Apache Kafka vs. Instaclustr: Differences & Comparison
Apache Kafka and Instaclustr Managed Kafka represent two different approaches to implementing event streaming platforms - self-managed open source versus managed service. This analysis compares architectural differences, features, performance, cost considerations, and integration capabilities to help organizations make informed decisions. Key findings show that Instaclustr offers significant operational advantages through its fully managed service with expert support and security compliance, while pure Apache Kafka provides greater flexibility and control for organizations with existing expertise.
Apache Kafka is an open-source distributed event streaming platform originally developed by LinkedIn and now maintained by the Apache Software Foundation. It's designed for high-throughput, fault-tolerant messaging and has become the de facto standard for event streaming[6][18]. Kafka allows for publishing and subscribing to streams of records, storing them durably, and processing streams as they occur.
Instaclustr, on the other hand, provides a managed version of Apache Kafka, handling the operational complexities while maintaining 100% open-source compatibility[1][11]. This represents a fundamental choice organizations must make: self-manage Kafka or opt for a managed service.
The architectural differences between Apache Kafka and Instaclustr Managed Kafka primarily revolve around deployment, management, and operational responsibilities.
|
Feature |
Apache Kafka |
Instaclustr Managed Kafka |
|---|---|---|
| Deployment |
Self-managed on any infrastructure |
Managed deployment on AWS, GCP, Azure |
| Cluster Management |
Manual configuration and maintenance |
Automated deployment and management |
| Infrastructure |
Self-provisioned and maintained |
Managed by Instaclustr |
| ZooKeeper/KRaft |
Self-managed |
Managed by Instaclustr |
| Monitoring |
Requires custom setup |
Built-in monitoring and alerting |
| Scaling |
Manual |
Simplified through management console |
| Version Control |
Full control |
Managed by Instaclustr |
Apache Kafka's architecture requires users to manage multiple components, including brokers, ZooKeeper (or KRaft in newer versions), producers, consumers, and connectors. This provides flexibility but demands expertise[11][18].
Instaclustr abstracts much of this complexity away, providing a managed cluster that includes "dedicated ZooKeeper and Kraft" and delivers "a highly performant, reliable, and scalable solution with low latency"[1][2].
The core Apache Kafka platform includes:
-
Distributed commit log architecture
-
Publish-subscribe messaging model
-
Horizontal scalability
-
Fault tolerance and high availability
-
Stream processing capabilities (via Kafka Streams)
-
Exactly-once semantics
-
Retention policies for data
-
Replication for fault tolerance
Apache Kafka provides these capabilities but requires configuration, tuning, and ongoing maintenance[18].
Instaclustr builds upon Apache Kafka's foundation while adding managed service capabilities:
-
100% Open Source Apache Kafka[1]
-
24×7 Expert Support with "a dedicated committer on staff"[1][17]
-
SOC 2 Security Certifications and PCI-DSS compliance[1]
-
Automated Health Checks that "monitors your schema and Kafka usage"[1]
-
Run-In-Your-Own-Account (RIYOA) or Run-In-Instaclustr-Account (RIIA) options[1]
-
Experience managing "200 Million+ Node Hours" and "over 9PBs of data"[1]
-
Migration capabilities from "proprietary (e.g. Confluent) or self-managed Kafka clusters"[17]
These additional features aim to reduce operational overhead and provide expertise that might otherwise be difficult or expensive to obtain internally.
While the search results don't provide direct performance benchmarks comparing Apache Kafka and Instaclustr Managed Kafka, general indications suggest that properly configured and tuned systems should deliver similar performance since Instaclustr uses the same open-source Apache Kafka codebase.
A relevant comparison from search result[9] benchmarked Apache Kafka against Redpanda (another Kafka-compatible platform), finding that "Kafka performs better than Redpanda with a more realistic workload - basically more producers, consumers and partitions"[9]. This demonstrates Kafka's performance capabilities under realistic conditions.
Both solutions can scale effectively, but with different operational implications:
-
Apache Kafka : Manual scaling requires expertise to balance partitions, manage broker resources, and handle scaling operations without disruption.
-
Instaclustr Managed Kafka : Provides simplified scaling through its management console, handling the underlying complexity automatically.
Instaclustr claims their platform "delivers a highly performant, reliable, and scalable solution with low latency" and is "the best way to run Kafka in the cloud"[1].
The operational aspects represent perhaps the most significant difference between the two options.
Operating Apache Kafka yourself requires:
-
Kafka expertise for installation and configuration
-
Ongoing monitoring and maintenance
-
Performance tuning and optimization
-
Security implementation and management
-
Cluster scaling as needed
-
Upgrade planning and execution
-
Backup and disaster recovery procedures
These responsibilities require dedicated resources with specialized knowledge[13][18].
Instaclustr handles most operational tasks:
-
Deployment and initial configuration
-
24/7 monitoring and support
-
Security compliance (SOC 2, PCI-DSS)[1]
-
Automated health checks and maintenance
-
Managed upgrades
-
Backup and recovery
According to user reviews, "Instaclustr Managed Kafka [is] easier to use, set up, and administer" than self-managed Apache Kafka[7].
Self-managed Apache Kafka costs include:
-
Infrastructure (servers, storage, networking)
-
Personnel (Kafka administrators, operations)
-
Training and expertise development
-
Monitoring tools
-
Potential downtime costs
While the software itself is free, the total cost of ownership includes significant operational expenses[13][18].
Instaclustr's pricing model includes:
-
Subscription fees (not explicitly detailed in search results)
-
Reduced operational overhead and personnel costs
-
Potential infrastructure savings through optimization
-
Reduced risk of costly downtime
User comments suggest that "Instaclustr will beat confluent cost savings by a long shot, better support too and no licensing fees"[13], indicating potential cost advantages compared to other managed Kafka services.
Both platforms support Kafka's robust integration ecosystem, though with some differences:
|
Integration Aspect |
Apache Kafka |
Instaclustr Managed Kafka |
|---|---|---|
| Kafka Connect |
Full access |
Supported |
| Client Libraries |
All supported |
All supported |
| Stream Processing |
Kafka Streams, integration with Flink, Spark, etc. |
Similar capabilities |
| Proprietary Connectors |
Access to all connectors |
Some limitations with proprietary connectors |
Search result[8] highlights a potential challenge with Instaclustr: "io.confluent.connect.avro.AvroConverter is not part of the Apache Kafka distribution," indicating some compatibility issues with Confluent-specific components.
However, Instaclustr does facilitate integration with other systems, as demonstrated by documentation for integrating with RisingWave for data ingestion[2].
The Kafka ecosystem extends beyond just Kafka itself, and different providers offer varying levels of support for these components.
|
Provider |
Core Kafka |
Schema Registry |
Kafka Connect |
UI Tools |
Stream Processing |
Proprietary Extensions |
|---|---|---|---|---|---|---|
| Apache Kafka |
✓ |
Limited |
✓ |
Limited |
Kafka Streams |
None |
| Instaclustr |
✓ |
✓ |
✓ |
✓ |
✓ |
None (100% open source) |
| Confluent |
✓ |
✓ |
✓ |
✓ |
ksqlDB + Kafka Streams |
Several proprietary components |
Confluent positions itself as "an enterprise-ready, full-scale streaming platform that enhances Apache Kafka" with proprietary extensions[11], while Instaclustr emphasizes being "100% Open Source"[1].
The streaming platform landscape includes other options beyond Kafka and Instaclustr:
-
Redpanda : A Kafka-compatible platform written in C++ designed for high performance and simplicity. However, benchmarking suggests "Kafka performs better than Redpanda with a more realistic workload"[9]. Redpanda "is not 100% Kafka compatible, in particular, it doesn't support explicit partition assignment"[9].
-
Amazon MSK : AWS's managed Kafka service, mentioned in comparison contexts but not detailed in the search results[18].
-
Conduktor : While not a Kafka provider itself, Conduktor offers "The Enterprise Data Management Platform for Streaming" that works alongside Kafka installations to provide enhanced management capabilities[3].
For self-managed Apache Kafka:
-
Implement proper capacity planning
-
Configure appropriate replication factors
-
Optimize partition counts based on throughput needs
-
Tune producer and consumer configurations
-
Implement monitoring with tools like Prometheus and Grafana
-
Plan regular maintenance windows
-
Develop comprehensive backup strategies
For Instaclustr Managed Kafka:
-
Properly size clusters based on workload requirements
-
Utilize Instaclustr's health checks to optimize usage
-
Take advantage of Instaclustr's expertise through support
-
Implement appropriate security configurations
-
Review monitoring data regularly
-
Consider RIYOA vs. RIIA based on organizational needs
Self-managed Apache Kafka is typically more suitable when:
-
You have existing Kafka expertise in-house
-
Custom configurations or extensions are required
-
You need complete control over the infrastructure
-
Your organization has regulatory requirements that necessitate on-premises deployment
-
You're working with a tight budget and have available infrastructure capacity
Reviewers noted that Apache Kafka "meets the needs of their business better than Instaclustr Managed Kafka" in some scenarios[7].
Instaclustr Managed Kafka is typically more suitable when:
-
You lack dedicated Kafka expertise
-
You want to reduce operational overhead
-
Reliability and support are critical requirements
-
You need compliance certifications (SOC 2, PCI-DSS)
-
You prefer predictable operational costs
-
You want to focus on application development rather than infrastructure
Reviewers found "Instaclustr Managed Kafka easier to use, set up, and administer" and "preferred doing business with Instaclustr Managed Kafka overall"[7].
The choice between Apache Kafka and Instaclustr Managed Kafka ultimately depends on organizational needs, existing expertise, and resource availability. Apache Kafka provides maximum flexibility and control but requires significant operational expertise, while Instaclustr offers a managed experience that reduces operational burden at the cost of some configurability.
Organizations should consider:
-
Their level of in-house Kafka expertise
-
Operational resource availability
-
Cost sensitivity
-
Performance and scaling requirements
-
Integration needs with existing systems
-
Compliance and security requirements
By carefully evaluating these factors against the capabilities of each option, organizations can make an informed decision that best supports their streaming data infrastructure needs.
Apache Kafka remains a powerful choice for organizations seeking complete control over their event streaming infrastructure. However, this control comes at the cost of operational complexity and resource requirements.
Aiven for Apache Kafka bridges this gap by offering a fully managed solution that retains the core benefits of Apache Kafka while simplifying deployment, scaling, security management, and monitoring. Its multi-cloud support further enhances flexibility for modern enterprises.
Ultimately, the choice between these platforms depends on organizational priorities—whether they value control over infrastructure or prefer operational simplicity with guaranteed SLAs.
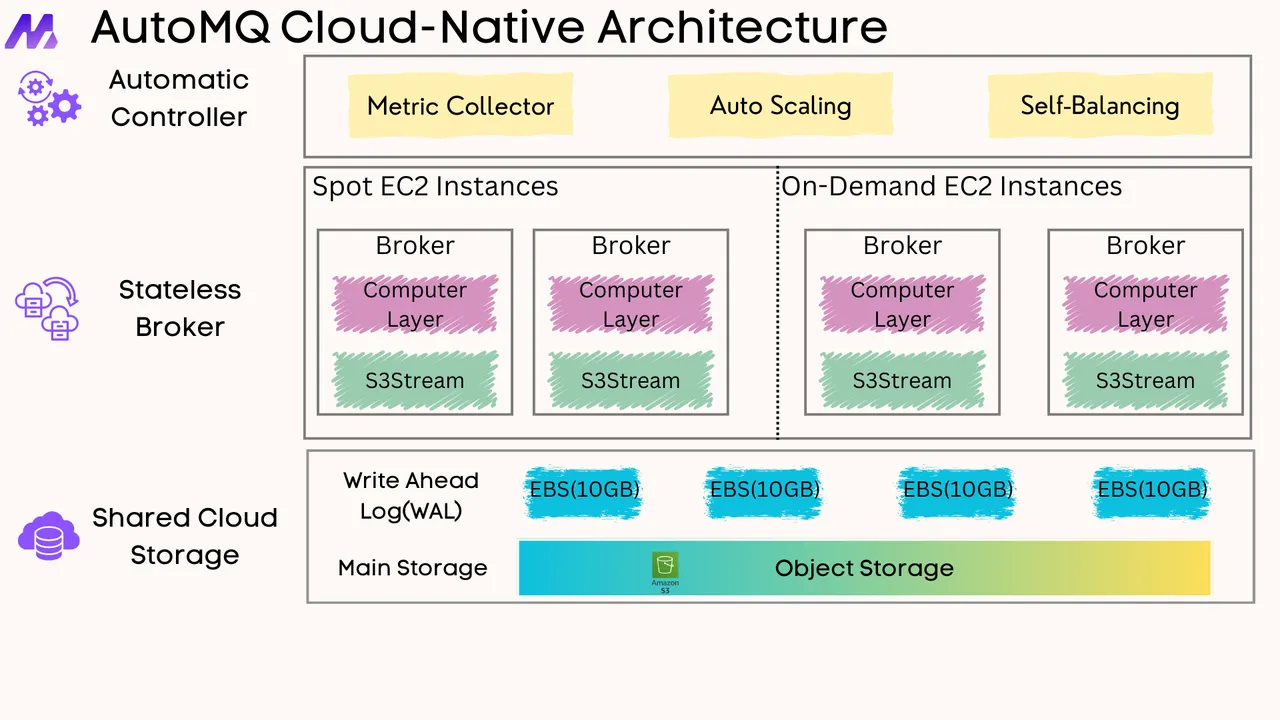
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging