Apache Kafka vs. RabbitMQ: Differences & Comparison
Before diving into the detailed comparison, here's the key takeaway: Kafka excels at high-throughput event streaming with long-term storage capabilities, while RabbitMQ offers flexible message routing with complex delivery patterns for general messaging needs.
RabbitMQ, first released in 2007 by Pivotal Software, is a message broker implementing the Advanced Message Queuing Protocol (AMQP). It's built in Erlang and designed as a general-purpose message broker that prioritizes end-to-end message delivery and flexible routing patterns[3][5].
Apache Kafka, released in 2011 by the Apache Software Foundation, is a distributed event streaming platform implemented in Java and Scala. It was specifically designed for high-throughput, fault-tolerant, publish-subscribe messaging with a focus on stream processing[1][3].

The architectural philosophies of these systems reflect their distinct purposes:
RabbitMQ uses a "complex broker, simple consumer" approach with several key components:
-
Exchanges : Receive messages from producers and route them based on attributes
-
Queues : Store messages until consumed
-
Bindings : Define relationships between exchanges and queues
-
Routing Keys : Determine how messages are routed to specific queues[1][3]
A RabbitMQ broker allows for low latency and complex message distributions through these components working together[1].
Kafka employs a "simple broker, complex consumer" philosophy with these components:
-
Topics : Categories to which messages are published
-
Partitions : Subdivisions of topics for parallelism
-
Brokers : Servers that store messages and serve client requests
-
Consumer Groups : Collections of consumers that process messages cooperatively[1][8]
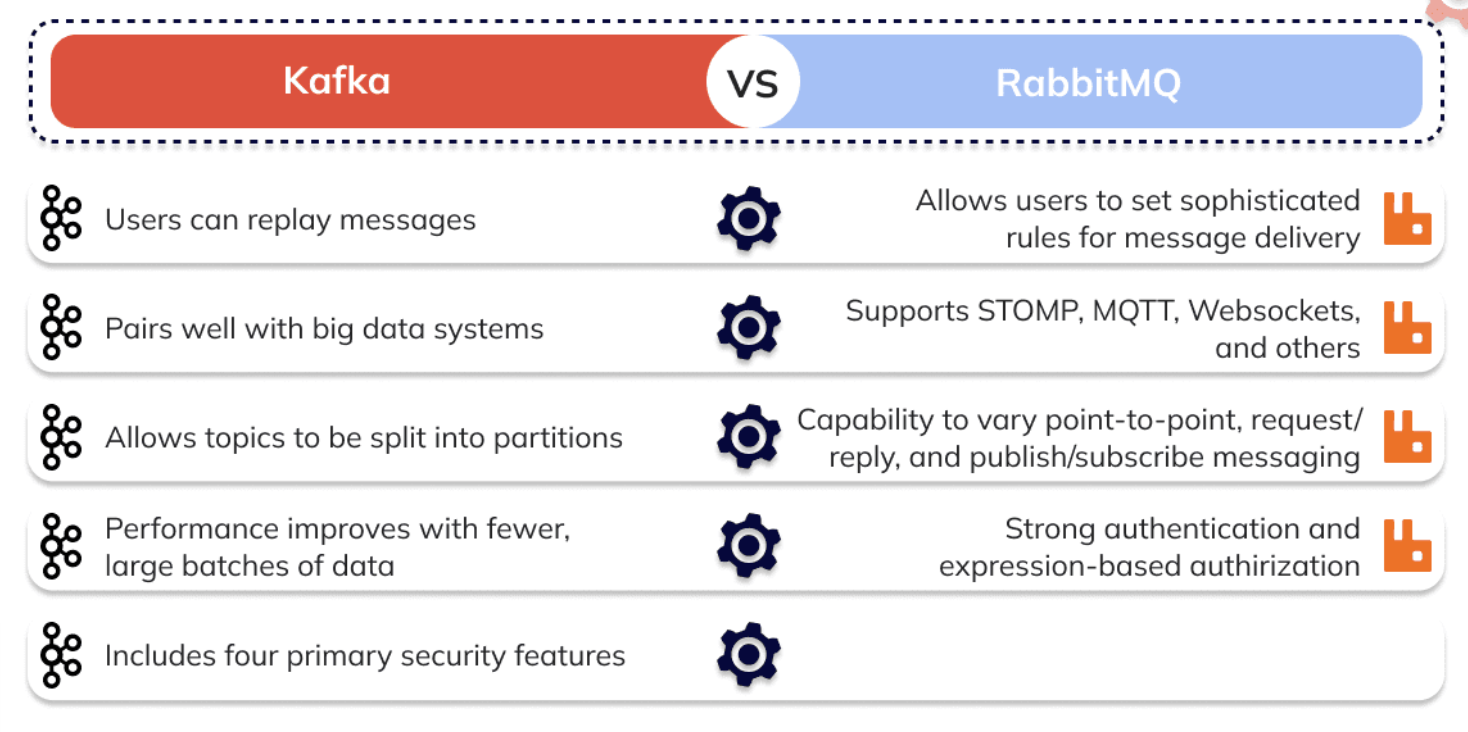
In Kafka, a producer sends messages to a topic regardless of whether consumers have retrieved them, similar to "a library which organizes messages on shelves with different genres"[1].
RabbitMQ offers sophisticated routing capabilities through different exchange types:
-
Direct exchanges: Route based on exact routing key matches
-
Topic exchanges: Route based on pattern-matching routing keys
-
Fanout exchanges: Broadcast to all bound queues
-
Header exchanges: Route based on message header attributes[1][3]
RabbitMQ uses a push mechanism and prevents overloading users by using a consumer-configured prefetch limit[3].
Kafka has a simpler routing model where:
-
Producers publish directly to specific topics
-
Messages are distributed across partitions
-
Consumers subscribe to topics and pull messages at their own pace[1][3]
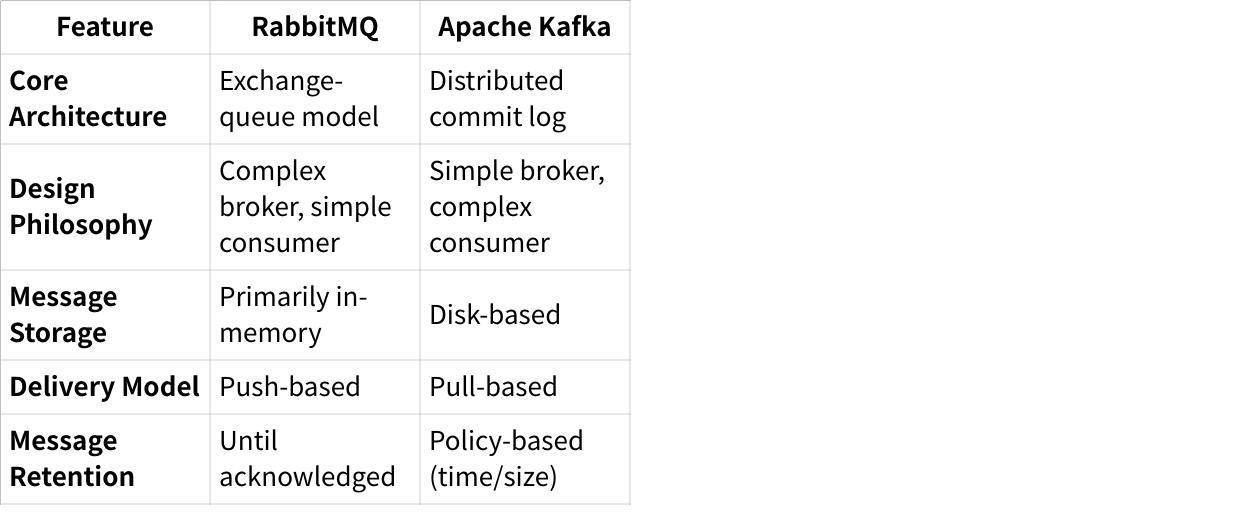
A fundamental difference between the two systems:
-
RabbitMQ : Messages are removed from queues once acknowledged by consumers (acknowledgment-based retention)[3].
-
Kafka : Messages are retained in the log until either a time restriction or size limit is met, regardless of consumption (policy-based retention)[1][3].
-
RabbitMQ : Can guarantee message ordering within a queue but not across queues.
-
Kafka : Guarantees ordering within a single partition but not across partitions[3].

Performance differences between Kafka and RabbitMQ are significant and should influence your architectural decisions:
According to benchmarks:
-
Kafka : Provides the highest throughput, writing 15x faster than RabbitMQ and 2x faster than Pulsar[2].
-
RabbitMQ : Typically handles 4K-10K messages per second, which is substantially lower than Kafka's capacity[3][9].

The latency characteristics reveal an interesting tradeoff:
-
RabbitMQ : Can achieve lower end-to-end latency than Kafka but only at significantly lower throughputs[2].
-
Kafka : Provides the lowest latency at higher throughputs while maintaining durability[2].
One source notes: "In practice, the operator needs to carefully provision RabbitMQ to keep the rates low enough to sustain these low latencies barring which the latency degrades quickly and significantly"[2].
-
RabbitMQ : Horizontal scaling is possible but can be complex. "Horizontal scaling is possible but can be complex" for RabbitMQ deployments[9].
-
Kafka : Designed for horizontal scaling through partition distribution across brokers. "Horizontal scaling is easy and efficient" with Kafka[9].
-
RabbitMQ : Achieves high availability through mirrored queues, but "RabbitMQ did not fare well with the overhead of replication, which severely reduced the throughput of the system"[2].
-
Kafka : Built with replication as a core feature, maintaining better performance even with replication enabled[2].
-
Broker Not Available : Occurs when a producer or consumer tries to connect to a broker that isn't running.
- Resolution: Check if the broker is running using commands like
ps -ef | grep kafkaand verify network connectivity[4].
- Resolution: Check if the broker is running using commands like
-
Leader Not Available : Happens when a leader for a partition is unavailable.
- Resolution: Ensure the broker has rejoined the cluster or force a leader election[4].
-
Offset Out of Range : Occurs when a consumer requests an offset that doesn't exist.
- Resolution: Configure consumers to use earliest or latest offset when out of range[4].
-
Request Timed Out : Usually indicates network issues or overloaded brokers.
- Resolution: Check network connectivity and broker resource utilization[4].
RabbitMQ excels in scenarios requiring:
-
Complex routing patterns with different exchange types
-
Traditional request/reply messaging patterns
-
Low-latency message delivery at moderate volumes
-
Multiple protocol support (AMQP, MQTT, STOMP)
-
Lightweight communication between microservices[5][9][11]
Kafka is better suited for:
-
High-volume event streaming applications
-
Real-time data processing and analytics
-
Log aggregation and monitoring
-
Building data pipelines for machine learning
-
Scenarios requiring message replay capabilities
-
Long-term data retention needs[5][9][11]
As one source succinctly puts it: "If you are looking for a system with low latency, supports complex routing, is relatively lightweight, and works well for microservice communication you want to go with RabbitMQ. However, if you are looking for real-time data streaming, integrating multiple sources, stream processing, large volumes of data, or permanent message storage you'd want to select Apache Kafka"[9].
-
RabbitMQ : Generally simpler to set up for small deployments but requires careful configuration for high availability.
-
Kafka : More complex initial setup but offers better built-in tools for distributed operations[6][11].
"Cost tends to be an inverse function of performance. Kafka as the system with the highest stable throughput, offers the best value (i.e., cost per byte written) of all the systems, due to its efficient design"[2].
|
Feature |
RabbitMQ |
Apache Kafka |
|---|---|---|
|
Founded |
2007 |
2011 |
|
Developed By |
Pivotal Software |
Apache Software Foundation |
|
Implementation Language |
Erlang |
Java and Scala |
|
License |
Mozilla Public License |
Apache License 2.0 |
|
Primary Purpose |
Message-oriented middleware |
Stream processing platform |
|
Message Storage |
In-memory (can persist to disk) |
Always on disk |
|
Message Retention |
Until acknowledged |
Policy-based (time/size) |
|
Message Routing |
Complex (multiple exchange types) |
Simple (topic-based) |
|
Delivery Mechanism |
Push to consumers |
Consumers pull |
|
Performance |
4K-10K messages per second |
1 million+ messages per second |
|
Ordering Guarantees |
Within a queue |
Within a partition |
|
Replication |
Queue mirroring |
Built-in partition replication |
|
Client Support |
Multiple protocols |
Kafka protocol |
|
Use Case Focus |
Complex routing, traditional messaging |
High-volume streaming, data pipelines |
-
Exchange Configuration
-
Choose the appropriate exchange type based on routing needs
-
Use direct exchanges for simple routing, topic exchanges for pattern-based routing
-
-
Queue Management
-
Set appropriate TTL (Time-To-Live) for messages
-
Configure queue length limits to prevent memory issues
-
-
Consumer Configuration
-
Set appropriate prefetch counts to balance throughput and load
-
Implement proper acknowledgment strategies
-
-
High Availability
-
Use mirrored queues for critical data
-
Configure proper synchronization policies
-
-
Topic and Partition Design
-
Size partitions appropriately for parallelism
-
Consider message key distribution to ensure balanced partitions
-
-
Producer Configuration
-
Enable batching for higher throughput
-
Configure appropriate acknowledgment levels based on reliability needs
-
-
Consumer Design
-
Implement idempotent consumers when possible
-
Carefully manage consumer offsets
-
-
Cluster Configuration
-
Set appropriate replication factor (typically 3)
-
Configure retention policies based on data needs
-
It's worth noting that new alternatives like Redpanda are emerging in the messaging space:
- Redpanda : A Kafka-compatible streaming platform written in C++ claiming superior performance through its thread-per-core architecture[12][13].
Recent benchmarks suggest: "Redpanda has been going to great lengths to explain that its performance is superior to Apache Kafka due to its thread-per-core architecture, use of C++, and its storage design that can push high performance NVMe drives to their limits"[13].
When choosing between RabbitMQ and Kafka, consider your specific use case requirements:
-
RabbitMQ excels at traditional messaging with complex routing patterns and lower throughput needs.
-
Kafka dominates in high-throughput event streaming scenarios requiring scalability and data retention.
Many organizations end up using both systems for their respective strengths[9]. Understanding the architectural differences and performance characteristics outlined above will help you make the right choice for your specific needs.
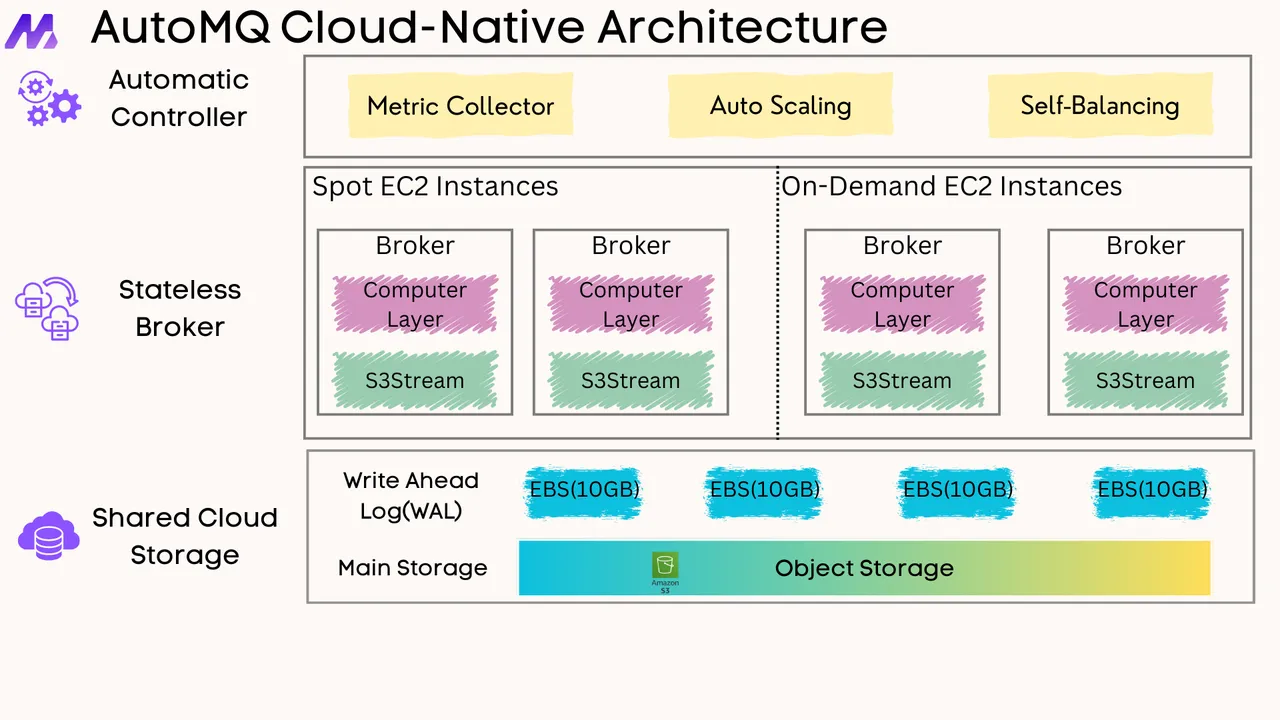
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging