throughput and low latency for medium workloads. ActiveMQ Artemis offers better performance than Classic, thanks to its asynchronous, non-blocking architecture[1][12].
-
Kafka is designed for extremely high throughput (millions of messages per second) with low latencies (milliseconds). It's optimized for handling massive data streams at scale[1][2].
The platforms take different approaches to scaling:
-
ActiveMQ scales vertically by adding more resources to a single broker. It supports networks of brokers and primary/replica configurations, but isn't designed for hyper-scale scenarios[1][12].
-
Kafka scales horizontally by distributing data across multiple partitions and nodes. It can handle petabytes of data and trillions of messages per day across hundreds or thousands of brokers[1][5].
-
ActiveMQ supports multiple messaging protocols including OpenWire, AMQP, MQTT, STOMP, REST, and others[1][2].
-
Kafka uses its own binary protocol over TCP, requiring Kafka-specific clients[1][10].
-
ActiveMQ Classic uses KahaDB (file-based storage) or JDBC-compliant databases for persistence. ActiveMQ Artemis can use JDBC databases but recommends its built-in file journal. Both typically store data for short periods[1].
-
Kafka stores messages on disk in an append-only log structure, allowing for indefinite data retention. This approach enables event sourcing and replay capabilities[1][11].
-
ActiveMQ offers high availability through networks of brokers (Classic) or live-backup groups (Artemis). Client failover can be automatic or manually implemented[1].
-
Kafka replicates data across multiple nodes for fault tolerance. It can replicate data across different clusters in different datacenters or regions, providing strong durability guarantees[1][3].
ActiveMQ is particularly well-suited for:
-
Flexible asynchronous messaging - When you need both point-to-point and publish-subscribe patterns with various messaging protocols[1].
-
Interoperability - When you need to connect systems using different programming languages and protocols[1].
-
Transactional messaging - When you require guaranteed message delivery, ordering, and atomic operations[1].
-
Enterprise integration patterns - For implementing patterns like message filtering, routing, and request-reply communications[1].
Kafka excels in the following scenarios:
-
High-throughput data pipelines - For handling large volumes of real-time data across multiple producers and consumers[1][9].
-
Stream processing - When you need built-in stream processing capabilities or integration with stream processing frameworks[1].
-
Event sourcing - When you need an immutable, ordered, and replayable record of events[1].
-
Log aggregation - For centralizing and analyzing log data in real-time[1].
-
Data integration - When connecting diverse systems with numerous source and sink connectors[1][5].
-
ActiveMQ may not be appropriate for small-scale messaging systems with simple requirements or primarily batch-oriented processing needs[2][5].
-
Kafka might be overkill for applications dealing with small amounts of data that don't require real-time processing or when using a centralized messaging system is sufficient[5].
Both technologies support multiple programming languages:
-
ActiveMQ offers clients for Java, .NET, C++, Erlang, Go, Haskell, Node.js, Python, and Ruby. Any JMS-compliant client can interact with ActiveMQ[1].
-
Kafka provides official and community clients for Java, Scala, Go, Python, C/C++, Ruby, .NET, PHP, Node.js, and Swift[1][5].
-
ActiveMQ has limited third-party integrations compared to Kafka, with frameworks like Apache Camel and Spring being the primary options[1][6].
-
Kafka features a rich ecosystem of source and sink connectors for hundreds of systems, including ActiveMQ itself[1][8].
-
ActiveMQ has a smaller community compared to Kafka, with fewer educational resources, meetups, and events[1][12].
-
Kafka benefits from a large, active community and extensive ecosystem support, contributing to its wider adoption[1][12].
Organizations sometimes need to use both technologies together. This can be accomplished through:
-
Kafka Connect - Using source/sink connectors to bridge the technologies[8].
-
Apache Camel - Building more complex routes between systems[6].
-
Custom bridges - Developing purpose-built applications to transfer messages between platforms[6].
When integrating ActiveMQ with Kafka, several challenges may arise:
-
Message duplication - Ensuring exactly-once delivery semantics across systems[6].
-
Performance bottlenecks - The bridge itself can become a throughput limitation[6].
-
Transactional consistency - Maintaining transactionality between systems[6].
-
Schema management - Keeping message formats consistent across platforms[6].
Several factors influence the total cost of ownership:
-
Kafka may be more expensive due to its design for hyper-scale scenarios, requiring more infrastructure[1].
-
Data storage costs are generally higher with Kafka due to its indefinite persistence model[1].
-
Integration costs may be higher with ActiveMQ due to fewer ready-made connectors[1].
-
Staffing costs might be higher for ActiveMQ due to a smaller pool of skilled professionals[1].
Both technologies are available as managed services:
-
ActiveMQ : AWS Amazon MQ, Red Hat AMQ Broker, and OpenLogic[1][2].
-
Kafka : More options including Confluent, Amazon MSK, Aiven, Quix, Instaclustr, and Azure HDInsight[1][7].
-
Choose the right broker implementation - Consider Artemis for better performance in modern deployments[1].
-
Select appropriate persistence mechanism - File journal for Artemis offers better performance than database storage[1].
-
Configure proper message expiration - To manage resource utilization[12].
-
Implement client-side failover logic - For improved reliability[1].
-
Partition strategy - Design appropriate partitioning to enable parallelism and scalability[5].
-
Consumer group design - Properly configure consumer groups for efficient workload distribution[11].
-
Retention policy configuration - Set appropriate retention periods based on use case requirements[1].
-
Replication factor settings - Balance between durability and resource usage[3].
ActiveMQ and Kafka serve different needs in the messaging ecosystem. ActiveMQ is a traditional message broker focused on flexible messaging patterns and protocol support, making it suitable for enterprise integration scenarios. Kafka is a distributed streaming platform designed for high-throughput data processing, excelling in real-time analytics and large-scale event processing.
The choice between these technologies should be driven by your specific requirements, considering factors such as throughput needs, scalability requirements, messaging patterns, integration capabilities, and operational considerations. For some use cases, using both technologies together may be the optimal solution, leveraging the strengths of each platform.
Understanding the fundamental differences in their architectures—ActiveMQ's "complex broker, simple consumer" versus Kafka's "simple broker, complex consumer"—provides insight into their design philosophies and helps guide implementation decisions. Both technologies continue to evolve, with strong community and commercial support ensuring their relevance in modern distributed systems.
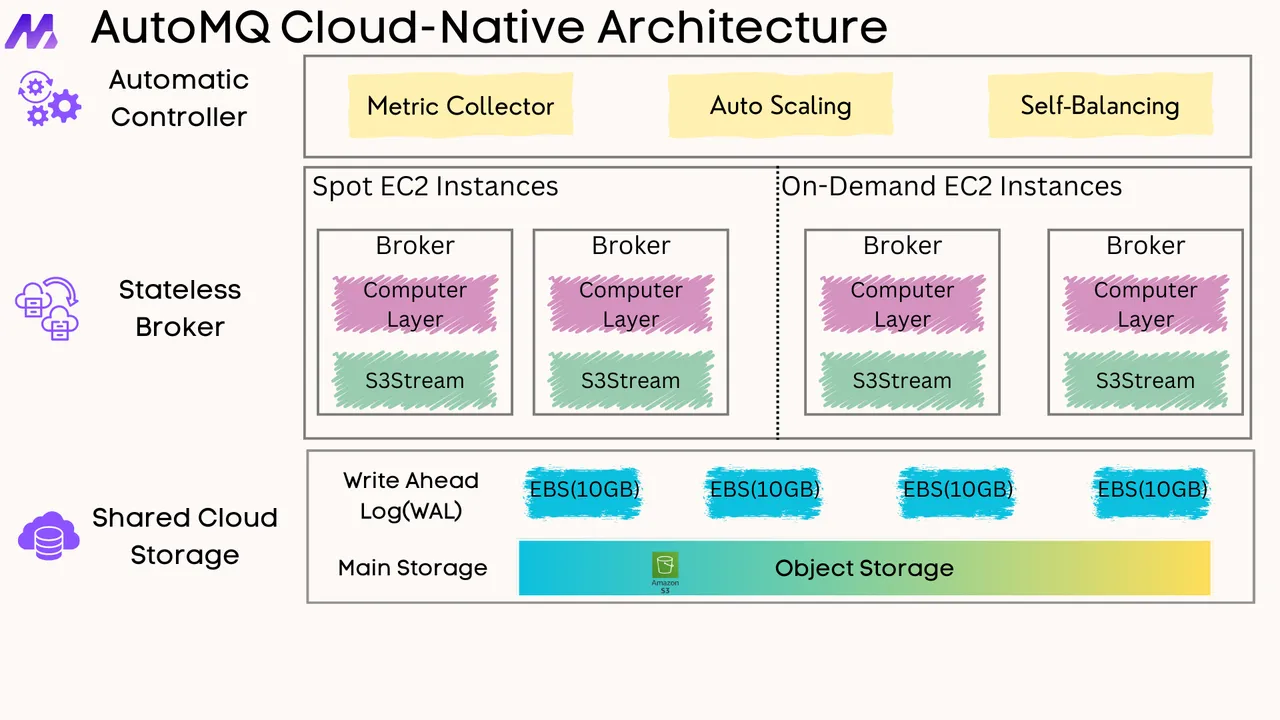
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging