Apache Kafka vs. Apache Pulsar: Differences & Comparison
Apache Kafka and Apache Pulsar are powerful distributed messaging platforms that serve as the backbone for modern data streaming architectures. This comparison examines their key differences, architectural approaches, performance characteristics, and use cases to help you make an informed decision for your data pipeline needs.
Before diving into detailed comparisons, here's a summary of key findings: Kafka excels in pure event streaming with higher throughput and simpler architecture, while Pulsar offers a more versatile platform with multi-tenancy, geo-replication, and independent scaling of compute and storage. Kafka has a more mature ecosystem and documentation, while Pulsar provides greater flexibility for diverse messaging patterns.

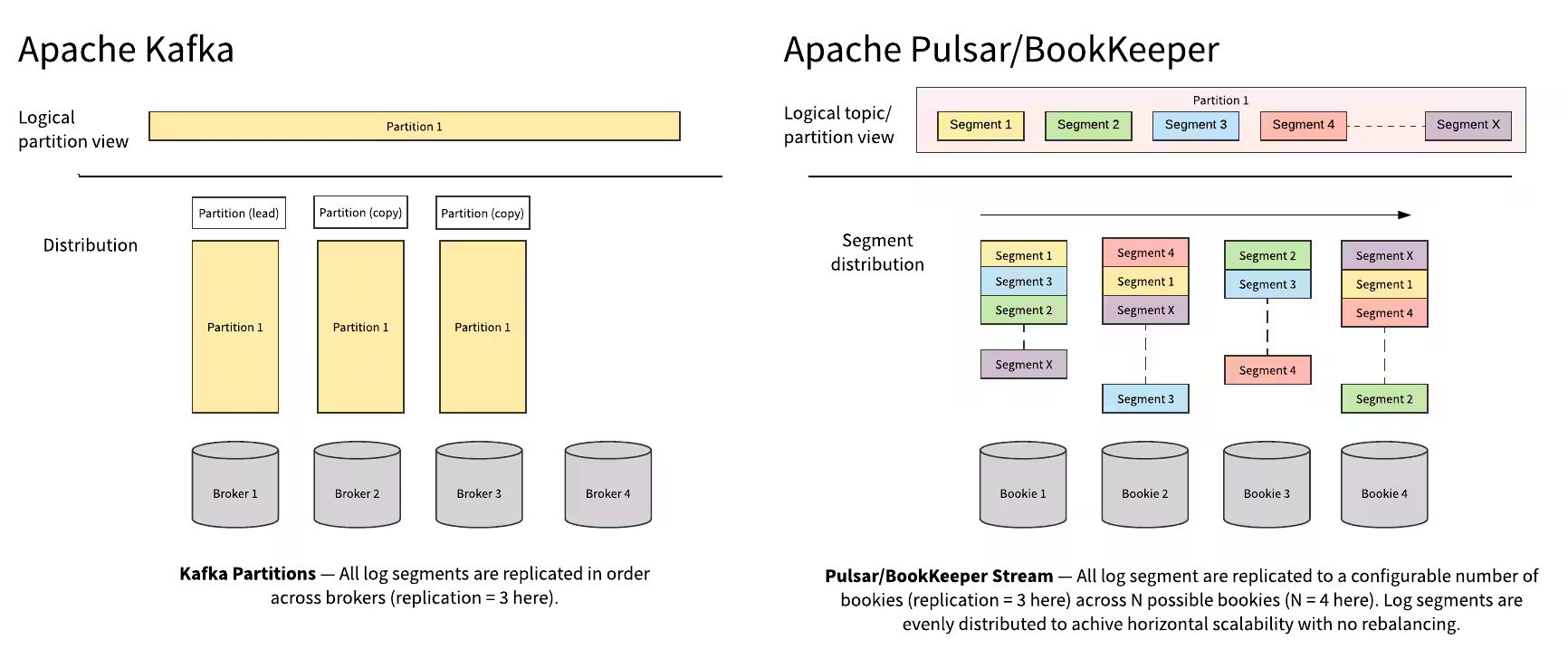
Kafka follows a partition-centered, monolithic architecture where brokers handle both data serving and storage functions. At its core, Kafka is based on a distributed commit log abstraction, with partitions stored directly on broker nodes[1]. Each broker stores partitions on its local disk, and data is replicated to other brokers for fault tolerance[6].
Pulsar implements a multi-layered architecture that separates compute (brokers) from storage (Apache BookKeeper)[5]. This creates a two-tier system where:
-
Brokers handle message routing and delivery
-
BookKeeper nodes (called "bookies") handle durable storage
-
Partitions are subdivided into segments distributed across bookies[6][16]
This separation allows Pulsar to scale storage independently from compute, improving flexibility and resource utilization[5].
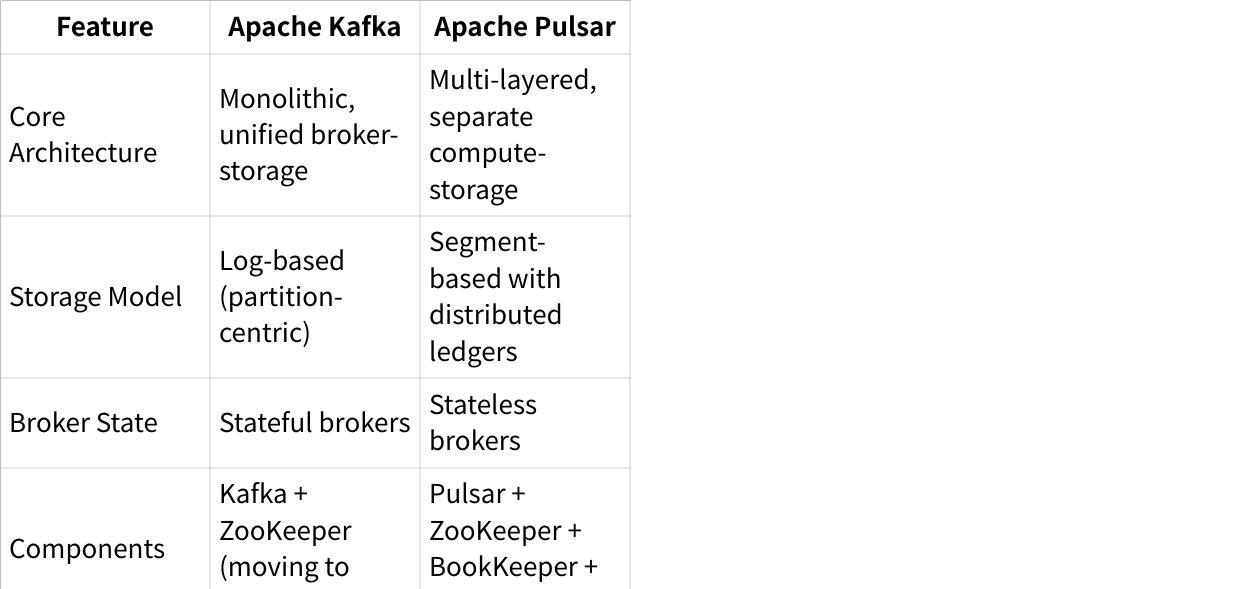
The fundamental difference is that Kafka tightly couples compute and storage in the same nodes, while Pulsar separates them[5][15]. This affects scalability, fault tolerance, and resource management.
According to benchmarks, Kafka provides higher throughput in some scenarios, writing up to 2x faster than Pulsar in certain tests[1]. However, performance heavily depends on configuration, hardware, and specific workloads. Pulsar's segment-oriented architecture can achieve excellent throughput when properly tuned[14].
Kafka in its default configuration is faster than Pulsar in many latency benchmarks, providing as low as 5ms latency at p99 percentile at higher throughputs[1]. Pulsar's push model can potentially reduce latency compared to Kafka's pull model in certain scenarios[15].
Pulsar excels in horizontal scalability due to its segmented, tiered architecture:
-
Adding brokers requires no data rebalancing
-
New brokers fetch data from BookKeeper on demand
-
Storage can scale independently from compute[5]
With Kafka, scaling requires redistributing data across new brokers, which can be slow and complex. Pinterest reported: "With thousands of brokers running in the cloud, we have broker failures almost every day"[7].
Kafka is primarily designed for event streaming with its distributed log model. Pulsar supports multiple messaging patterns natively:
-
Queuing (via shared subscriptions)
-
Pub-sub (via exclusive subscriptions)
-
Event streaming
-
Key-Shared subscription type for ordering by key[4][5]
This versatility makes Pulsar suitable for diverse messaging requirements.
Kafka stores data directly on broker disks with retention based on time or size limits. Pulsar offers tiered storage, allowing older data to be offloaded to cloud storage (e.g., S3) while maintaining accessibility[5]. Pulsar's approach supports millions of topics efficiently[10].
Both systems support various message delivery guarantees:
-
At-most-once delivery
-
At-least-once delivery
-
Exactly-once semantics[4][8]
Pulsar's message acknowledgment happens at the individual message level, while Kafka uses an offset-based sequential acknowledgment system[6].
Pulsar provides built-in multi-tenancy with resource isolation at tenant and namespace levels. Kafka's multi-tenancy capabilities are more limited and often require additional tools[3][5]. Both support geo-replication, but Pulsar offers it at both topic and namespace levels with built-in capabilities[15].

Kafka excels in:
-
High-throughput event streaming applications
-
Log aggregation and processing
-
Real-time analytics pipelines
-
Stream processing with exactly-once semantics
-
Cases where simple, proven architecture is preferred[1][19]
Pulsar is well-suited for:
-
Applications requiring both queuing and streaming in one system
-
Multi-tenant environments with diverse workloads
-
Cloud-native and Kubernetes-based deployments
-
Systems needing geo-replication and disaster recovery
-
Use cases requiring millions of topics[5][10][19]
Kafka has broader adoption due to its maturity, used by thousands of organizations from internet giants to car manufacturers. Pulsar adoption is growing, with companies like Tencent, Discord, Flipkart, and Intuit using it in production[1][10].
Kafka has a medium-weight architecture consisting of ZooKeeper and Kafka brokers (though Kafka is moving to KRaft). Pulsar has a heavier architecture requiring management of four components: Pulsar brokers, BookKeeper, ZooKeeper, and RocksDB[14][19].
Kafka has a rich ecosystem of monitoring and management tools. Pulsar offers Pulsar Manager as a web UI, comparable to Kafka's third-party tools like Conduktor[2]. Both integrate with standard monitoring platforms.
Both systems offer cloud-native capabilities and Kubernetes operators. Pulsar is designed with cloud compatibility in mind and works well with Kubernetes[9][19]. Both are available as managed services, such as StreamNative Cloud for Pulsar[9].
Kafka has extensive documentation (over half a million words), numerous books, tutorials, and active community forums. Pulsar's documentation is less comprehensive, with users reporting issues with outdated information[10][19].
Kafka has a broader ecosystem of connectors and third-party tools. Pulsar offers Kafka-compatible APIs to leverage existing Kafka tools and clients, simplifying migration[16].
Both systems provide robust security features including:
-
Authentication and authorization
-
Encryption for data in transit and at rest
-
Role-based access controls
Pulsar had a notable vulnerability related to improper certificate validation that allowed manipulator-in-the-middle attacks, which has since been fixed[11].
Choose Kafka for:
-
Pure event streaming with high throughput requirements
-
Simpler architecture with lower operational complexity
-
Applications where extensive documentation and community support are critical
-
Cases where the mature ecosystem of integrations is valuable
Choose Pulsar for:
-
Applications requiring both queuing and streaming capabilities
-
Multi-tenant environments needing resource isolation
-
Systems that benefit from independent scaling of compute and storage
-
Use cases requiring efficient handling of millions of topics
-
Environments where geo-replication is critical
Both systems continue to evolve, with Kafka adding features to address some of Pulsar's advantages, and Pulsar improving performance and documentation to compete with Kafka's strengths.
The ideal choice depends on your specific requirements, team expertise, and architectural goals. For pure event streaming at scale, Kafka remains the industry standard, while Pulsar offers a more versatile platform for diverse messaging patterns and cloud-native deployments.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging
-
Vulnerability in Apache Pulsar Allowed Manipulator-in-the-Middle Attacks
-
Comparing Pulsar and Kafka: Segment-based Architecture Benefits
-
The Ultimate Guide to Apache Pulsar: Everything You Need to Know
-
How Pulsar's Architecture Delivers Better Performance Than Kafka
-
Kafka vs Pulsar: Choosing the Right Event Streaming Powerhouse
-
Performance Comparison Between Apache Pulsar and Kafka: Latency
-
Kafka vs Pulsar: Choosing the Right Stream Processing Platform
-
Kafka Vs Pulsar: Difference between Apache Kafka and Pulsar?